LumpyCustard
Members
-
Joined
-
Last visited
Everything posted by LumpyCustard
-
I had a lot of issues with /home/nobody/dbrepair.sh that comes bundled with binhex-plexpass. I think it's extremely confusing to name the script the same as the much more fully featured script found via https://github.com/ChuckPa/DBRepair I ran into a multitude of issues, including the script finishing in <1 second and not actually doing anything, as well as the script running for 20+ hours and achieving nothing aside from generating a gargantuan WAL file in excess of 50GB. I see a lot of complaints on reddit and these forums from people trying to run the "proper" DBRepair script from ChuckPa and not being able to stop the PMS service in binhex-plex / binhex-plexpass and going around in circles. In any case, I want to post what solved my issues after recovering a 250GB backup of my Plex folder after the binhex script failed to yield any results. Opened console for binhex-plexpass Ran kill -15 $(pidof) 'Plex Media Server') about 10 times until watchdog gave up trying to start Plex Downloaded and ran ChuckPa's DBRepair Ran option 911 (deflate/vacuum), which dropped my database from 73GB to 681MB Ran an automatic repair All in all it took about 1.5-2 hours and my database was fully repaired and Plex is running wonderfully again. It would be great if this script was included, or if the container had some kind of stop command to make using ChuckPa's script a bit easier. A tertiary google search for "binhex dbrepair.sh stop plex" shows a lot of people running around in circles trying to fix their DB's. And as an aside I think it would be beneficial to rename the script "binhexdbfix.sh" or some such considering ChuckPa's has been around much longer and is named exactly the same.
-
Back to square one then
-
I did enable mover logging some weeks back for testing purposes, it has now been disabled. This wouldn't be the cause of the shutdown issue would it?
-
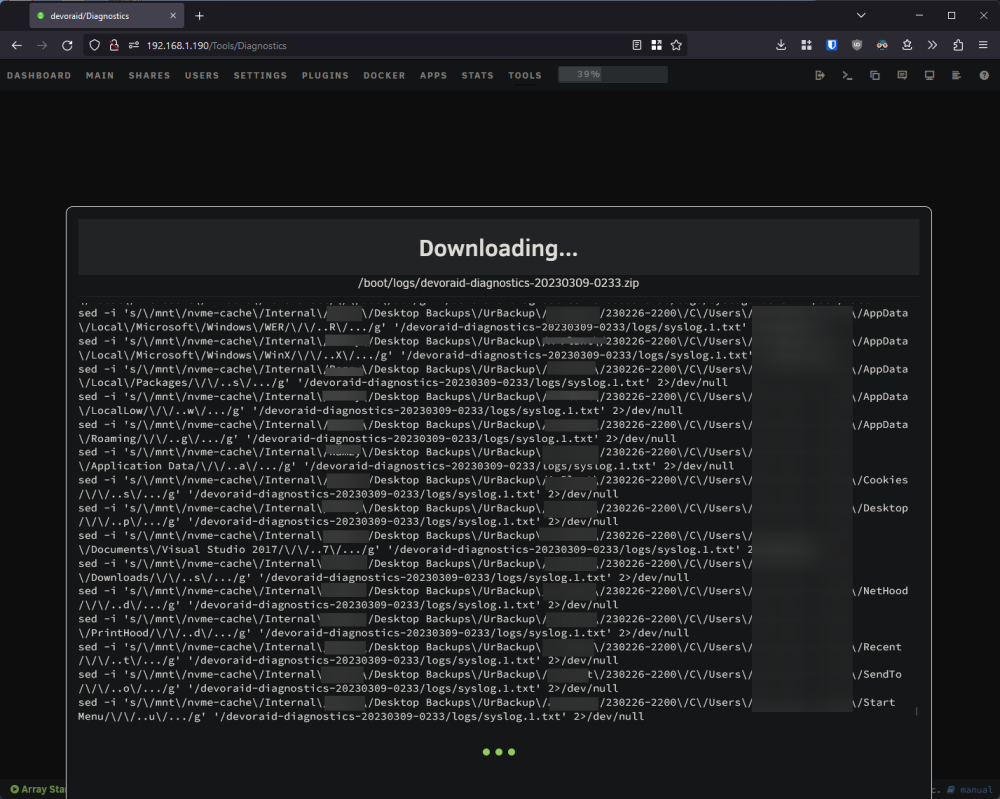
OK i had to stop the diagnostic, after 20+ minutes my browser had reached 32GB of memory usage and things were getting weird. Why is the diagnostic tool killing itself by going through my nvme cache / urbackup folder?
