




Bleak
Members
-
Joined
-
Last visited
Everything posted by Bleak
-
I am also getting spammed with this log line Jul 21 20:50:34 <SERVER_NAME> nginx: 2026/07/21 20:50:34 [error] #: *<CONNECTION_ID> open() "/usr/local/emhttp/plugins/dynamix.docker.manager/images/question.png" failed (2: No such file or directory) while sending to client, client: <CLIENT_IP>, server: <ANONYMIZED_MYUNRAID_HOST>, request: "GET /plugins/dynamix.docker.manager/images/question.png HTTP/2.0", host: "<ANONYMIZED_MYUNRAID_HOST>", referrer: "https://<ANONYMIZED_MYUNRAID_HOST>/Docker" I have fixed the log spamming and the missing picture for now by giving those dockers a random icon url. But would like to know how to fix it permanently. On 7.3.2
-
Thanks and again thank you for keeping this alive!
-
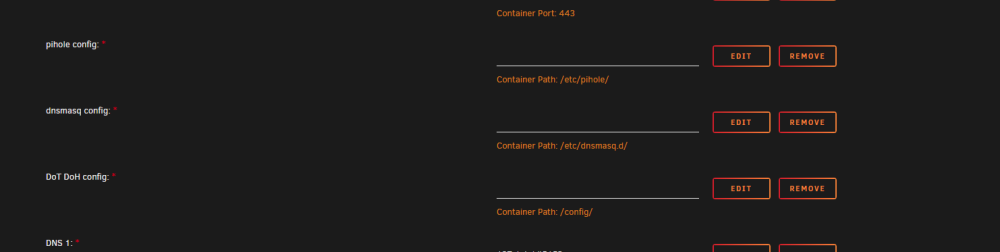
When doing a clean install your template is empty at the following places You need to fill this to be able to create the docker and without these filled there will not be a appdata directory for this docker. I filled this with: /mnt/user/appdata/pihole-dot-doh/pihole/ /mnt/user/appdata/pihole-dot-doh/dnsmasq.d/ /mnt/user/appdata/pihole-dot-doh/config/ (copied from the original outdated testdasi template) Maybe you can fill these in the template with the above? Makes it a little easier to install for the first time . EDIT: Thank you for keeping this docker alive in unraid!
-
Due to some issues I had for a longer time decided to clean install the docker removing appdata directory for pihole-dot-doh aswell. After the new install it creates the directory with the subdirectories: config, dnsmasq.d and pihole. In the config directory there used to be two yamls for cloudflared and stubby. But they were not placed in there. For some reason my pihole is able to reach both 127.2.2.2@5253 and 127.1.1.1#5153 But I am unable to find where the config files are since I want to edit them.
-
Stubby (DOT/TLS) by default uses google. you can change this in the stubby config file in your appdata by adding # to the google config and removing them from the cloudflare config. If you already did this then perhaps the file got removed or corrupt on the last update and was replaced. I've had issues in the past with cloudflared(DOH/https) but it seems to be working fine for me for a long time now, so consider using that. As in my opinion it is marginally better privacy wise as you will "hide" your dns traffic under the gianourmous load of https traffic. You could use both doh and dot but I do need see the benefit of this.
-
Is is one of the config files that it comes with thr cloudflared config file is for DOH (DNS over https) and the stubby config file is for DOT (DNS over TLS). I am having issues eith DOH so I set The DOT as the first dns server. Since then no issues.
-
Can you try setting stubby(tls) as first and doh as second and see if your issues go away? I have too little knowledge to be certain but DOH seems to cause my issues.
-
I had the cloudflared (DOH) as both options set it back to how it was only changed the stubby (TLS) to cloudflared instead of google. Seems bit better now.. not sure why everything goes to **** with only DOH. (Also maybe it was not very smart of me to have unraid get it's dns by DHCP which would be the phole docker on unraid...)
