




TheDon
Members
-
Joined
-
Last visited
Everything posted by TheDon
-
Swapped to the new server name in my wg0.conf, worked instantly on container restart. Thanks @binhex !
-
It seems like to maybe the list of servers have changed (see below) Also the names ending in pvt.site feels newish. This is the list in the logs, and my chosen server (from my wg0.conf) no longer exists, not sure if binhex grabs the list dynamically from an api or included it when the container gets updated [info] fi-2.privacy.network [info] srilanka.privacy.network [info] cyprus.privacy.network [info] mongolia.privacy.network [info] np-nepal-pf.privacy.network [info] ba.privacy.network [info] ua.privacy.network [info] sanjose.privacy.network [info] ca-toronto.privacy.network [info] morocco.privacy.network [info] gt-guatemala-pf.privacy.network [info] de-germany-so.privacy.network [info] kazakhstan.privacy.network [info] montenegro.privacy.network [info] nl-amsterdam.privacy.network [info] bangladesh.privacy.network [info] ca-ontario.privacy.network [info] ca-montreal.privacy.network [info] malta.privacy.network [info] bahamas.privacy.network [info] ec-ecuador-pf.privacy.network [info] liechtenstein.privacy.network [info] yerevan.privacy.network [info] lu.privacy.network [info] albania.pvt.site [info] algeria.pvt.site [info] argentina.pvt.site [info] au-adelaide.pvt.site [info] au-brisbane.pvt.site [info] au-melbourne.pvt.site [info] au-perth.pvt.site [info] au-sydney.pvt.site [info] belgium.pvt.site [info] brazil.pvt.site [info] bulgaria.pvt.site [info] china.pvt.site [info] colombia.pvt.site [info] croatia.pvt.site [info] czech-republic.pvt.site [info] de-berlin.pvt.site [info] de-frankfurt.pvt.site [info] denmark.pvt.site [info] egypt.pvt.site [info] es-madrid.pvt.site [info] es-valencia.pvt.site [info] estonia.pvt.site [info] fi-helsinki.pvt.site [info] france.pvt.site [info] georgia.pvt.site [info] greece.pvt.site [info] greenland.pvt.site [info] hungary.pvt.site [info] iceland.pvt.site [info] indonesia.pvt.site [info] ireland.pvt.site [info] israel.pvt.site [info] it-milano.pvt.site [info] jp-tokyo.pvt.site [info] latvia.pvt.site [info] lithuania.pvt.site [info] malaysia.pvt.site [info] mexico.pvt.site [info] moldova.pvt.site [info] new-zealand.pvt.site [info] nigeria.pvt.site [info] north-macedonia.pvt.site [info] norway.pvt.site [info] philippines.pvt.site [info] poland.pvt.site [info] portugal.pvt.site [info] qatar.pvt.site [info] romania.pvt.site [info] saudi-arabia.pvt.site [info] se-stockholm.pvt.site [info] serbia.pvt.site [info] singapore.pvt.site [info] slovakia.pvt.site [info] slovenia.pvt.site [info] south-africa.pvt.site [info] switzerland.pvt.site [info] taiwan.pvt.site [info] turkey.pvt.site [info] uk-london.pvt.site [info] uk-manchester.pvt.site [info] uk-southampton.pvt.site [info] united-arab-emirates.pvt.site 2026-05-12 11:20:45,373 DEBG 'start-script' stdout output: [info] Script finished to assign incoming port
-
Yup I also just ran into this, even had a monthly donation to the project i just had to end. Sad day. @binhex Not sure what the protocol is for you, but you may want to put something at the beginning of the forum post or in a pinned post. https://wiki.servarr.com/readarr#announcement-retirement-of-readarr
-
@JorgeBThanks again for the share, I have been stable ever since! marked your response as a solution.
-
I was linked to this, and it appears to have solved my problem. TLDR: i had to switch the version of a docker container i run to a special release tag, to prevent some issue with libtorrent 2.X
-
@JorgeBThanks for linking me to this one, I had not yet made the connection to Deluge, I have also found the first command that lets me get my webgui back without having to force an unclean shutdown "/etc/rc.d/rc.docker restart", that on its own is a huge relief. I have updated the repo for my binhex container, and will bee keeping an eye on stability for the next few days, thanks for the forum link, this seems promising!
