




muslimsteel
Members
-
Joined
-
Last visited
Everything posted by muslimsteel
-
Hello, I am trying to get DNSOMatic to update using DDNSUpdater, but for whatever reason, it is giving me ERROR malformed password. I tried turning on debug logging but all that did was add the config file to the logs and then it shuts down. Am I missing something? My password is 20 characters long and only has one special character in it a "$" sign, wondering if that was an issue. { "provider": "dnsomatic", "host": "*", "username": "***@gmail.com", "password": "***", "ip_version": "ipv4" } I posted this originally in Discussions on the GitHub page but have not got a response there so I thought I might try here. Thanks for the help!
-
That worked perfectly, thanks again for the help!
-
Ok thanks, I had a feeling that was going to be the best path. Will give it a go, thanks for the help and link to the docs! Sent from my iPhone using Tapatalk
-
I was replacing as part of an upgrade process, I re-mounted it under unassigned devices and can see all the data on it, so yes the contents are intact. But when I try to add it to the array it wants to blow it away.
-
Hello, I was going through a routine process of replacing a disk in the array with a different one of the same size, when I started the array back up after swapping the disk, my parity drive suddenly threw a bunch of errors and went into a disabled state which borked the rebuild. So right now the array is running, but is missing a disk (the one I replaced as it couldn't rebuild) and the parity is still disabled. I have put back in the disk that I had in before in hopes that it might be able to come back to normal sans parity but that did not make a difference. Attached is a system report and SMART test of the parity drive. Where do I go from here? I have the drive from before installed now, can I just some how put it back to the way it was before, just with a parity that is failed? Thanks for the help! hulk-diagnostics-20220828-0902.zip hulk-smart-20220828-0855.zip
-
That command paints a much clearer picture of the usage, thank you! Sent from my iPhone using Tapatalk
-
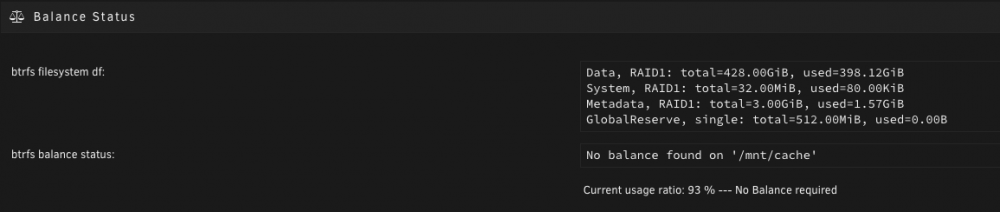
Thanks just to confirm are you referring to this? I saw that and it said Data, RAID1: total=428.00GiB, used=398.12GiB, so with those size indicators, I thought that it was still only using the old drive as that was the size of it. In this scenario though, all three drives in there now have the same data on them (RAID1) correct? Just trying to understand the working of the cache pool better, thanks!
-
So how did you determine that? Just for future reference. Is there a place that I can check that? Thanks.
-
Hello, I was working on replacing my cache drive, but I think I may have done it in an odd way. Before I started I had two 480GB SSDs in there functioning as the Cache pool. I added two 2TB NVMes to the cache pool and let it rebuild/balance. Then later I removed one SSD from the pool. I want to remove the second one as well so I was reading this from the FAQs and I am unsure what cache profile my drives are in. My first instinct after reading that was transfer everything off the cache drive and then remove the second SSD just to be safe, but that would take at least a day or two to transfer everything. So my question is, how can I find out if it is ok to just pull out the second SSD? I attached diagnostics just in case. Thanks! hulk-diagnostics-20220729-1556.zip
-
Just as an FYI, I upgraded to 6.10.3 and then changed the Docker network setting to ipvlan and the server has been stable for over 5 days now. Will continue to monitor, thanks!
-
Yea I did see that, thought it was odd that it has been running pretty stable for a while now and this suddenly popped up. Will check them out more thoroughly and let you know. Thanks.
-
Hello, I have had kernel panics recently about once or twice a week. Googling suggests it could be memory issue (even though I am running ECC RAM) or could be some other issue with docker networking (but nothing has changed there). So I just wanted to post my logs to get a second opinion before doing more troubleshooting. Attached are two diagnostics pulled after the reboot, and the most recent syslog. I don't think the syslog was captured for the first kernel panic, but the most recent one on 7/9/2022 @16:06 local time should be there. Thanks in advance for the help with this! All_2022-7-10-9_8_40.csv hulk-diagnostics-20220710-0917.zip hulk-diagnostics-20220706-0852.zip
-
I am a little confused on this, as when I updated the image initially after @binhex did the first update, the only versions of Java that were included on the container were the following: sh-5.1# ls default default-runtime java-11-openjdk java-17-openjdk java-8-openjdk So I am not understanding why there is a variable for 16 if that is no longer there?
-
I ran into this as well @NLS. It seems that they upgraded Java on the container, so now the new path is: /usr/lib/jvm/java-17-openjdk/bin/java EDIT: I had to change that on all my servers, and then some still wouldn't start, so I rebooted the container and all was well after that.
-
Absolutely, will do!
-
You rock, thank you that worked like a charm!