-
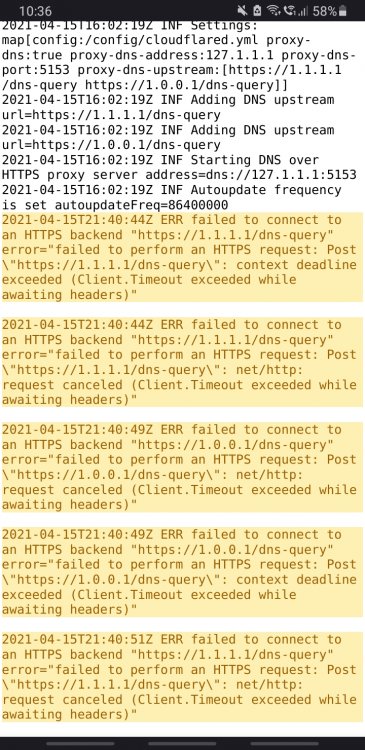
I am now also having the following error shown in the logs(see attachment) also fix common problems says I should connect to 8.8.8.8 or github could be down so seems unraid thinks there is no connection anymore. (nothing is being blocked for unraid)
-
Hi when I restart the docker it stops after DNS service is not running it will only continue when I change the /etc/resolv.conf to a dns server instead of 127.0.0.11 It will always revert that change by itself once it has started. While it is stuck there I cannot access the web page. I thought it was because of the server variable but that seems to not care whatever it is (can someone explain to me what that variable is for?) [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] 01-resolver-resolv: applying... [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] 01-resolver-resolv: applying... [fix-attrs.d] 01-resolver-resolv: exited 0. [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 20-start.sh: executing... ::: Starting docker specific checks & setup for docker pihole/pihole [i] Installing configs from /etc/.pihole... [i] Existing dnsmasq.conf found... it is not a Pi-hole file, leaving alone! Converting DNS1 to PIHOLE_DNS_ Converting DNS2 to PIHOLE_DNS_ Setting DNS servers based on PIHOLE_DNS_ variable ::: Pre existing WEBPASSWORD found DNSMasq binding to default interface: eth0 Added ENV to php: "PHP_ERROR_LOG" => "/var/log/lighttpd/error.log", "ServerIP" => "10.11.22.33", "VIRTUAL_HOST" => "10.11.22.33", Using IPv4 ::: Preexisting ad list /etc/pihole/adlists.list detected ((exiting setup_blocklists early)) https://raw.githubusercontent.com/StevenBlack/hosts/master/hosts ::: Testing pihole-FTL DNS: FTL started! ::: Testing lighttpd config: Syntax OK ::: All config checks passed, cleared for startup ... ::: Enabling Query Logging [i] Enabling logging... ::: Docker start setup complete [✗] DNS service is not running [i] Neutrino emissions detected...
-
I swear I've searched this whole thing 10 times no clue how I missed this... Thanks anyway sorry for missing this..
-
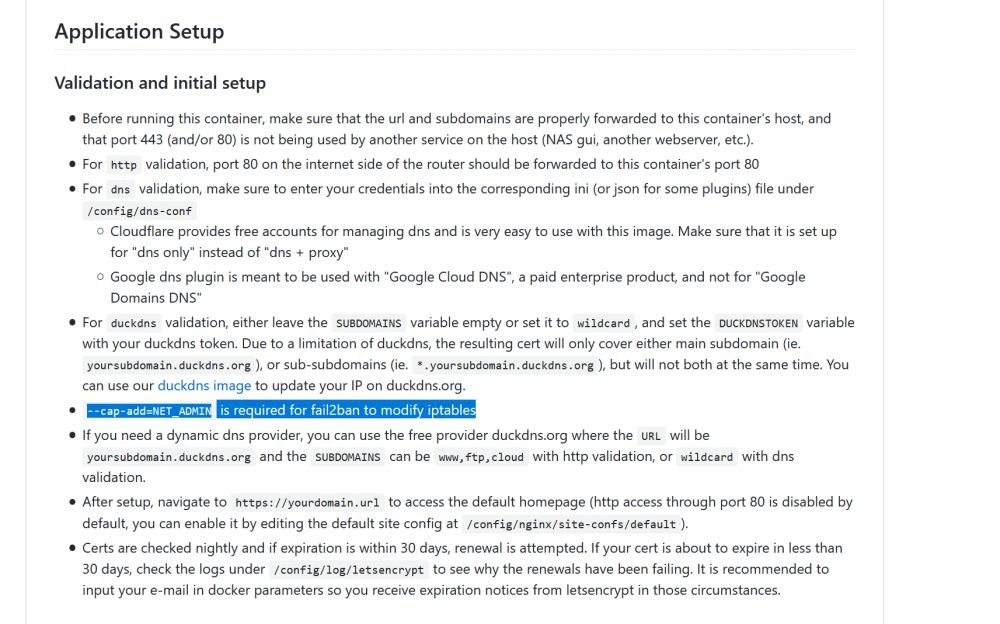
Added --cap-add=NET_ADMIN to extra parameters. Found it somewhere in a forum apparently it should be mentioned somewhere that you need this but could not find it. Can someone link me something that explains what this does exactly? (or tell me ofcourse) want to understand what i just did and why i missed it..