-
I posted a screenshot above. I have generated diagnostics dozens of times and i've never seen it do this before. Urbackup is a docker container i use to handle backups for my personal PC and a friend of mine who backs up over the internet. I've never seen it go through tens of thousands of files to generate a diagnostic before. It's been generating a diagnostic for the last 5 minutes now and it's still going. edit: 15 minutes now and it's still going lol.
-
No, when i boot my server after failing to force shutdown it SOMETIMES says improper shutdown, other times it doesn't. When i generate diagnostics it completes in about 10 seconds. Once the array has started though the diagnostics take a long while to complete as it seems to be going through thousands of files in my Urbackup directory.
-
Since moving to an Intel based server and utilising QSV/NVENC i opted to retire my Server 2016 VM. I haven't done anything funky with IOMMU groups either. When i WAS using a VM it was simply named "Windows Server 2016" I currently have no VM's in Unraid and have disabled the VM service.
-
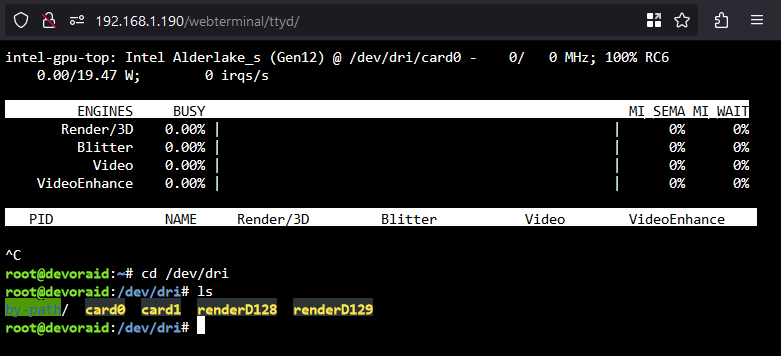
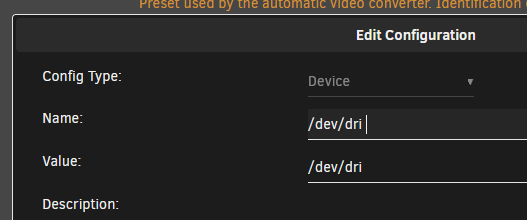
SOLUTION, found on arch linux forums. You will first need to open terminal and run intel_gpu_top to confirm what your iGPU's identifier is (card0 or card1). In the below screenshot my iGPU is card1/renderD129, which means my Nvidia GPU (by process of elimination) is card0/renderD128. Next edit your docker container and enable advanced view. Under "Extra Parameters" enter the following command. In my case i am directing card1 to card0 and renderD129 to renderD128 in order to stop docker from targeting my Nvidia GPU when trying to run QSV operations. --device=/dev/dri/card1:/dev/dri/card0 --device=/dev/dri/renderD129:/dev/dri/renderD128 Once you've saved, run a test and you should see activity on your iGPU.