-
Thanks did that, the error seems a bit different but is still persisting where it won't start up, I am thinking that I may just blow away the DB and start over: 2021-09-23 13:22:51,930 DEBG 'start-script' stderr output: Traceback (most recent call last): File "/opt/crafty/crafty.py", line 311, in <module> 2021-09-23 13:22:51,931 DEBG 'start-script' stderr output: multi.reload_scheduling() File "/opt/crafty/app/classes/multiserv.py", line 93, in reload_scheduling self.reload_user_schedules() File "/opt/crafty/app/classes/multiserv.py", line 112, in reload_user_schedules helper.scheduler(task, svr_obj) File "/opt/crafty/app/classes/helpers.py", line 1306, in scheduler 2021-09-23 13:22:51,931 DEBG 'start-script' stderr output: schedule.every(task.interval).monday.do(mc_server_obj.backup_server).tag('user') 2021-09-23 13:22:51,932 DEBG 'start-script' stderr output: File "/opt/crafty/env/lib/python3.9/site-packages/schedule/__init__.py", line 322, in monday 2021-09-23 13:22:51,932 DEBG 'start-script' stderr output: raise IntervalError('Use mondays instead of monday') schedule.IntervalError: Use mondays instead of monday 2021-09-23 13:22:51,971 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 23132065632560 for <Subprocess at 23132065480272 with name start-script in state RUNNING> (stdout)> 2021-09-23 13:22:51,972 DEBG fd 15 closed, stopped monitoring <POutputDispatcher at 23132065671296 for <Subprocess at 23132065480272 with name start-script in state RUNNING> (stderr)> 2021-09-23 13:22:51,972 INFO exited: start-script (exit status 1; not expected) 2021-09-23 13:22:51,972 DEBG received SIGCHLD indicating a child quit
-
I am not seeing an update to the image available, it says up-to-date currently, unless I am missing something.
-
Thanks for the complement and tip! I will use that going forward. It seems that @galluno may have called out the bug that I hit. Is there any way to recover from that?
-
So it seems after I finally got everything set up and went to create a schedule for backups, it borked the server. I have a feeling the answer is going to be delete the DB and start over, but wanted to confirm if there was another way. This is from the container logs: 2021-09-18 16:41:50,537 DEBG 'start-script' stderr output: Traceback (most recent call last): File "/opt/crafty/crafty.py", line 308, in <module> 2021-09-18 16:41:50,538 DEBG 'start-script' stderr output: multi.reload_scheduling() File "/opt/crafty/app/classes/multiserv.py", line 93, in reload_scheduling self.reload_user_schedules() File "/opt/crafty/app/classes/multiserv.py", line 112, in reload_user_schedules helper.scheduler(task, svr_obj) File "/opt/crafty/app/classes/helpers.py", line 1306, in scheduler 2021-09-18 16:41:50,538 DEBG 'start-script' stderr output: schedule.every(task.interval).monday.do(mc_server_obj.backup_server).tag('user') File "/opt/crafty/env/lib/python3.9/site-packages/schedule/__init__.py", line 302, in monday raise IntervalError('Use mondays instead of monday') schedule.IntervalError: Use mondays instead of monday 2021-09-18 16:41:50,584 DEBG fd 11 closed, stopped monitoring <POutputDispatcher at 22962550325200 for <Subprocess at 22962550324528 with name start-script in state RUNNING> (stdout)> 2021-09-18 16:41:50,584 DEBG fd 15 closed, stopped monitoring <POutputDispatcher at 22962550007648 for <Subprocess at 22962550324528 with name start-script in state RUNNING> (stderr)> 2021-09-18 16:41:50,584 INFO exited: start-script (exit status 1; not expected) 2021-09-18 16:41:50,585 DEBG received SIGCHLD indicating a child quit Thanks for looking.
-
I just had this issue, took a diagnostics file right after it happened. I was working on some files in krusader when suddenly it said the directory did not exist anymore. I went up a level and that one did not exist either. Then I looked at my shares and they were gone. Googled it and came across this post. So I took some diagnostics and then rebooted. Server seems to be ok now, but just seems odd, was wondering if there was anything in the diagnostics that would suggest the problem. Thanks! hulk-diagnostics-20200610-2159.zip
-
@primeval_god Thanks, looks like they might have an issue open for this same thing on GitHub: https://github.com/netdata/netdata/issues/9084
-
I have come across the same issue as above. I originally posted the issue in the Dynamix forum because of the errors that I saw, they looked at my diagnostics and saw the process issue that you are seeing. This is what I originally posted here: And then one of the guys there replied: I have attached my diagnostics if you want to take a look. Going to turn off the netdata container for now and see if I am seeing any more of these issues. Thanks in advance for the support! hulk-diagnostics-20200519-2143.zip
-
Interesting, will check it out in their support thread, thanks!
-
Hello, I hope this is the right place to post this. I have searched and have been unable to find a solution. In the last few days I added a second cache drive, identical to the existing one. I added this to create a cache pool. Since then I noticed occasional weird messages in my email that don't seem to make sense: Subject is: cron for user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null and the body consists of: /bin/sh: fork: retry: Resource temporarily unavailable Typically I get several in a row and then they stop for 12-24 hours. If I leave them it seems to only get worse leading to the server being unresponsive twice now in the last few days. I was able to reboot it from the GUI once, but the second time I had to do a hard boot. I tried uninstalling and reinstalling the SSD Trim plugin but did not seem to make a difference. It came back up without issue and the errors seemed to be cleared, but then about 24 hours later they started happening again. Everything seems to be working ok otherwise, I am not sure what is causing this. One thought I had is that one of the cache drives is on an HBA and the other is connected directly to the motherboard, not sure if that would make a difference. I have attached the diagnostic. Let me know what you guys think, the server has been running great otherwise and I have really been enjoying UNRAID. Thanks for the support! hulk-diagnostics-20200519-2143.zip