-
Hey so I am trying to setup basic auth with fail2ban and the authenticating is working great but fail2ban does not seem to do it's part: 020-05-09 18:31:32,502 fail2ban.filter [388]: INFO [nginx-http-auth] Found 84.241.199.134 - 2020-05-09 18:31:31 2020-05-09 18:31:38,515 fail2ban.filter [388]: INFO [nginx-http-auth] Found 84.241.199.134 - 2020-05-09 18:31:37 2020-05-09 18:31:43,727 fail2ban.filter [388]: INFO [nginx-http-auth] Found 84.241.199.134 - 2020-05-09 18:31:43 2020-05-09 18:31:44,462 fail2ban.actions [388]: NOTICE [nginx-http-auth] Ban 84.241.199.134 2020-05-09 18:31:44,465 fail2ban.utils [388]: #39-Lev. 1501c3a14110 -- exec: iptables -w -N f2b-nginx-http-auth iptables -w -A f2b-nginx-http-auth -j RETURN iptables -w -I INPUT -p tcp -m multiport --dports http,https -j f2b-nginx-http-auth 2020-05-09 18:31:44,466 fail2ban.utils [388]: ERROR 1501c3a14110 -- stderr: "iptables v1.8.3 (legacy): can't initialize iptables table `filter': Permission denied (you must be root)" 2020-05-09 18:31:44,466 fail2ban.utils [388]: ERROR 1501c3a14110 -- stderr: 'Perhaps iptables or your kernel needs to be upgraded.' 2020-05-09 18:31:44,466 fail2ban.utils [388]: ERROR 1501c3a14110 -- stderr: "iptables v1.8.3 (legacy): can't initialize iptables table `filter': Permission denied (you must be root)" 2020-05-09 18:31:44,466 fail2ban.utils [388]: ERROR 1501c3a14110 -- stderr: 'Perhaps iptables or your kernel needs to be upgraded.' 2020-05-09 18:31:44,466 fail2ban.utils [388]: ERROR 1501c3a14110 -- stderr: 'getsockopt failed strangely: Operation not permitted' 2020-05-09 18:31:44,466 fail2ban.utils [388]: ERROR 1501c3a14110 -- returned 1 2020-05-09 18:31:44,467 fail2ban.actions [388]: ERROR Failed to execute ban jail 'nginx-http-auth' action 'iptables-multiport' info 'ActionInfo({'ip': '84.241.199.134', 'family': 'inet4', 'fid': <function Actions.ActionInfo.<lambda> at 0x1501c3ece3a0>, 'raw-ticket': <function Actions.ActionInfo.<lambda> at 0x1501c3ece940>})': Error starting action Jail('nginx-http-auth')/iptables-multiport 2020-05-09 18:31:48,940 fail2ban.filter [388]: INFO [nginx-http-auth] Found 84.241.199.134 - 2020-05-09 18:31:48 2020-05-09 18:31:54,150 fail2ban.filter [388]: INFO [nginx-http-auth] Found 84.241.199.134 - 2020-05-09 18:31:54 2020-05-09 18:31:59,362 fail2ban.filter [388]: INFO [nginx-http-auth] Found 84.241.199.134 - 2020-05-09 18:31:58 2020-05-09 18:31:59,686 fail2ban.actions [388]: NOTICE [nginx-http-auth] 84.241.199.134 already banned 2020-05-09 18:32:05,374 fail2ban.filter [388]: INFO [nginx-http-auth] Found 84.241.199.134 - 2020-05-09 18:32:04 Basically trying from my phone on 4g to get myself banned but i can just keep retrying even though max retry's is at 3 if i try it for the 10th time and enter it correctly i just get in. dont know what the above errors mean tried to google it but did not find anything that helped me..
