




Geoff Bland
Members
-
Joined
-
Last visited
-
You were correct. I triple checked this time and now all the disks had blue icons and I was able to correctly configure the array. Started and rebuilding parity now.
-
Yes - I did this. Made sure I selected "Retain All" and made doubly sure I pressed Apply and then Done. Should I be selecting "None" in New Config instead of "Retain all" ?
-
OK I tried this and it did not work. On step 5 of the above I am unable to move the disks around. If I move the next disk into the unassigned slot where the failed disk was and move all the following disks up one then I am unable to start the Array - "Invalid Configuration" and all but the next disk shows a red x and complains about "Missing" disk. If I move the last disk into the unassigned slot where the failed disk was leaving the other disks as they are then I am unable to start the Array - "Invalid Configuration" and the last (now empty) slot shows a red x and complains about "Missing" disk. What am I doing wrong?

-
Thanks for the response. So: Move all files off emulated disk onto another disk (using Unbalanced). Check and double check nothing remains on the emulated disk. Stop array Set new config - using Tools | New Config Remove unassigned failed disk and move all disks after this “up one” in the array list of disks. Restart array ensuring with parity rebuilt Is this correct?
-
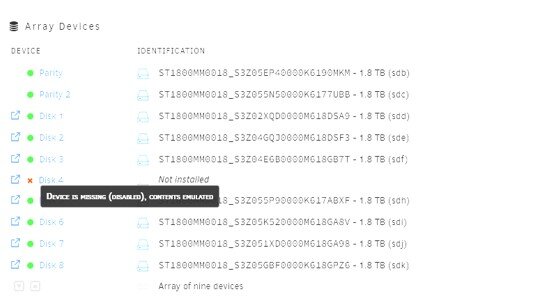
I have a failed disk in my array. I have plenty of free space in my array so I thought just to remove this disk. I followed the instructions at https://docs.unraid.net/unraid-os/manual/storage-management/ and https://docs.unraid.net/unraid-os/manual/storage-management/#reset-the-array-configuration to set the failed disk as unassigned. The failed disk now shows up in unassigned devices. But I thought this will rebuild the array from parity – but it appears to have done nothing and the missing disk just shows as “Not Installed” with the hint “Device is missing (disabled). Contents emulated”. To fix this I am planning on doing the following: 1. Move all files off emulated disk onto another disk (using Unbalanced). 2. Check and double check nothing remains on the emulated disk. 3. Stop array 4. Remove unassigned failed disk and move all disks after this “up one” in the array list of disks. 5. Restart array without parity rebuild Am I correct in thinking this will work?

-
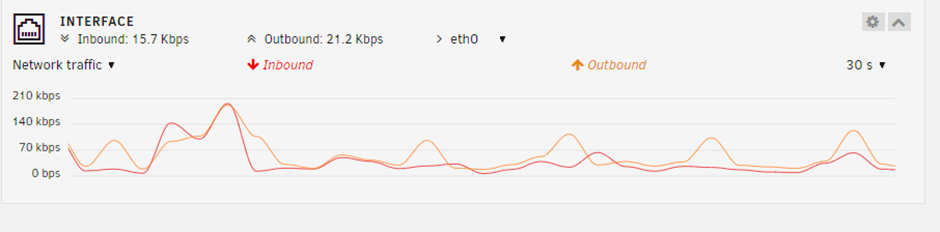
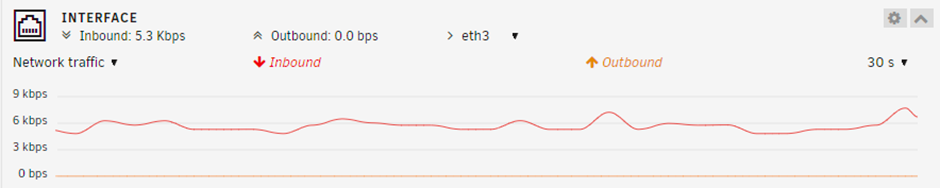
I have just added a new 10GB network card to my Unraid server (previously it had 2 1GB NICs) and have seen Unraid pick it up straight away and add it into the bond. Seems to be working fine. However, I am questioning if I have this set up in the most optimal way. I currently have no other servers with a 10GB NIC but will have this soon and will then be able to test so this post is just to gather some thoughts and information from people that have experience with this just to check my own understanding. I also plan to remove the 2nd 1GB NIC now I have the 10GB NIC working. I have set binding mode set as “active-backup (1)” and all 3 NIC are seen in the bond; eth0, eth1 and eth3 (being 1GB, 1GB and 10GB NICs respectively. With “active-backup” mode I would have expected one NIC to be used exclusively and a second NIC only to be used if the first failed. But what I’m seeing is the first old 1GB NIC being used most and the new 10GB NIC being used a little, so that is unexpected. The second 1GB NIC (eth1) is on a "private" test LAN so there's no traffic on that. Is this because everything connecting to the Unraid server is currently doing so only at 1GB? Ideally, I assume I would like the 10GB interface to be used for most things and the 1GB interface only to be used as a backup? Is my assumption correct and how do I set this in Unraid.