-
Man it really felt like it was finally solved, but it eventually crashed out saturday, (so I grabbed the first diags below), and then between then and sunday it did it agaion (second diag). I am having to ssh into the server, run diagnostics, and then send reboot command twice in order to get the box to restart (so I can get the gui going again). Any advice on what to try next? oxygen-diagnostics-20230909-2153.zip oxygen-diagnostics-20230910-1711.zip
-
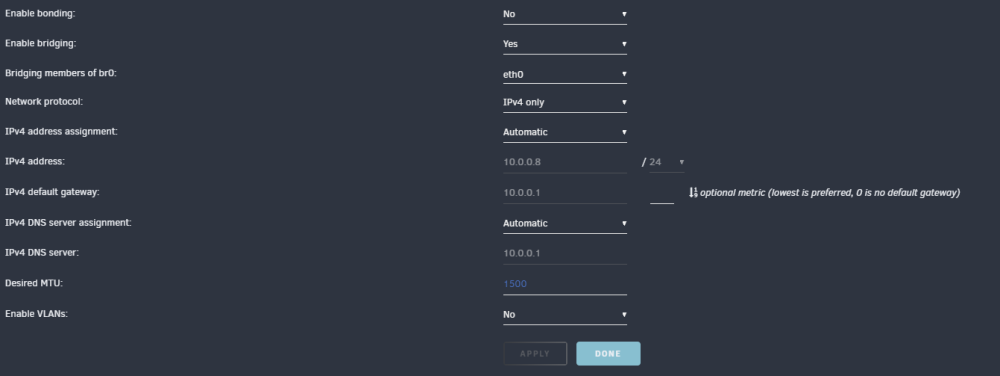
After: Post reboot: @ljm42What do the call traces look like in the logs?
-
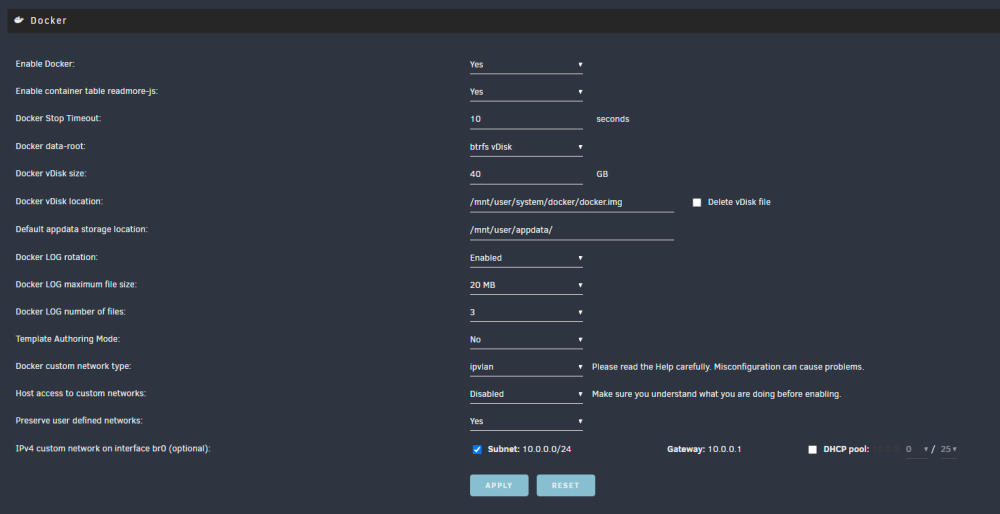
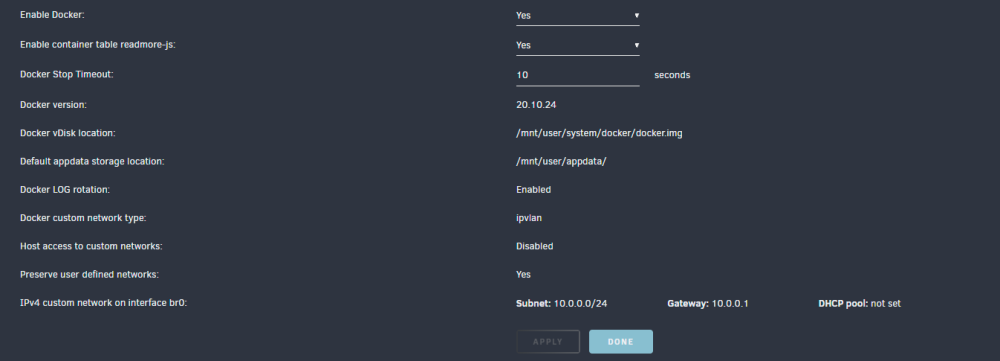
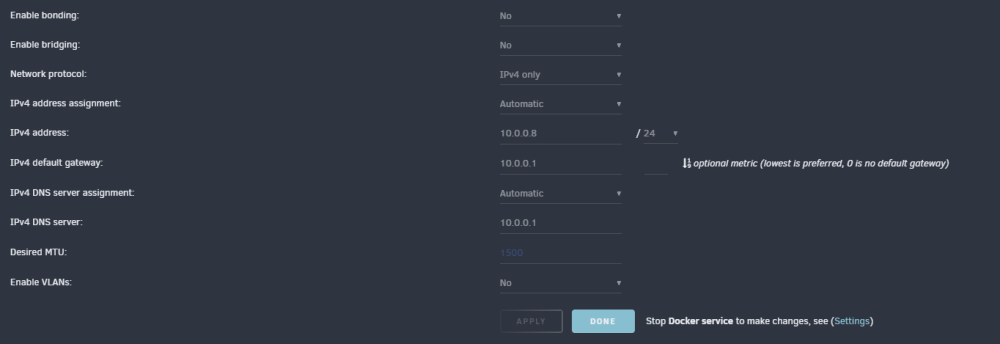
@ljm42 These are my current settings: I will enable bridging, and make sure the system is ipvlan.
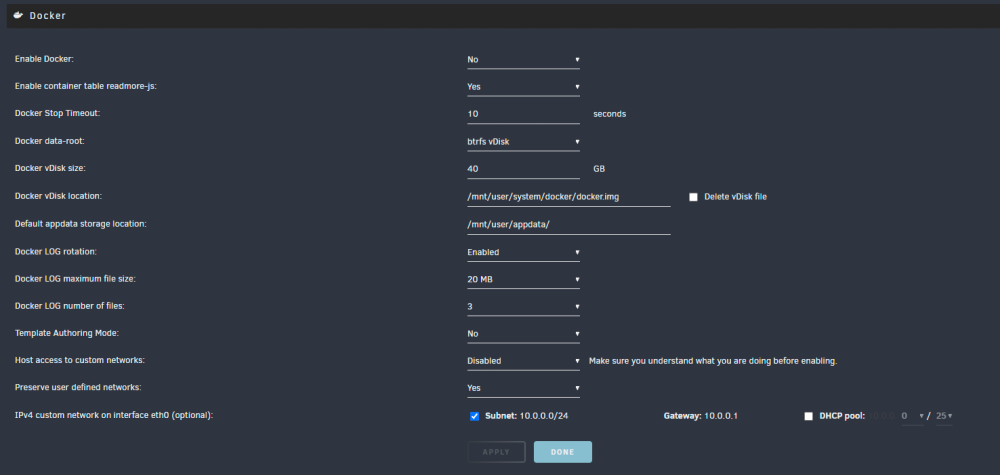
-
@ljm42 good idea on the other thread, dont want to bog down the release thread. I have been following the other thread (the one where you notified everyone of 6.12.4rcXX) for the docker stuff, and this entire time I was thinking this was was my issues (especially since I was getting the nginx 500 if i let me page try and load for long enough
-
I am still seeing my UI crash, even with the update to 6.12.4. I am set to ipvlan since 6.12.3, bridging and bonding set to No. Any ideas what might also be causing this, since Lime has seemed to resolve the docker networking issues (originally what i thought was causing the issue). oxygen-diagnostics-20230903-2316.zip oxygen-diagnostics-20230904-2039.zip
-
I am extremely jealous. I have no clue what's happening with my server, and its very frustrating having to perform a reboot at minimum once a day. Thanks for directing me to that forum post, it seems like the one to follow for this issue.