-
Found this post on LTT root@fold8:~# cd /var/lib/fahclient/work/ root@fold8:/var/lib/fahclient/work# ls -alh total 72K drwxrwxrwx 3 fahclient root 4.0K Mar 9 19:00 . drwxrwxr-x 6 fahclient root 4.0K Feb 28 20:36 .. drwxrwxrwx 3 fahclient root 4.0K Mar 9 19:17 00 -rw-r--r-- 1 fahclient root 40K Mar 9 19:17 client.db -rw-r--r-- 1 fahclient root 17K Mar 9 19:17 client.db-journal Should be like this so not sure why it creates them as drwxr-xr-x.
-
root@Zeus:/mnt/user/appdata/FoldingAtHome/work# ls -alh total 56K drwxr-xr-x 1 nobody users 78 Mar 16 22:45 ./ drwxrwxrwx 1 nobody users 107 Mar 16 20:21 ../ drwxr-xr-x 1 nobody users 42 Mar 16 23:12 00/ drwxr-xr-x 1 nobody users 224 Mar 16 23:14 01/ drwxr-xr-x 1 nobody users 4.0K Mar 16 23:24 02/ -rw-r--r-- 1 nobody users 32K Mar 16 23:25 client.db -rw-r--r-- 1 nobody users 17K Mar 16 23:25 client.db-journal This does not seem right..? Just deleted the folder using krusader but no clue if it will return after next WU finishes.
-
21:46:07:WU02:FS00:0xa7:Completed 1 out of 125000 steps (0%) 21:46:32:WU00:FS00:Cleaning up 21:46:32:ERROR:WU00:FS00:Exception: Failed to remove directory './work/00': boost::filesystem::remove: Directory not empty: "./work/00" 21:47:56:WU01:FS01:0x22:Completed 80000 out of 1000000 steps (8%) 21:48:10:WU00:FS00:Cleaning up 21:48:10:ERROR:WU00:FS00:Exception: Failed to remove directory './work/00': boost::filesystem::remove: Directory not empty: "./work/00" 21:49:58:WU02:FS00:0xa7:Completed 1250 out of 125000 steps (1%) 21:50:47:WU00:FS00:Cleaning up 21:50:47:ERROR:WU00:FS00:Exception: Failed to remove directory './work/00': boost::filesystem::remove: Directory not empty: "./work/00" 21:51:36:WU01:FS01:0x22:Completed 90000 out of 1000000 steps (9%) 21:53:53:WU02:FS00:0xa7:Completed 2500 out of 125000 steps (2%) 21:55:01:WU00:FS00:Cleaning up 21:55:01:ERROR:WU00:FS00:Exception: Failed to remove directory './work/00': boost::filesystem::remove: Directory not empty: "./work/00" 21:55:16:WU01:FS01:0x22:Completed 100000 out of 1000000 steps (10%) 21:57:36:WU02:FS00:0xa7:Completed 3750 out of 125000 steps (3%) 21:59:33:WU01:FS01:0x22:Completed 110000 out of 1000000 steps (11%) 22:01:30:WU02:FS00:0xa7:Completed 5000 out of 125000 steps (4%) 22:01:53:WU00:FS00:Cleaning up 22:01:53:ERROR:WU00:FS00:Exception: Failed to remove directory './work/00': boost::filesystem::remove: Directory not empty: "./work/00" 22:03:14:WU01:FS01:0x22:Completed 120000 out of 1000000 steps (12%) 22:05:21:WU02:FS00:0xa7:Completed 6250 out of 125000 steps (5%) 22:06:54:WU01:FS01:0x22:Completed 130000 out of 1000000 steps (13%) 22:09:10:WU02:FS00:0xa7:Completed 7500 out of 125000 steps (6%) 22:10:35:WU01:FS01:0x22:Completed 140000 out of 1000000 steps (14%) 22:12:58:WU00:FS00:Cleaning up 22:12:58:ERROR:WU00:FS00:Exception: Failed to remove directory './work/00': boost::filesystem::remove: Directory not empty: "./work/00" 22:13:02:WU02:FS00:0xa7:Completed 8750 out of 125000 steps (7%) I keep getting the following error is this a permission issue and if so how can I allow FAH to delete these directory's?