-
I've been using this simple yet very useful app for many years now. I'm just reinstalling it on a new UNRAID server but when I click "Install" from the UNRAID Apps the UNRAID web page stalls, the UNRAID "busy" animation is shown and the "Add Container" settings page is never shown. I can see anything in the log files showing any error. I have tried restarting docker and the UNRAID server this did not help. Other docker apps are not affected and bring up their "Add Container" settings pages with no problem. Edit: I was able to install the S3Backup container manually by using the Add Container option on the Docker page.
-
I just tried this on a 4K screen. It only seems to split into 3 columns when the browser width is 2000px, this seems a bit excessive as there's plenty of space for 3 columns at narrower browser widths. Compared with Unraid 6.11.5 the browser display has to be quite a bit wider before it displays 3 columns. Font size set to normal in Display Settings in both cases. Setting Font size Small in Display Settings makes no difference.
-
On the Shares page it is difficult to see at a glance what the initial and preferred/moved storage options are. That is it is difficult to see the difference between "Cache ---> Array" and "Cache <--- Array". Whilst maybe this current ordering is trying to show the primary and secondary storage, we know the Cache must always be the primary storage so this ordering does not help. It would be more obvious if instead the column showed either "Cache ---> Array" or "Array ---> Cache". This way also matches the mover selection when a Share is created/edited.
-
I have started getting delays with Unraid file shares when doing any operation (viewing files in directoires, file copies etc) with Windows, this did work fine but has started happening over the last several weeks. I am also seeing associated errors in the UNRAID logs. For example, from my windows PC if I open a new directory in Windows File Explorer, then File Explorer freezes for several minutes, then I see a warning in the UNRAID logs and then immediately Windows File Explorer comes back to life and shows the directory contents. The log errors are all of the form (when viewing a share) : May 6 12:53:55 UNRAID smbd[31869]: [2023/05/06 12:53:55.447545, 0] ../../source3/smbd/files.c:1199(synthetic_pathref) May 6 12:53:55 UNRAID smbd[31869]: synthetic_pathref: opening [Share/[email protected]/Share/Data/C/Users/Username/AppData/Local/Google/Chrome/User Data/Default/Cache/Cache_Data/f_05a0b8 (2023_05_06 04_52_58 UTC)] failed or (when copying up an iso) May 6 12:47:28 UNRAID smbd[31869]: [2023/05/06 12:47:28.820231, 0] ../../source3/smbd/files.c:1199(synthetic_pathref) May 6 12:47:28 UNRAID smbd[31869]: synthetic_pathref: opening [Operating Systems/Ubuntu/ubuntu-23.04-desktop-amd64 (1).iso] failed If I reboot the UNRAID server then it starts working fine for a few hours and then the freezes and log errors start up again. Restarting samba with /etc/rc.d/rc.samba restart shows the following error in the logs May 6 12:57:37 UNRAID02 smbd[31869]: [2023/05/06 12:57:37.828986, 0] ../../lib/util/fault.c:184(smb_panic_log) May 6 12:57:37 UNRAID02 smbd[31869]: PANIC (pid 31869): assert failed: (fh->fd == -1) || (fh->fd == AT_FDCWD) in 4.17.3 May 6 12:57:37 UNRAID02 smbd[31869]: [2023/05/06 12:57:37.829787, 0] ../../lib/util/fault.c:292(log_stack_trace) May 6 12:57:37 UNRAID02 smbd[31869]: BACKTRACE: 39 stack frames: May 6 12:57:37 UNRAID02 smbd[31869]: #0 /usr/lib64/libgenrand-samba4.so(log_stack_trace+0x2e) [0x149415d7664e] May 6 12:57:37 UNRAID02 smbd[31869]: #1 /usr/lib64/libgenrand-samba4.so(smb_panic+0x9) [0x149415d768a9] May 6 12:57:37 UNRAID02 smbd[31869]: #2 /usr/lib64/libsmbd-base-samba4.so(+0x4d10b) [0x14941615710b] May 6 12:57:37 UNRAID02 smbd[31869]: #3 /usr/lib64/libtalloc.so.2(+0x44df) [0x149415d264df] May 6 12:57:37 UNRAID02 smbd[31869]: #4 /usr/lib64/libsmbd-base-samba4.so(file_free+0xd6) [0x1494161642e6] May 6 12:57:37 UNRAID02 smbd[31869]: #5 /usr/lib64/libsmbd-base-samba4.so(close_file_free+0x29) [0x149416194d49] May 6 12:57:37 UNRAID02 smbd[31869]: #6 /usr/lib64/libsmbd-base-samba4.so(+0x5d046) [0x149416167046] May 6 12:57:37 UNRAID02 smbd[31869]: #7 /usr/lib64/libsmbd-base-samba4.so(+0x5d1ce) [0x1494161671ce] May 6 12:57:37 UNRAID02 smbd[31869]: #8 /usr/lib64/libsmbd-base-samba4.so(files_forall+0x19) [0x149416163119] May 6 12:57:37 UNRAID02 smbd[31869]: #9 /usr/lib64/libsmbd-base-samba4.so(file_close_user+0x3d) [0x14941616325d] May 6 12:57:37 UNRAID02 smbd[31869]: #10 /usr/lib64/libsmbd-base-samba4.so(smbXsrv_session_logoff+0x4d) [0x1494161e000d] May 6 12:57:37 UNRAID02 smbd[31869]: #11 /usr/lib64/libsmbd-base-samba4.so(+0xd6445) [0x1494161e0445] May 6 12:57:37 UNRAID02 smbd[31869]: #12 /usr/lib64/libdbwrap-samba4.so(+0x5d18) [0x149415a59d18] May 6 12:57:37 UNRAID02 smbd[31869]: #13 /usr/lib64/libdbwrap-samba4.so(+0x5f3a) [0x149415a59f3a] May 6 12:57:37 UNRAID02 smbd[31869]: #14 /usr/lib64/libdbwrap-samba4.so(dbwrap_traverse+0x7) [0x149415a57f67] May 6 12:57:37 UNRAID02 smbd[31869]: #15 /usr/lib64/libsmbd-base-samba4.so(smbXsrv_session_logoff_all+0x5b) [0x1494161e07fb] May 6 12:57:37 UNRAID02 smbd[31869]: #16 /usr/lib64/libsmbd-base-samba4.so(+0xdca0b) [0x1494161e6a0b] May 6 12:57:37 UNRAID02 smbd[31869]: #17 /usr/lib64/libsmbd-base-samba4.so(smbd_reinit_after_fork+0) [0x1494161e6ff0] May 6 12:57:37 UNRAID02 smbd[31869]: #18 /usr/lib64/libsmbd-shim-samba4.so(exit_server_cleanly+0x14) [0x149415d7b284] May 6 12:57:37 UNRAID02 smbd[31869]: #19 /usr/lib64/libsmbd-base-samba4.so(+0xa08e2) [0x1494161aa8e2] May 6 12:57:37 UNRAID02 smbd[31869]: #20 /usr/lib64/libtevent.so.0(tevent_common_invoke_signal_handler+0xa6) [0x149415d3d936] May 6 12:57:37 UNRAID02 smbd[31869]: #21 /usr/lib64/libtevent.so.0(tevent_common_check_signal+0xc3) [0x149415d3da93] May 6 12:57:37 UNRAID02 smbd[31869]: #22 /usr/lib64/libtevent.so.0(+0xea59) [0x149415d3fa59] May 6 12:57:37 UNRAID02 smbd[31869]: #23 /usr/lib64/libtevent.so.0(+0xcd77) [0x149415d3dd77] May 6 12:57:37 UNRAID02 smbd[31869]: #24 /usr/lib64/libtevent.so.0(_tevent_loop_once+0x91) [0x149415d38b61] May 6 12:57:37 UNRAID02 smbd[31869]: #25 /usr/lib64/libtevent.so.0(tevent_common_loop_wait+0x1b) [0x149415d38e3b] May 6 12:57:37 UNRAID02 smbd[31869]: #26 /usr/lib64/libtevent.so.0(+0xcd17) [0x149415d3dd17] May 6 12:57:37 UNRAID02 smbd[31869]: #27 /usr/lib64/libsmbd-base-samba4.so(smbd_process+0x817) [0x1494161adce7] May 6 12:57:37 UNRAID02 smbd[31869]: #28 /usr/sbin/smbd(+0xb090) [0x5604970ba090] May 6 12:57:37 UNRAID02 smbd[31869]: #29 /usr/lib64/libtevent.so.0(tevent_common_invoke_fd_handler+0x91) [0x149415d39791] May 6 12:57:37 UNRAID02 smbd[31869]: #30 /usr/lib64/libtevent.so.0(+0xec87) [0x149415d3fc87] May 6 12:57:37 UNRAID02 smbd[31869]: #31 /usr/lib64/libtevent.so.0(+0xcd77) [0x149415d3dd77] May 6 12:57:37 UNRAID02 smbd[31869]: #32 /usr/lib64/libtevent.so.0(_tevent_loop_once+0x91) [0x149415d38b61] May 6 12:57:37 UNRAID02 smbd[31869]: #33 /usr/lib64/libtevent.so.0(tevent_common_loop_wait+0x1b) [0x149415d38e3b] May 6 12:57:37 UNRAID02 smbd[31869]: #34 /usr/lib64/libtevent.so.0(+0xcd17) [0x149415d3dd17] May 6 12:57:37 UNRAID02 smbd[31869]: #35 /usr/sbin/smbd(main+0x1489) [0x5604970b7259] May 6 12:57:37 UNRAID02 smbd[31869]: #36 /lib64/libc.so.6(+0x23177) [0x149415b44177] May 6 12:57:37 UNRAID02 smbd[31869]: #37 /lib64/libc.so.6(__libc_start_main+0x85) [0x149415b44235] May 6 12:57:37 UNRAID02 smbd[31869]: #38 /usr/sbin/smbd(_start+0x21) [0x5604970b7b31] May 6 12:57:37 UNRAID02 smbd[31869]: [2023/05/06 12:57:37.830194, 0] ../../source3/lib/dumpcore.c:315(dump_core) May 6 12:57:37 UNRAID02 smbd[31869]: dumping core in /var/log/samba/cores/smbd This is UNRAID version 6.11.5. I have the following SMB settings [global] idmap config * : backend = tdb idmap config * : range = 1000-7999 idmap config DOMAIN : backend = rid idmap config DOMAIN : range = 10000-4000000000 unraid02-diagnostics-20230506-1307.zip
