





Tzundoku
Members
-
Joined
-
Last visited
Everything posted by Tzundoku
-
Eventually figured this out, posting for posterity: Had already tried booting in safe mode, disabling docker, VM services, no luck. I randomly visited the unraid ui via my android phone and the pages were snappy, so issue was probably related to the laptop. I noticed I had an old (~2023) installation of Sophos AV that didn't fully uninstall in the past and parts of its leftovers were related to network services. I attempted removing everything related via regedit, disabling the services, no luck, so I eventually booted through a Windows installation USB and disabled the relevant services via the recovery environment, booted to Windows, ran their official uninstallation tool and after a restart page loading times (Unraid) were fixed.
-
Hello! Takes more than 15 seconds for containers to show and more than 30 seconds for the dashboard to load. This is through LAN IP access. Went through the forums for similar issues, tried some suggestions (removing a couple of plugins, assigning cloudflare instead of pihole for DNS) with no luck. It's been like this since I can remember (i.e. its not related to any update I've applied lately). Applies to all browsers and devices within the network. Can't quite pinpoint whether the issue is related to Unraids settings or my homenetwork. Appreciate any thoughts on troubleshooting :) tower-diagnostics-20241208-2014.zip
-
Updating- issue is back since yesterday unfortunately.
-
Swapped drives and at the same day the latest stable release dropped so I went with the update as well- no issues so far so either could be the fix. Thanks for your time!
-
Any chance the issue could be related to something else? I.e. the mobo? I was using a Samsung 870 evo with months of uptime prior to replacing it with the one that is currently going offline. A month or so ago that drive started displaying similar I/O errors whenever I initialized a windows vm (vfio binded ssd which was working fine until last month as well). Thought the 870 evo cache had the issue, hence the replacement.
-
Should I post diagnostics immediately after powercycling or is the above adequate? Thanks tower-diagnostics-20240325-1636.zip
-
Thanks for the prompt reply JorgeB. I powercycled as directed but also included the following lines to the syslinux config after going through a couple of other posts: nvme_core.default_ps_max_latency_us=0 pcie_aspm=off Initially everything was working fine, then while watching a movie through Jellyfin shares went out again. Diagnostics taken immediately after. tower-diagnostics-20240325-1615.zip
-
Hello! I attempted to access some docker services today and realized that the cache drive was "out". The device appears as "Active, normal operation" but there's several errors in its log and most shares are missing. After a clean reboot there was a notification that an unclean shutdown was detected and currently there's a parity check running. Shares are still missing after the reboot. The cache drive is new (~10 days) and was operating with no issues for the past week. Here's the cache drive log: Mar 24 15:56:05 Tower kernel: nvme0n1: p1 Mar 24 15:57:28 Tower emhttpd: Samsung_SSD_990_PRO_with_Heatsink_1TB_S73JNJ0W605701A (nvme0n1) 512 1953525168 Mar 24 15:57:28 Tower emhttpd: import 30 cache device: (nvme0n1) Samsung_SSD_990_PRO_with_Heatsink_1TB_S73JNJ0W605701A Mar 24 15:57:32 Tower emhttpd: read SMART /dev/nvme0n1 Mar 24 15:57:47 Tower emhttpd: shcmd (57): mount -t xfs -o noatime,nouuid /dev/nvme0n1p1 /mnt/cache Mar 24 15:57:47 Tower kernel: XFS (nvme0n1p1): Mounting V5 Filesystem Mar 24 15:57:48 Tower kernel: XFS (nvme0n1p1): Starting recovery (logdev: internal) Mar 24 15:57:48 Tower kernel: XFS (nvme0n1p1): Ending recovery (logdev: internal) Mar 24 16:01:55 Tower kernel: nvme0n1: I/O Cmd(0x2) @ LBA 516769048, 8 blocks, I/O Error (sct 0x3 / sc 0x71) Mar 24 16:01:55 Tower kernel: I/O error, dev nvme0n1, sector 516769048 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 2 Mar 24 16:01:55 Tower kernel: nvme0n1: detected capacity change from 1953525168 to 0 Mar 24 16:01:55 Tower kernel: nvme0n1p1: writeback error on inode 1086305362, offset 1630208, sector 989418728 Mar 24 16:01:55 Tower kernel: nvme0n1p1: writeback error on inode 1076556609, offset 0, sector 979578768 Mar 24 16:01:55 Tower kernel: XFS (nvme0n1p1): log I/O error -5 Mar 24 16:01:55 Tower kernel: XFS (nvme0n1p1): Filesystem has been shut down due to log error (0x2). Mar 24 16:01:55 Tower kernel: XFS (nvme0n1p1): Please unmount the filesystem and rectify the problem(s). Mar 24 16:01:55 Tower kernel: XFS (nvme0n1p1): metadata I/O error in "xfs_imap_to_bp+0x50/0x70 [xfs]" at daddr 0x587d2230 len 32 error 5 Mar 24 16:01:55 Tower kernel: nvme0n1p1: writeback error on inode 555942864, offset 0, sector 507454752 Mar 24 16:01:55 Tower kernel: nvme0n1p1: writeback error on inode 536871051, offset 73728, sector 498262064 Mar 24 16:01:55 Tower kernel: nvme0n1p1: writeback error on inode 556136556, offset 86016, sector 507648792 Mar 24 16:01:55 Tower kernel: nvme0n1p1: writeback error on inode 1076717193, offset 0, sector 979739088 Mar 24 16:01:55 Tower kernel: nvme0n1p1: writeback error on inode 536871051, offset 77824, sector 498262072 Mar 24 16:01:55 Tower kernel: nvme0n1p1: writeback error on inode 1626563962, offset 4128768, sector 1508843144 Any ideas? Thanks! tower-diagnostics-20240324-1802.zip
-
Static IP was already set on the mikrotik router, went and configured it within Unraids network settings as well and then rebooted the router- issue is still there. Attempted to connect via tailscale (plugin) IP, no luck either, had to force reboot.
