





Julius
Members
-
Joined
-
Last visited
-
Thanks, the Libvrt Hotplug USB App worked for me.
-
I'd like access to a USB device from within a VM. Problem however is that it uses the same Group as the UnRaid USB stick; Group 4 00:14.08086:a36dUSB controller: Intel Corporation Cannon Lake PCH USB 3.1 xHCI Host Controller (rev 10) USB devices attached to this controller: Bus 001 Device 004: ID 051d:0002 American Power Conversion Uninterruptible Power Supply Bus 001 Device 003: ID 0781:5567 SanDisk Corp. Cruzer Blade Bus 001 Device 002: ID 289b:0505 Dracal/Raphnet technologies Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub USB Device 002 needs to be passed through. Why is this so hard to share with a VM in 2020 ?
-
The Fix Common Problems script is telling me my ca mover tuning plugin is deprecated, then links to an update fork for me, but there's no url or anything to install it there. Oh, apparently 'Apps' are now the same as 'Plugins' ? Why the different tabs in the menu then?
-
There is no "Custom: br0" under my docker Network type options. Already gave it its own IP (as I clearly wrote), still it fails saying its IP is 0.0.0.0, which it is not. I switched off docker support for my unraid entirely. Back to using VMs for all, much easier to maintain, to secure (csf/lfd firewall), no strange translations, soft-linking or proxying, and I found a very good config for pihole using a nginx server.conf with php-fpm here.
-
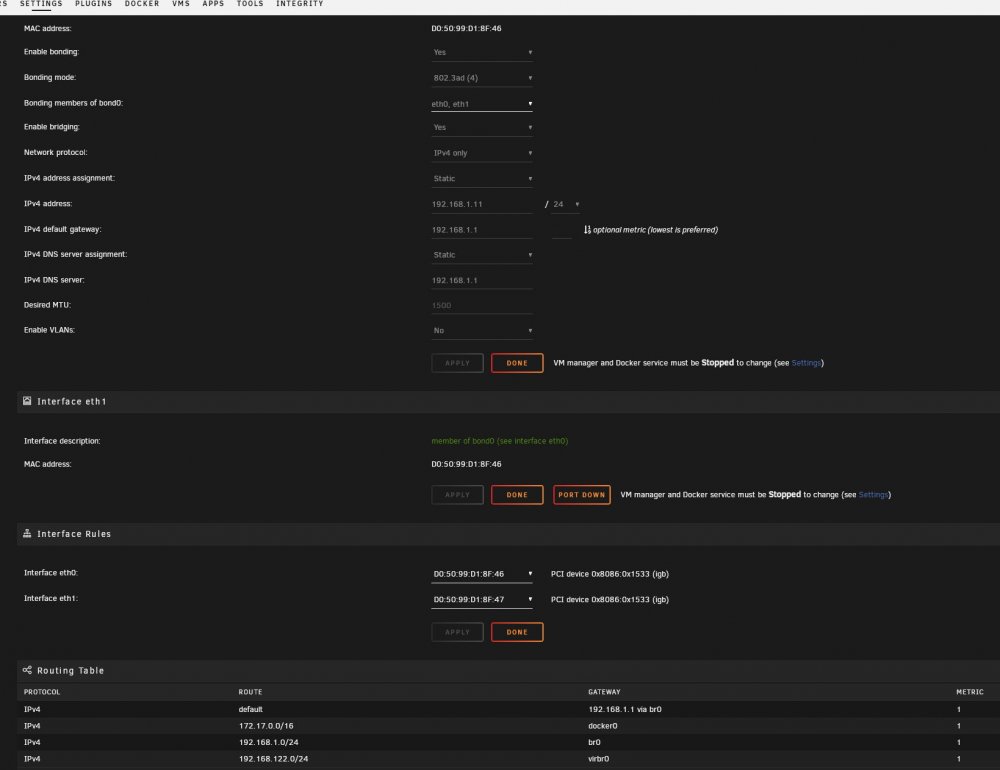
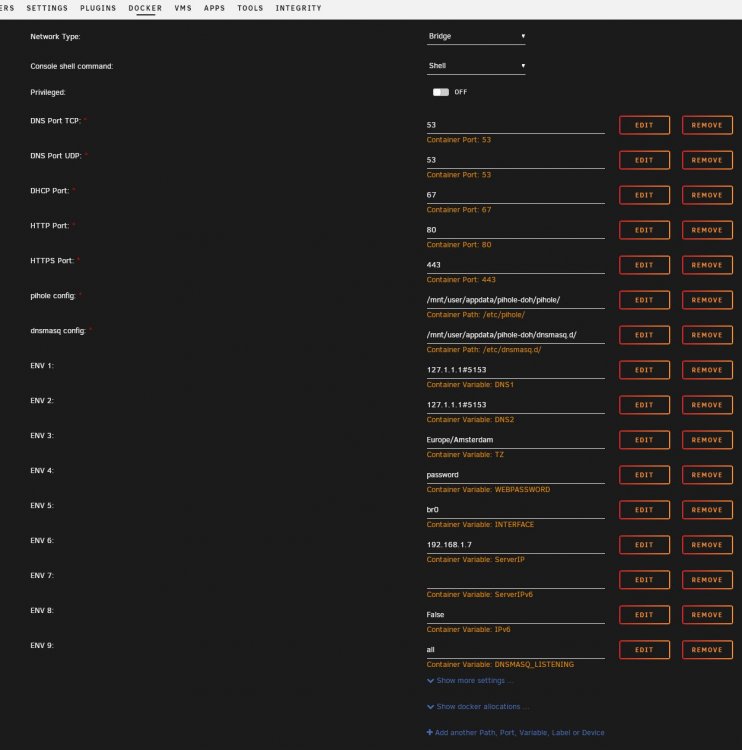
Already tried both options, and more. It doesn't work. Unraid runs on 2 interfaces (eth0 and eth1, as bond0) with 192.168.1.11, I've set the docker to use a free IP 192.168.1.7, but even when I set it to use the same IP and different ports (81 and 445 for example), there's no pihole web-ui running. The docker keeps failing to start, and when it does start it says it's using 192.168.1.11, which I did not set. Attached are the network config and docker config. (Good grief, what do people see in those docker containers? It's a complete flaky network-mess, full of translations, redirections and proxies, adding latency and complexity. And extra webservers running just for one app. I keep saying it; VM's are more efficient, easier to maintain and easier to make accessible. But much to my surprise, pi-hole doesn't even properly support being installed on Debian 10, with the shipped php-fpm and nginx, otherwise I already would have done that in the VM's I run on this unraid server.