-
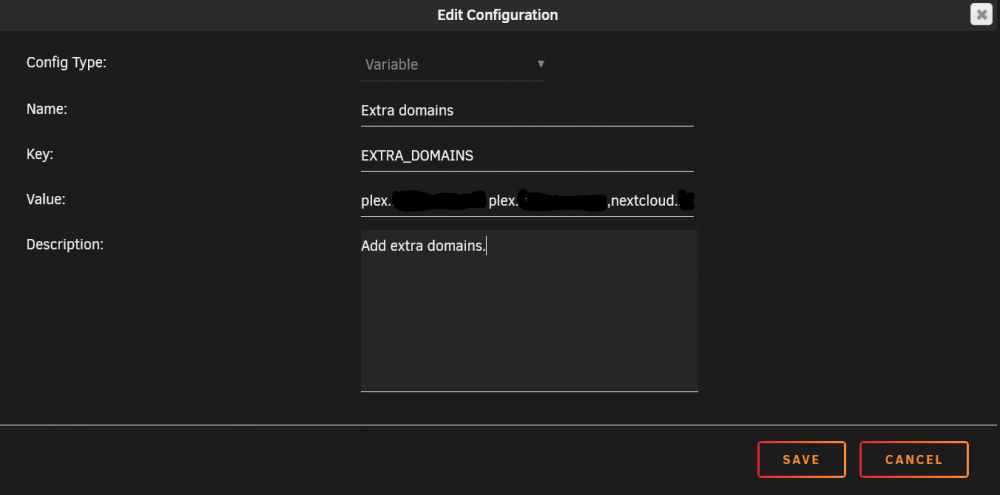
Hi not sure why you would want multiple instances for let's encrypt. If you need to add extra domains just add an extra variable with the name Extra domains. As the value use EXTRA_DOMAINS and then in the key you can add extra domains note this has to be the full version you want so example.domain.com and not domain.com if you need even more add them with a comma like this example.domain.com,example2.domain.com,example3.domain.com etc... So in my case I want to be able to reach my plex from 3 different domains I add one the normal way as top domain and with the sub domains. and the other two in the extra domains. Hope this helps!
-
Thank you!
-
Hi question, Tried to find this online but could not find it. I have two instances of a few dockers running ("radarr and radarr4k" "bazarr and bazarr4k"). Now I have succesfully set up the not 4k intended dockers with let's encrypt and all is working now I want to do the same for the 4k intended dockers. I have done the following changes in the conf already: # make sure that your dns has a cname set for bazarr and that your bazarr container is not using a base url server { listen 443 ssl; listen [::]:443 ssl; server_name bazarr4k.*; include /config/nginx/ssl.conf; client_max_body_size 0; # enable for ldap auth, fill in ldap details in ldap.conf #include /config/nginx/ldap.conf; location / { # enable the next two lines for http auth #auth_basic "Restricted"; #auth_basic_user_file /config/nginx/.htpasswd; # enable the next two lines for ldap auth #auth_request /auth; #error_page 401 =200 /login; include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_bazarr bazarr4k; proxy_pass http://$upstream_bazarr:6868; } } - I changed the server_name to the correct subdomain for which i obtained a certificate. - Changed the proxy_pass to http://$upstream_bazarr:6868; (as how i have the port setup in unraid) Now I just changed the name of the config to bazarr4k.subdomain.conf since bazarr was already in use did not expect this to work and got a 502 bad gateway. Does anybody run the same or does anybody have an idea on how to do this correctly? Much appreciated, Bleak