-
As the title suggests, I'm losing access to Unraid (unable to ping through router or other LAN devices) if I update/powercycle my router or whenever there is a power outage. I believe its a NIC issue as if I have my Windows VM on at the time (which has a dedicated usb network adapter and a bridged IP from Unraids NIC) the usb adapter (192.168.88.8) retains internet/LAN access while the Virtio interface (192.168.88.7) is down. The issue resolves if I powercycle the server- no luck if I attempt to disable and then re-enable the network port on my (mikrotik) router. Diagnostics and syslog (post-powercycle) are attached. Let me know if there's any other info I can provide. Appreciate your time! tower-diagnostics-20230817-1154.zip tower-syslog-20230817-0858.zip
-
Welp, phone upload didn't go through, thanks.
-
As the title suggests, my server hangs (UI and services are completely inaccessible) at random, but usually around array starting. I worked around this in the past by manually starting the array with parity check/docker/vms disabled at first but thats irrelevant since 6.10.3 as it hangs at random. Diagnostics attached, let me know if there's any other info I may provide. Thanks! tower-diagnostics-20220620-1441.zip
-
Thanks for the reply Squid. I managed to run this .xml template (ignore the description) according to the repositories dockerfile. Only difference is I assigned (P)UID to 99 and (P)GID to 100 instead of the 1337 shown in the dockerfile, if that's relevant. WebUI remains inaccessible. Also added a "WebUI" port to the template pointing to 29316. I'm unsure if I'm currently supposed to configure the .xml according to the example-config.yaml, and which of the parameters are supposed to be configured as environmental variables, volumes, or paths. Thoughts?
-
Apologies if this is the wrong place to ask this. This is my first attempt at porting a container/creating a template. I'm trying to host a matrix.org bot deployer (maubot) which isn't available as an Unraid template or on Dockerhub, however the docker image can be pulled from gitlab as per the instructions. I had success ("startup actions complete, running forever") with pulling and running the container, updating the .yaml configuration (most probably in an inappropriate manner) and assigning a couple of variables (volume, network..) through portainer (first attempt at learning how to use it). The container runs and can ping/get pinged by other containers on its network, yet when attempting to access the webui as per the instructions I'm unable to connect. I'm currently looking into creating an appropriate template for the container so I can easily edit/play around with the variables. However.. I have no idea what the required environmental variables are and I haven't figured out a way to look them up through the gitlab container link mentioned previously. Edit: I'm guessing the required variables are located in the example-config.yaml. I converted the .yaml to .xml but I'm currently unsure on how to map the variables into the Unraid template/xml. So... any ideas? Thanks for your time!
-
I thought I had to! I have my ip proxied through cloudflare, unsure if that counts. I just tried adding a CNAME that points valheim.mydomain.com to mydomain.duckns.com, doesn't seem to work though. Just tried accessing through IP and that didn't work either though, so my issue is probably related to my mikrotik router settings not playing well with the containers' fixed IP assigned through unraid (although I can ping the container, its not showing up on my routers IP leases so possible issue there with forwarding traffic). Thanks for the reply!
-
Hey, thanks for this! I'm having moments of brain lags and can't think through on how to properly configure subdomain redirection on a dynamic IP using cloudflare and duckdns. I'm supposed to add an A record in cloudflare which redirects valheim.mydomain.com to my external IP. Not sure how to properly configure this so it follows duckns?
