JT Marshall
Members
-
Joined
-
Last visited
Everything posted by JT Marshall
-
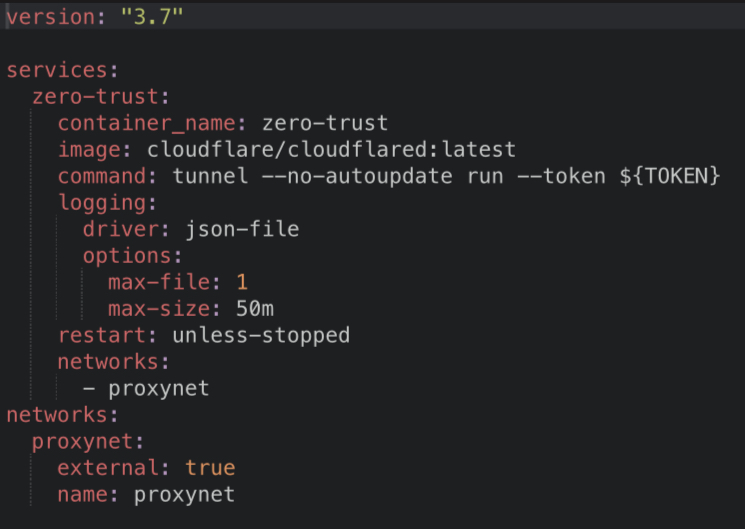
That’s a work around that I’ve used before. I prefer using docker compose due to its portability but that’s a totally viable alternative.
-
Sure didn’t. It’s not a deal breaker, just makes the ui look weird. It only stresses me out when I’m checking in on a docker issue so I haven’t spent too much time on it.
-
I’m having the same issue.

-
Okay, parity check completed and I assume corrected the 9 errors, but that disk1 (sdo) has me worried. I definitely think I should replace it. bifrost-diagnostics-20230311-1317.zip
-
I added "1,200" raw read error rate and raw write error rate to my SMART attribute notifications per something I read on here. During my parity check I'm now getting read error rate warnings for (sdo). First rate was 327,693 and then 30 minutes later 3,473,409. I'm not entirely sure I know what that means but it doesn't seem good to be an order of magnitude higher 30 minutes later.
-
Okay, that's a relief. I'll mark this solved once the corrected parity is complete.
-
Been using Unraid for a few years now and this is my first batch of parity errors. During my monthly non-corrected parity check I got 9 errors, I immediately repeated the non-corrected parity check and got the same 9 errors. I've looked and the diagnostics but honestly I don't know what I'm looking for and how to proceed. I'm hoping someone on here can give me some guidance. Thanks! bifrost-diagnostics-20230310-0944.zip
-
I finally bit the bullet and made one for myself. Here is my version.


-
Much appreciated! I have it installed and I’m excited about never seeing parity during the day again!
-
That’s too bad. That feature was part of the reason I was excited about 6.10. I didn’t know about Parity Check Tuning so I’ll give that a try.
-
This is perfect. Thanks for the recommendation.
-
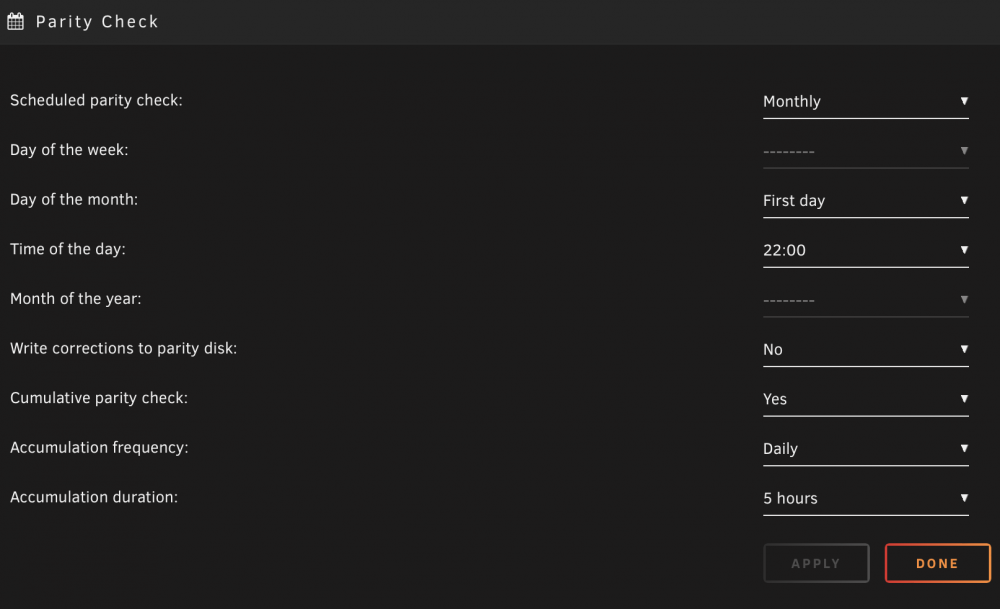
Well another month has gone by and my parity still is not running incrementally. Once parity starts it continues to go until completion. What am I doing wrong? I feel like this should start a parity check at 10pm on the first day of the month, run for 5 hours pause and do it again the next day. Repeat until complete. Am I misunderstanding this?