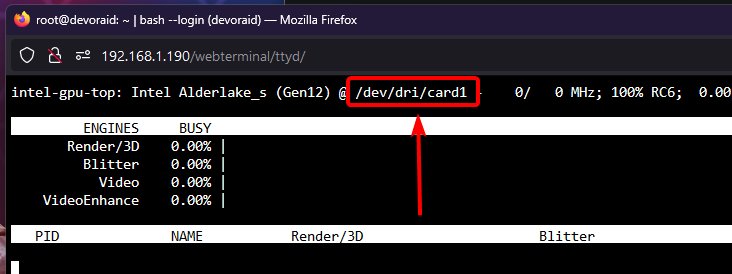
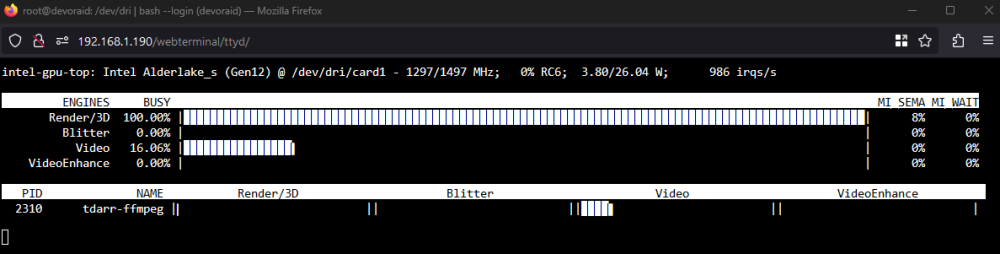
-
My unraid server used to run on a 3600X/B450 combo about a month ago and I experienced an error where both graceful AND forced shutdown failed and the server would just infinitely hang on terminal. I can type into terminal and interact with Unraid but it just can't shutdown. My only option is to power off the system by holding the power button. I sold off my parts and moved to a 12700/Z690 combo and I am still experiencing the same problem. When I connect to my KVM i see the following Waiting up to 90 seconds for graceful shutdown... [...] Forcing shutdown... Starting diagnostics collection... sh: -c: line 1: unexpected EOF while looking for matching `" Diagnostics attached. I created them immediately after my server booted up.devoraid-diagnostics-20230306-2008.zip Can someone point me toward what is causing shutdown to hang? Thanks.
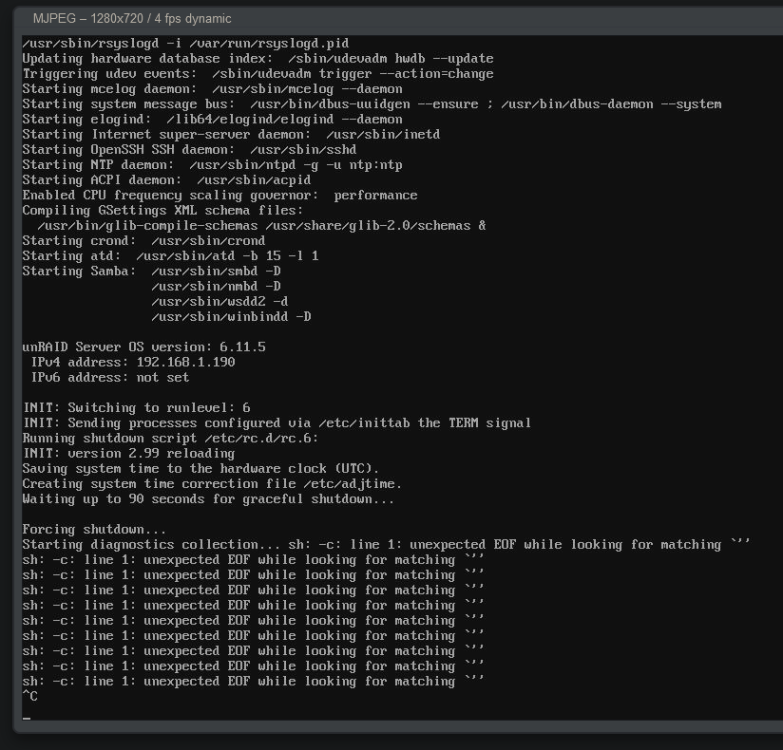
-
I've never directly accessed the pool (by pointing it at the actual directory on the invidual disk) or modified my docker image location since building this server so i'm not entirely sure what happened. I've been having issues with unBLANACE reporting issues with file permissions with containers such as krusader, nginx, and others, despite running new permissions to fix the issue unBALANCE continues to complain about permission issues. Most recently when my cache failed (due to to running in RAID0 mode), i used unBALANCE to completely empty my cache after getting the SSD professionally repaired. After moving all the files and creating a 4 disk cache in mirror mode with new NVMe drives i noted that mover was refusing to move some files back into the NVMe cache, again -- mover left some /appdata/ files for krusader, nginx and some others in the disk array rather than moving them to the nvme cache. I've run and re-run new permissions multiple times and it just doesn't want to fix the issue so i'm at a loss. I ended up manually moving the files myself using the unraid file browser plugin.