-
-
Hi there! I'd like to request some assistance on troubleshooting a weird phenomenon I'm experiencing while connecting to the VM via Splashtop. Tried googling but didn't manage to find anything relevant so far. So I'm running the latest Unraid image on an R710 server with RX580 GPU passthrough and 6 vCPU / 8GB RAM assigned to the VM. The server is headless, so I log to unraid via webGUI and use Splashtop to access the macOS Catalina VM. Whenever I move the mouse all CPU cores spike to 100% usage and the cursor appears to "lag behind". At the same time, I'm using Horos (projecthoros.org) to view medical images which can be pretty demanding depending on the database size, and vCPU usage appears to stay around 50-70% during initial database processing (as long as I'm not moving the mouse). So yeah, any ideas? Thanks!
-
Hey there, thanks for the great work. Any way I can configure the search engine options? I.e. remove the ones I never use and add "custom" ones from specific sites I search through often?
-
Hello! I keep running into the following error when attempting to connect Mylar to Deluge: [Deluge] Could not establish connection to 192.168.0.1:58846. Error returned: Password does not match, localclient Traceback (most recent call last): File "/usr/lib/python3.8/site-packages/deluge/core/rpcserver.py", line 267, in dispatch ret = component.get('AuthManager').authorize(*args, **kwargs) File "/usr/lib/python3.8/site-packages/deluge/core/authmanager.py", line 125, in authorize raise BadLoginError('Password does not match', username) deluge.error.BadLoginError: Password does not match I attempted to add the Deluge user "mylar:mylar:5" to /mnt/user/appdata/deluge -> auth but the username is not recognized as existing, I attempted to use the username "localclient" as it appears in the auth file and it is recognized as valid but I'm unable to get the password right: tried the dockers' default, tried copy-pasting the one shown in the auth file, and tried replacing the one shown in the auth file with no luck. Thanks for your time.
-
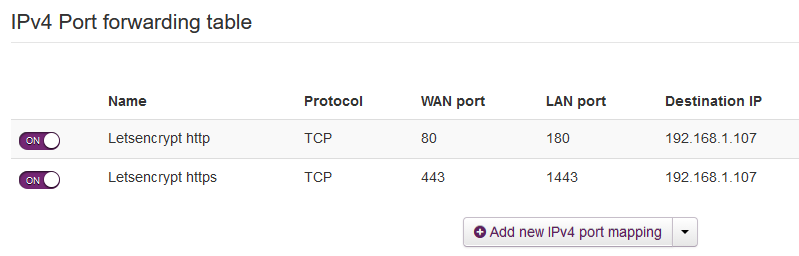
Changed settings as shown in the image and followed the linked guide, letsencrypt still comes up with: Challenge failed for domain .myserver.com Type: Unauthorized "To fix these errors, please make sure that your domain name was entered correctly and the DNS A/AAAA record(s) for that domain contain(s) the right IP address." Checked. When trying to access nginx from outside the network according to the guide (i.e. nextcloud.myserver.com) a page comes up along the lines of "this page is under construction". Also, when attempting to port check ports 80, 180, 443, 1443, the connection is refused on 80/443 and timed out on 180/1443. Thoughts?
.thumb.png.3dff82fab6d19b12c38556fc3e271d9c.png)
-
Hello there. Unsure if this is the most appropriate place to ask but I guess it's worth a try. I keep getting "Challenge failed for domain.." in the initial setup validation and I suspect I'm messing up with the port-forwarding somewhere along my network. -Following SpaceInvaderOnes' guide on Letsencrypt I have http pointing to 180 and https to 1443. -I have an "obligatory" modem provided by my ISP (Technicolor TG789vac v2) which does not allow/provide an option to switch to bridge mode due to some kind of conflict with VoIP. My port settings are visible in image 1. -I have a Mikrotik hEX PoE Routerboard with port settings visible in image 2, or as follows: /ip firewall nat add action=dst-nat chain=dstnat comment=Letsencrypt dst-port=80 dst-address=!192.168.88.1 protocol=tcp dst-address-type=local to-addresses=192.168.88.88 to-ports=180 add action=dst-nat chain=dstnat comment=Letsencrypt dst-port=443 dst-address=!192.168.88.1 protocol=tcp dst-address-type=local to-addresses=192.168.88.88 to-ports=1443 /ip firewall nat add action=masquerade chain=srcnat comment=Letsencrypt dst-port=180,1443 dst-address=192.168.88.88 protocol=tcp Where 192.168.88.1 points to the Mikrotik router and 192.168.88.88 points to Unraid. Any ideas on where I might be messing up? Please ask if additional info might be required. Appreciate your time and effort.



.png.1dc14dd8a5c102c0ea2914958bffc67e.png)

