




Giggity_Grant
Members
-
Joined
-
Last visited
Everything posted by Giggity_Grant
-
@fatgeek I also ran into this exact same issue. Reverting back to binhex/arch-sabnzbdvpn:3.5.3-1-03 also fixed it for me. No clue what the issue might be, but I thought I'd let you know you're not the only one having these symptoms
-
Has anyone been able to host a mac photo library on their UnRaid server with good stability? My fiance would like to get rid of her macbook, and just move to a tablet for everyday use. She will still need to backup her iPhone photos, and if possible, would like to still use the mac Photos system. I don't have a ton of space on my Macbook's SSD, so I would like to avoid backing up her photos to my Macbook. In an ideal world, we would both want to host separate photo libraries on the UnRaid server, with an external HDD backup and cloud backup. I migrated my macbook photo library to a user share as an experiment a few months ago. While I was able to migrate the library to the UnRaid server and get my Mac to recognize the library file via SMB, I was never able to import photos from my iPhone to the server library via my Mac. I've read some posts on the forums which mention possible file system incompatibilities which could lead to corruption of the library, which is a concern. I'm not sure if this is a true issue or what the solution might be. I'm open to other ways of accomplishing to goal of course, but so far I've thought of two possibilities: Host Photo Library file on UnRaid server, then connect my macbook via SMB. As I mentioned, I tried this method before and had consistent issues importing photos to the Library from my iPhone via my macbook. Run an OSX VM on UnRaid which would host the Photos Library. The VM OS would be on cache, but would have an array usershare for storage (i.e. store library on array). Given that I would still be utilizing a usershare for Library file storage, would this present the same issues as option 1 or risk of file incompatibility/corruption? Would an unassigned drive (formatted in apple file system) need to passed through and used for file storage instead of using an array user share? Has anyone had any luck hosting their Mac Photo Library files with either of these methods, or any other method for that matter? Thank you in advance for your help!!!
-
@Squid I was the person having the issues with FCP in Safari via mobile. The problem is actually still occurring in both Safari and Chrome on iOS, but I just avoid FCP until I have access to a computer.
-
@Squid running FCP on chrome works just fine. It appears to just have issues with Safari in my instance.
-
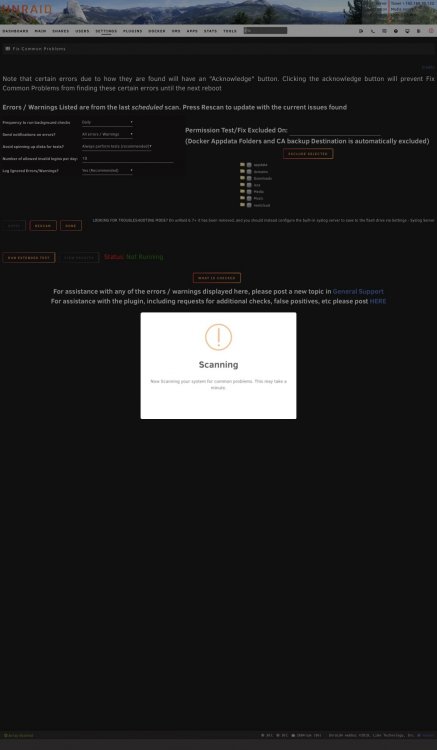
@Squid Just confirmed that I am running v2019.10.06 (see attached screenshot). Nothing has shown up under "...this may take a minute" on any of the attempts that I can recall. I just ran another attempt to verify, and I didn't see anything show up. I'm using Safari on iOS at the moment. I had to VPN into my network from my phone, since I can't do so from my work computer. I'll give Chrome and Firefox a shot when I get home later tonight.
-
Running Unraid 6.7.2. I had an issue with the hanging FCP scan screen a couple weeks ago that I was able to resolve. After updating FCP today, I am now getting the hanging screen error. The scan never completes, and the screen has not closed for over 30 min. I've tried multiple different attempts, uninstalling/reinstalling FCP, and rebooting Unraid. So far I haven't been able to find a solution to this issue. Here is a thread where I discuss what solved the issue last time.
-
When testing my https://subdomain.duckdns.org, it just redirects me to google homepage. Is anyone else having this issue? Followed the steps through until the final nextcloud steps, since I figured out that neither my generic subdomain nor sonarr subdomain were functioning properly.