-
Yes, done. Thanks.
-
Suggestion for an improvement: Please see this support issue I raised: Fix Common Problems Reporting Server Out Of Memory Errors Basically if a container that has restricted RAM runs out of that RAM UNRAID will "sacrifice the child" and kill the container process, this gets reported to the syslog. Fix Common Problems reports this as if the server has run out of memory. It would be nicer to report that "container X has run out of memory...".
-
OK I've done some further research. This may be a false alarm from the Fix Common Problems plugin. The actual error is "Memory cgroup out of memory", this is not the server running out of memory - rather a single container, which was constrained to 2GB total, has run out of memory. The OS has restarted just that container and flagged this warning. So the warning from Fix Common Problems about "Your server has run out of memory..." is a bit misleading (and overly worrying). Perhaps Fix Common Problems can detect this as a different kind of error and report "Your container X has run out of memory..."
-
Thanks for the quick response. >If it's a one time thing you can ignore, It's ocurred twice now. Both in the last 3 weeks. If it occurs again I'll post back here. >if it keeps happening try limiting more the RAM for VMs and/or docker containers, the problem is usually not just about not enough RAM but more about fragmented RAM, Can you explain some more on this point please? As I have less than 25% utilization of RAM on this server (over 100GB RAM free) it would be strange for fragmentation to occur, this normally only occurs when RAM usage is getting over 50%. A quick look at top shows over 104GB is used by cache and this gets reallocated as application RAM as needed. >alternatively a small swap file on disk might help, you can use the swapfile plugin: Can you also explain a bit more about this, as I understood it virtual memort won't use swap unless the server gets very low on physical RAM (regardless of any fragmentation)?
-
Checking the syslog I think I see that there's an error caused by a docker container: Mar 20 04:27:41 UNRAID02 kernel: oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=75989cd4cdfb95d6d4cc0def9b3ed1360cd6f88458130216d3fb6f75b56036b6,mems_allowed=0-1,oom_memcg=/docker/75989cd4cdfb95d6d4cc0def9b3ed1360cd6f88458130216d3fb6f75b56036b6,task_memcg=/docker/75989cd4cdfb95d6d4cc0def9b3ed1360cd6f88458130216d3fb6f75b56036b6,task=s3cmd,pid=17525,uid=0 Mar 20 04:27:41 UNRAID02 kernel: Memory cgroup out of memory: Killed process 17525 (s3cmd) total-vm:567788kB, anon-rss:516056kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:1152kB oom_score_adj:0 ... Mar 20 04:28:34 UNRAID02 kernel: oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=75989cd4cdfb95d6d4cc0def9b3ed1360cd6f88458130216d3fb6f75b56036b6,mems_allowed=0-1,oom_memcg=/docker/75989cd4cdfb95d6d4cc0def9b3ed1360cd6f88458130216d3fb6f75b56036b6,task_memcg=/docker/75989cd4cdfb95d6d4cc0def9b3ed1360cd6f88458130216d3fb6f75b56036b6,task=s3cmd,pid=17526,uid=0 But this container is set up so it can only use 2GB of ram (using extra parameter --memory=2G) and usually only uses a fraction of that. So how can this be causing Out of Memory errors on the server itself?