-
For me there's never a br0, and I have not set anything aside from defaults. Also, /var/lib/docker/network/files/local-kv.db does not exist on an up to date unraid server. The networking stack is still very flaky in unraid. If I change the docker settings for networking, it can entirely hang the server and make it inaccessible. While all I have here are 2 NICs connected with a bond, so that speed is faster to/from the server. Other than that nothing deviates from the default.
-
root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='pihole-with-doh' --net='bridge' -e TZ="Europe/Berlin" -e HOST_OS="Unraid" -e 'DNS1'='127.1.1.1#5153' -e 'DNS2'='127.1.1.1#5153' -e 'TZ'='Europe/Amsterdam' -e 'WEBPASSWORD'='password' -e 'INTERFACE'='br0' -e 'ServerIP'='192.168.1.7' -e 'ServerIPv6'='' -e 'IPv6'='False' -e 'DNSMASQ_LISTENING'='all' -p '53:53/tcp' -p '53:53/udp' -p '67:67/udp' -p '80:80/tcp' -p '443:443/tcp' -v '/mnt/user/appdata/pihole-doh/pihole/':'/etc/pihole/':'rw' -v '/mnt/user/appdata/pihole-doh/dnsmasq.d/':'/etc/dnsmasq.d/':'rw' --cap-add=NET_ADMIN --restart=unless-stopped 'testdasi/pihole-with-doh' 39f5fd7455f1fa5dfed989b1cefa10fdebea845722d37b2dc8861afc9b8c0203 /usr/bin/docker: Error response from daemon: driver failed programming external connectivity on endpoint pihole-with-doh (ec98edf36e66ae40c9ead8078e625cbcc65563379fd10c2073956e49ac008095): Error starting userland proxy: listen tcp 0.0.0.0:443: bind: address already in use. The command failed. Whatever I do, I can't seem to get it running.
-
Oh I wasn't even checking. I thought it did use apache, since I saw that being mentioned somewhere. I'll edit my post, because that part was irrelevant anyway. It's not the apache vs nginx that makes the VM better (for me).
-
I've tested these two options; 1) this Piwigo docker, accessing a separated mariadb instance. Rather complex and slow loading large amounts of images. 2) Piwigo, mariadb, nginx, php-fpm and CSF, all on 1 debian minimal VM. Both instances of piwigo access the exact same folders from an unraid share with terabytes of imagefiles. The second option performs noticeably faster, even without doing proper IO tests etc. The difference is so obvious, that I'm not even going to bother testing it with tools. Could be because I run unraid with a decent Xeon and 32GB RAM, but still; I don't see any advantage over docker instances for piwigo, and I just wanted to share that, because frankly, setting up piwigo in that VM was so much easier, other than maybe using a little fewer resources I don't understand what all the fuss on having it as a docker instance is about. The SSL/TLS cert for NGINX is located in an Unraid Share with Unraid Mount tag in the VM. Same LetsEncrypt wildcard cert I use for the unraid UI. So no weird proxying or network complexities. Plus, a csf/lfd firewall in front of the piwigo server VM, allowing me to serve the stuff through my internet-router to the world.
-
No end in sight. I have no idea why. In the bottom left corner it says; "Array Stopping•Retry unmounting user share(s)..." Nothing is connected to it, except that one browser tab. This is super time-wasting. I try to change config, adding a disk etc. Only way to get there is by powering down and immediately pressing to stop the array when it starts.
-
Does the 'At startup of Array' run before or after the go script? Does the 'At startup of Array' execute before or after ssh service daemon starts? Is there a chart somewhere showing the runtime levels (or order) per plugin or service?
-
Assuming you use that Xeon from your signature (which is the exact same one I have in my unraid server, E2136), did you measure a change in some way, and if so, which/what/how? I copied these settings for my syslinux as well, and at least the VM performance seems snappier but that could be placebo..
-
I agree, this plugin has a tendency to mess up your sshd_config entirely in no time. I would not recommend using it. Just one reboot and you'll know why; It locked me out many times, not because of the banning, but because it ruined ssh config. Had to go manually fix it with KVM access to the unRAID server. And then, looking at sshd_config showed all kinds of double entries. It's better to populate the go script with copy commands and just create and maintain your own ssh config.
-
Julius changed their profile photo
-
Hey SpaceInvader, Great work, but can I still run everything of the pi-hole on its own LAN IP, like I used to? (so no port-change required) The option seems to have disappeared, and my pihole stopped running! And yes, this meant I had DNS resolving in unRAID point to the pihole IP, which is a different one from the unRAID IP. TIA! Never mind the above, I decided to drop pi-hole entirely and use Diversion on my ASUS RX router with Merlin firmware. Better to block stuff closer to the door: https://diversion.ch/diversion/use/theme-colors.html