-
Discrepancy noted, and corrected. 😉
-
I recently changed my Parity Schedule to run under custom conditions. I wanted it to run every other month on the first Saturday of the month and only to run for 5 hours a day until parity is complete. Here is how I set it: Scheduled parity check: Custom Day of the week: Saturday Week of the Month: First week Time of the day: 00:00 Month of the year: January, March, May, July, September, November Write corrections to parity: Yes Cumulative parity check: Yes Accumulation frequency: Daily Accumulation duration: 5 hours Today is the first day for the run and as of 10:55 my scheduled parity is still running. My understanding was that my parity would pause at 05:00 and resume daily until parity is complete. Are my assumptions incorrect or is this a bug buried in the custom schedule? In the interim I will switch my schedule to monthly and see if that works. Thoughts?
-
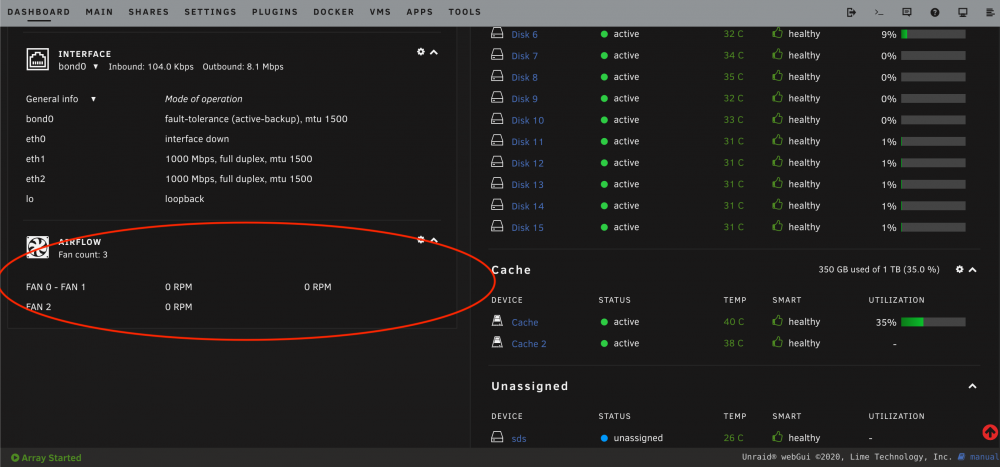
I looked in my /boot folder with find -iname "sensors.conf" -exec echo {} \; and found nothing. /boot/config/plugins doesn't have a dynamix.system.temp folder, I believe because I removed that plugin as well. I checked in /etc and found a sensors.conf in /etc/sensors.d/ and removed that, rebooted and now I have no Airflow! THANKS! Your guidance was helpful.
-
Just tried that, it still persists even in private browsing mode.
-
Yes, I've uninstalled and rebooted.
-
So, I added the Dynamix System Autofan plugin which added the Airflow section to my Dashboard. Ultimately the plugin didn't work out for me so I removed it. Now I have the Airflow section orphaned on my Dashboard. How do I go about removing the Airflow?