danktankk
Members
-
Joined
-
Last visited
-
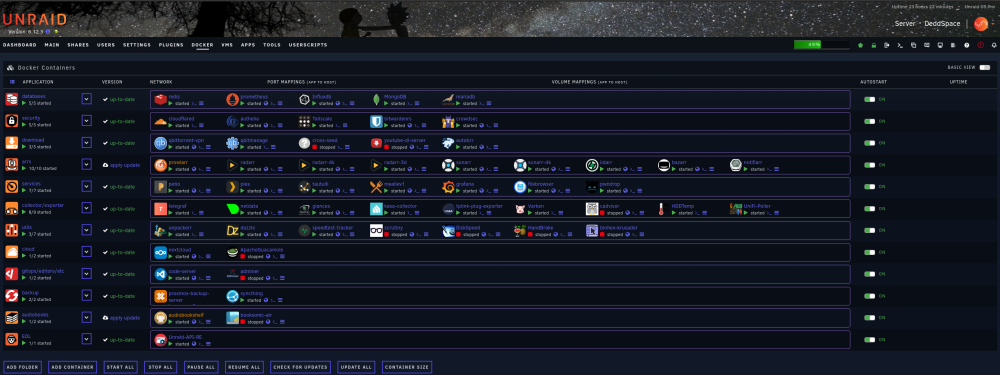
I have 90 containers running in my server. A quick glance at the docker dash with this implemented could show me quickly which containers I pinned and will need to be updated manually. It probably sounds silly, but I don't remember every container I pinned to a version, especially those that were pinned a long time ago. My suggestion is to simply add a little 'pin' icon overlay/element on the top corner of your container icon/image similar to what android devices do on their icons to let you know you have an update. This way you can see very easily your apps that will need manual intervention for updating. I attached a super fast edit to better illustrate what I mean.
-
Great app! when you try to create a user and the email is set up, it won't work. You have to remove that information first and then your login will work. Anyway, as odd as that is, afterward I am able to add my email variables and it seems to be ok. But when testing the forgot password option, the email sent has a link that has 'undefined' for the domain and therefore doesn't resolve to anything to reset the password. Any ideas on what I need to do to correct this? I didnt see any variable I might need to add other than what I have already in there, including the admin variable: https://linkwarden.domain.com/api/v1/auth The email it is sending to has a link to reset the password that looks like: http://undefined/auth/reset-password?token=<string> Any help would be appreciated. Thanks.
-
I am also having issues getting the login to work. any progress?
-
Varken is dead dead dead. wont even start. Great board, not the best idea to keep varken in its current state. Thanks for the new board
-
I suppose you are right, but it just seems really odd that this container is just so much larger than literally anything else that I am running. Obviously its not the end of the world or anything and if the dev does decide to remove the Flutter UI, it will probably help. I just noticed it mainly because I am getting warning that my docker img is getting full. Its 50GB and almost full lol. Thanks for the explanation. I am betting that is the case.
-
I would also like to figure out why this image is so large. I have a lot of containers and this one is nearly twice as big as my largest container. WTF LOL here is the top of my image list showing just how much bigger an invoice container is than all the rest of my largest containers. 4410MB - maihai/invoiceninja_v5 2850MB - holaflenain/stable-diffusion 2460MB - ghcr.io/imagegenius/immich Crazy...
-
ive had this problem forever now and still dont know why it is doing that. is there a way to fix it so it remembers the theme i set after a reboot?
-
I have this exact same issue as well. Not sure what happened. Im running 6.12.8.
-
The plugin just stopped working. I made zero changes to it (as it is pretty much a plug-in). Has anyone else had this happen? Its almost as if it doesnt know it is supposed to group the icons now. Very strange. I just replaced it with a backup and its fine now. so something changed, I just dont know what. No need to reply unless someone knows what happened with an update or something.
-
There is nothing to elaborate. I have it working fine and admittedly, it is a very nice replacement. I have everything as it should be and it was very easy to do so. I even used the svg icons from the former plugin as well. The plugins documentation was all I needed to get it to work as expected and it is also intuitively configured 'out of the box' to where I had minimal issues with configuring anything extra that I wanted. You are 100% right that unraid, nor the maintainers of this plugin have anything to do with docker folders deprecation and it wouldn't matter anyway. Complaining about free software from people that work hard to provide anything beneficial is not the best use of ones time to say the least. It was late, I was tired and just hated checking "one last thing real quick" only to find i needed to "fix" yet another problem from doing nothing more than well.... nothing. It still surprises me that you can literally do nothing and break your install for [insert linux distro here]. Thats just how linux is. It's by design and I totally get it. That being said, I would just like to thank all here that have made this new plugin possible and also offer my sincere apologies for my momentary lapse in logical thought. TL:DR My bad lol It will need further refinement on my end to work for me, but I was able to do this in less than 15 minutes having never used this plugin before. Well done on the ease of use!
-
this isnt working at all for me.. 6.12.3 user and the original plugin was janked out and I was forced to move to this if i want similar functionality, which there was ZERO warning for.... just another reason to leave unraid. i cannot express how bad this pisses me off without being banned from this forum.
-
i definitely like the new look and appreciate your efforts. changing ports shouldn't be a big issue i wouldn't think. is there a comparison between what we have now and the omni version? admittedly, its a little confusing.
-
I just looked on github and found v1.0.0beta-RC1. is that the same one you are talking about? the fuzzy search is for recipes already in mealie, correct?
-
Thank you for continuing this project! I was looking on github and happened to notice what I had been using had not been updated in over a year lol - It took me a minute to figure out what was going on with mealie but after I thought to look in unraid CA, I was able to get this working easily by reading and any questions I had were already addressed here. It was also super easy to get it set up as well. This is definitely a very minor issue, but I was wondering if there are plans to restore the icon for mealie? It looks like the link for it has been removed/moved. Thanks again!
-
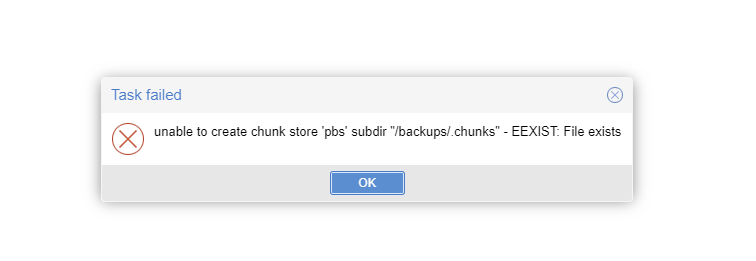
[EDIT] I was able to correct this by simply replacing the old datastore.cfg in place of the new one. I had a weird 403 error in the webui for this container and couldn't solve it. I redownloaded the container and have it running again, but it says it can't write a chunks directory. How do I add an existing datastore I guess is my question. Many thanks for any help [NEW] If anyone has this running with nginx, I could use a sample conf file. I have been trying today with little success.