-
Thanks, i'll give it a try. And yes the NVMe cache is a 4 disk array so it's "protected", hence why i noticed the difference between the shares that live on my array and the shares that are using Prefer Cache. I'll wait for the rebuild to finish in 12 hours and give it a try. Thanks again.
-
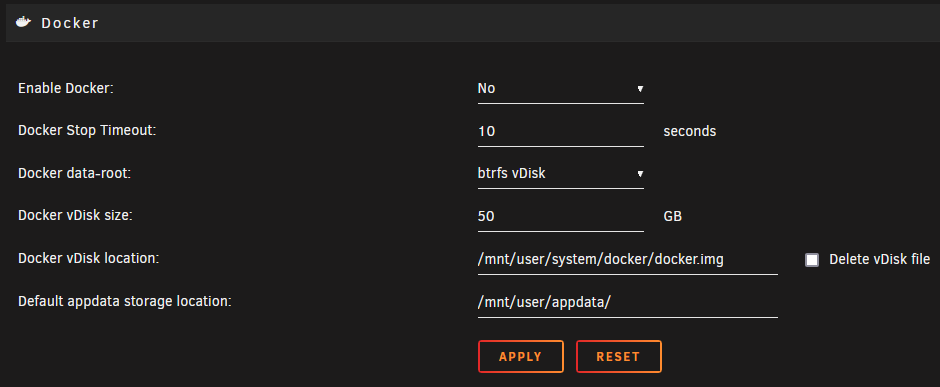
I recently upgraded my Unraid box and while using unBALANCE I noticed that my docker.img is living in two different locations. One of the docker.img files is on disk13, the other is in my NVMe cache. Disk13: NVMe cache: Both of the Docker vDisk files are 53.7GB despite Docker settings being configured for a max of 50GB. The docker image file location is set to: /mnt/user/system/docker/docker.img I am in the process of upgrading 2 disks in my array and so the shares that are on that array are marked as "unprotected" while the array rebuilds. I note that even though /system/ is set to prefer NVMe cache, and even though docker.img is on my NVMe cache, Unraid thinks that it's unprotected because the img file is supposedly existing in 2 locations at once. How do i correct this issue? Do i just modify the vDisk location and manually point it to /mnt/nvme-cache/system/docker/docker.img then delete the other file on Disk13? Thanks.



-
Thank you SO MUCH for this. Your post resolved issues with a small production server I created for a family friend running 11 individual Windows 10 VM's. Before (all VM's sitting on login screen, completely idle) After:

-
In the same boat, can't get an answer on this. Did you end up fixing it?
-
CPU: i7 12700 (non K) Mobo: Gigabyte Z690 Gaming X DDR4 GPU: Nvidia 2080 Super Unraid: 6.11.5 Bios: Latest, set to iGPU as main/boot GPU. PiKVM connected to motherboard HDMI port. I've got NVENC working in Plex, TDARR, Unmanic, and Handbrake but I can't seem to get my iGPU to function in any docker container. I've installed Intel GPU TOP. modprobe i915 returns nothing, so no errors there. intel_gpu_top shows the iGPU is detected. Navigating to /dev/dri shows card0 and card1. I have tried starting containers with extra parameter "--device=/dev/dri", and i have also tried adding a device to the container (though this seems outdated and no longer necessary?) Every single container, Plex, TDARR, Unmanic, and Handbrake fail to utilise the iGPU. Plex ignores it and falls back to CPU transcode. TDARR and Unmanic fly through transcodes at 30,000FPS and fail -- intel_gpu_top shows 0% utilisation. Handbrake fails to initialise QSV. What am I doing wrong here? Is my PiKVM causing issues? Are you meant to boot headlessly in order for iGPU to work properly in Unraid? I have not seen anyone make reference to "card1" when reading through other threads across reddit and unraid, mostly every screenshot and tutorial i've seen only shows card0. Any help would be appreciated. Thanks.