-
@david279 As far as I can tell in the thread, there is still no solution? Are you having the issue as well?
-
My unraid server is experiencing a weird issue where the UI for unraid eventually stops responding. To resolve this i usually have to ssh in and then run the poweroff command twice. When i try and load the webui, sometimes the top of the UI will load (nothing under the area in line with the server version unber and tabs, this may just be webpage caching thought.) Eventually the webapge stops trying to load, and shows "500 Internal Server Error nginx" MY docker containers seem to run as normal (although one does seem to have issues, but most of my other container web interfaces can be interacted with when the server is like this. I have attempted the /etc/rc.d/rc.php-fpm restart command, and while that seems to run sucessfully, it appears as if nothing is resolved. I ran the diagnostics over the ssh, but I wasnt sure if I needed to add a special flag or something to make them anonymous like you do in the UI (a checkbox for anonymous). I basically restart/poweroff command my server every day, and by end of work day or a bit later, the unraid ui no longer functions. So i rinse and repeat. Parity checks trigger everytime (on boot), so the poweroff command isnt working like I hoped to perform a clean shutdown. Anyone have any ideas what I could look into to try and diagnose this kind of system crash, or what im looking for in my diagnostics files.
-
Does the application still have the issue requiring fresh databases often? Also I had not heard about the requiring separate instances for eBook vs audiobook yet, thats unfortunate. Thanks for your template work on this @binhex! @awediohead I have a large collection of audiobooks too, but haven't really taken the plunge of shoving it into plex, got any guides or advice on how to tackle that? Ive seen a couple of guides around before last time I look into in, curious what you tried.
-
Explains my situation then, I'll wait for that to hit master. Thanks @Squid!
-
I ran into this same problem, but even after clearing the containers in an attempt to start fresh, i still dont have the default config, logs, etc. Is there some way to make sure the templates are updated? Also, if you are setting up tdarr, and it asks for server IP, do you put the host (brdige mode) or reference itself? Same question for node, it asks for both server IP and node. I assume i put unraid IP (bridge again) for the server, but for node is it referring to self.
-
Pull down of container was fine, but I get the same error as other mention above. The webUI wouldn't load in chrome each attempt to load appeared to create more of the error below in logs, but I loaded in MSFT Edge (new), and the page loaded fine (and I was able to log in with admin:admin). "invalid HTTP request size (max 4096)...skip" I can provide more info if you think it would be helpful
-
I can confirm myself, and a colleague are also getting having an issue with Exit code '56' using ca-vancouver as @jedimstr indicates above.
-
I don't think this is necessarily true, since using the paths i stated, the locations should be on my cache drive in my appdata share, which i confirmed the directories did get created, but are empty ( i have only run the docker startup, so that might be normal if i have yet to import and account or anything like that). My x2 512 nvme cache drives are pooled and contain all my appdata. I don't recall where, but i think i have read that its better to use the file path /mnt/user/sharename rather than /mnt/cache or /mnt/disk? I still may not be understanding Squid's post 100%.
-
An idea from a novice unraid user, who wast sure what to do at first for the database and recipes blanks. Since you have the appdata autofilled, you should provide some guidance on how to populate the database and recipes blanks. Maybe something in the overview could help? I filled them in as follows, but couldn't use the drop down menu since the folders didn't exist yet. Also you may want to include an update image of the template with the correct blanks filled in the way Squid suggests, which i think ends up like the way below: /mnt/user/appdata/ferdi-server/recipes /mnt/user/appdata/ferdi-server/database So far it looks like it ran and setup correctly.
-
This test worked for me as well. My x2 12TBs from WD easystores have failed once or twice already with the signature error. Currently they are running again starting from the ZERO point (skip pre-read).






