




muslimsteel
Members
-
Joined
-
Last visited
-
Hello, I am trying to get DNSOMatic to update using DDNSUpdater, but for whatever reason, it is giving me ERROR malformed password. I tried turning on debug logging but all that did was add the config file to the logs and then it shuts down. Am I missing something? My password is 20 characters long and only has one special character in it a "$" sign, wondering if that was an issue. { "provider": "dnsomatic", "host": "*", "username": "***@gmail.com", "password": "***", "ip_version": "ipv4" } I posted this originally in Discussions on the GitHub page but have not got a response there so I thought I might try here. Thanks for the help!
-
That worked perfectly, thanks again for the help!
-
Ok thanks, I had a feeling that was going to be the best path. Will give it a go, thanks for the help and link to the docs! Sent from my iPhone using Tapatalk
-
I was replacing as part of an upgrade process, I re-mounted it under unassigned devices and can see all the data on it, so yes the contents are intact. But when I try to add it to the array it wants to blow it away.
-
Hello, I was going through a routine process of replacing a disk in the array with a different one of the same size, when I started the array back up after swapping the disk, my parity drive suddenly threw a bunch of errors and went into a disabled state which borked the rebuild. So right now the array is running, but is missing a disk (the one I replaced as it couldn't rebuild) and the parity is still disabled. I have put back in the disk that I had in before in hopes that it might be able to come back to normal sans parity but that did not make a difference. Attached is a system report and SMART test of the parity drive. Where do I go from here? I have the drive from before installed now, can I just some how put it back to the way it was before, just with a parity that is failed? Thanks for the help! hulk-diagnostics-20220828-0902.zip hulk-smart-20220828-0855.zip
-
That command paints a much clearer picture of the usage, thank you! Sent from my iPhone using Tapatalk
-
Thanks just to confirm are you referring to this? I saw that and it said Data, RAID1: total=428.00GiB, used=398.12GiB, so with those size indicators, I thought that it was still only using the old drive as that was the size of it. In this scenario though, all three drives in there now have the same data on them (RAID1) correct? Just trying to understand the working of the cache pool better, thanks!
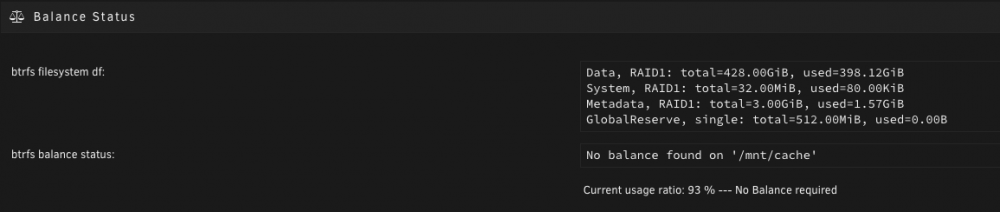
-
So how did you determine that? Just for future reference. Is there a place that I can check that? Thanks.
-
Hello, I was working on replacing my cache drive, but I think I may have done it in an odd way. Before I started I had two 480GB SSDs in there functioning as the Cache pool. I added two 2TB NVMes to the cache pool and let it rebuild/balance. Then later I removed one SSD from the pool. I want to remove the second one as well so I was reading this from the FAQs and I am unsure what cache profile my drives are in. My first instinct after reading that was transfer everything off the cache drive and then remove the second SSD just to be safe, but that would take at least a day or two to transfer everything. So my question is, how can I find out if it is ok to just pull out the second SSD? I attached diagnostics just in case. Thanks! hulk-diagnostics-20220729-1556.zip
-
Just as an FYI, I upgraded to 6.10.3 and then changed the Docker network setting to ipvlan and the server has been stable for over 5 days now. Will continue to monitor, thanks!
-
Yea I did see that, thought it was odd that it has been running pretty stable for a while now and this suddenly popped up. Will check them out more thoroughly and let you know. Thanks.
-
Hello, I have had kernel panics recently about once or twice a week. Googling suggests it could be memory issue (even though I am running ECC RAM) or could be some other issue with docker networking (but nothing has changed there). So I just wanted to post my logs to get a second opinion before doing more troubleshooting. Attached are two diagnostics pulled after the reboot, and the most recent syslog. I don't think the syslog was captured for the first kernel panic, but the most recent one on 7/9/2022 @16:06 local time should be there. Thanks in advance for the help with this! All_2022-7-10-9_8_40.csv hulk-diagnostics-20220710-0917.zip hulk-diagnostics-20220706-0852.zip
-
I am a little confused on this, as when I updated the image initially after @binhex did the first update, the only versions of Java that were included on the container were the following: sh-5.1# ls default default-runtime java-11-openjdk java-17-openjdk java-8-openjdk So I am not understanding why there is a variable for 16 if that is no longer there?
-
I ran into this as well @NLS. It seems that they upgraded Java on the container, so now the new path is: /usr/lib/jvm/java-17-openjdk/bin/java EDIT: I had to change that on all my servers, and then some still wouldn't start, so I rebooted the container and all was well after that.
-
Absolutely, will do!