-
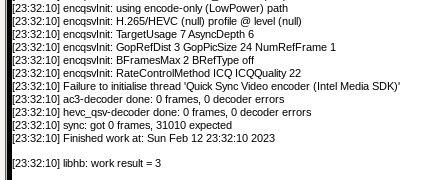
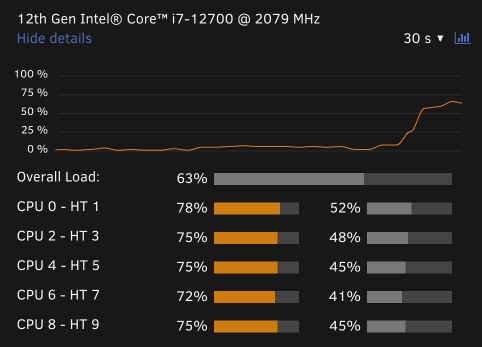
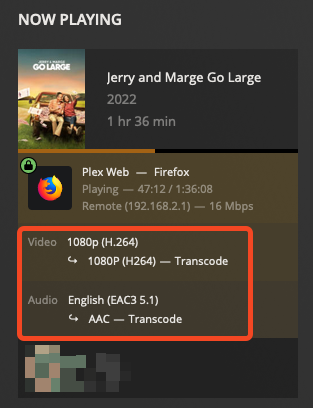
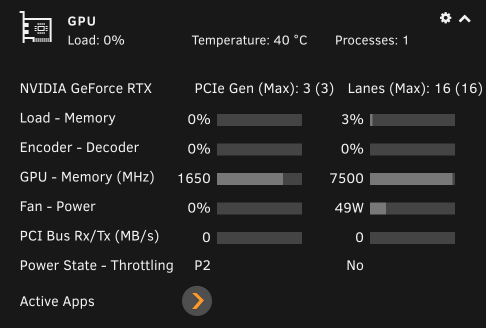
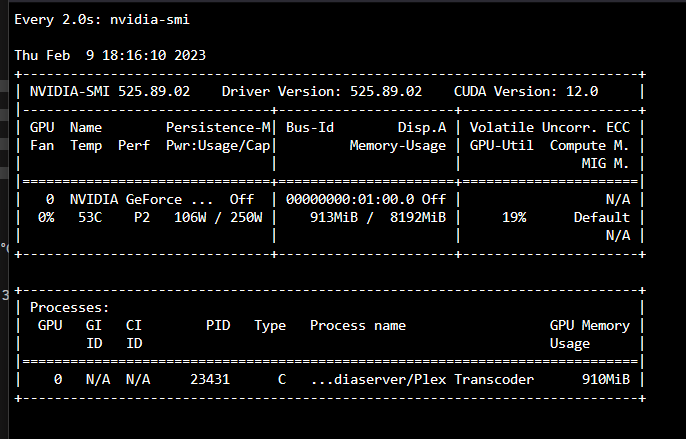
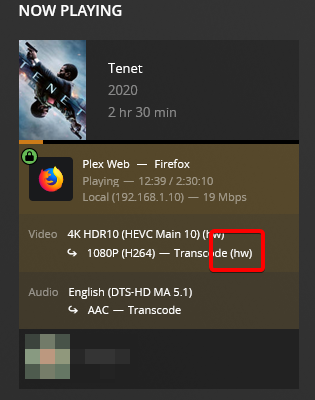
edit: Upon further investigation it seems like if i'm transcoding a 1080P movie, Plex leans on the CPU, but when I transcode a 4K movie, Plex uses the GPU. This is reproducible with any movie i try. Is this expected behaviour in Plex? ----------------- I'm having difficulty getting Plex hardware transcoding to work despite the GPU being detected and used by Plex. I migrated my Plex %appdata% folder from a Windows VM to Binhex Plexpass and everything worked fine after pointing it to the new media locations and syncing. - I've installed the 'nvidia driver' plugin and downloaded the latest driver. - The driver has a HWID. - I have copied the ID from 'nvidia driver' and pasted it into Binhex Plexpass container settings. - I have set --runtime=nvidia in 'extra parameters' - I have set 'nvidia_visible_devices' to 'all' - I have enabled hardware acceleration under Transcoder settings. - I have confirmed transcoder temporary directory is working (i can see transcoding files in the directory i have mapped on my cache) - When i launch Plex the the GPU Statistics plugin shows that my GPU is being utilised by Plex. - When i launch terminal and type "watch nvidia-smi" i can see the GPU is being used by Plex. However with all that working properly and looking good, when I watch a movie and set Plex to transcode (rather than direct file stream), my CPU gets slammed and Plex does not show "transcode (hw)" in the now playing section. Instead it just shows "transcode", which means that it's not HW transcoding. Anyone have an idea? Has this been caused by transferring my Windows based %appdata% folder into Docker? To be clear i took the 'Plex Media Server' folder from Windows in %appdata%, deleted all of the folders in Binhex Plex in /appdata/, and copied it in. Thanks.
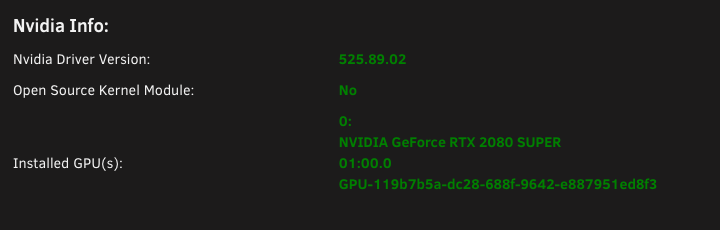

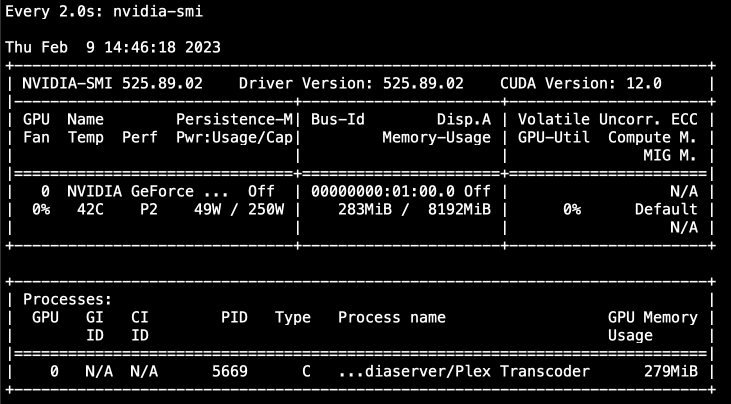



-
Just thought i'd update this post. I got my drive professionally repaired by a data recovery company -- they corrected an issue on the PCB of the m.2 SSD drive. Despite starting and stopping the array dozens of times, creating new cache pools, swapping the drive order around in UNRAID and so on, when i inserted the drive back in and selected the drives, my cache pool came back to life and all the data was intact -- docker started, my VM's launched, etc. I am in the process of breaking down my cache pool now -- i've purchased 4 new NVMe's and i'll be rebuilding it with redundancy as well as ditching the 2.5" drives i had mixed in with NVMe drives.

-
Looks like i'm screwed and my only lifeline will be fixing the dead NVME drive via data recovery if that even works to begin with. Serves me right for going with 0 redundancy cache pool. Appreciate all your assistance.
-
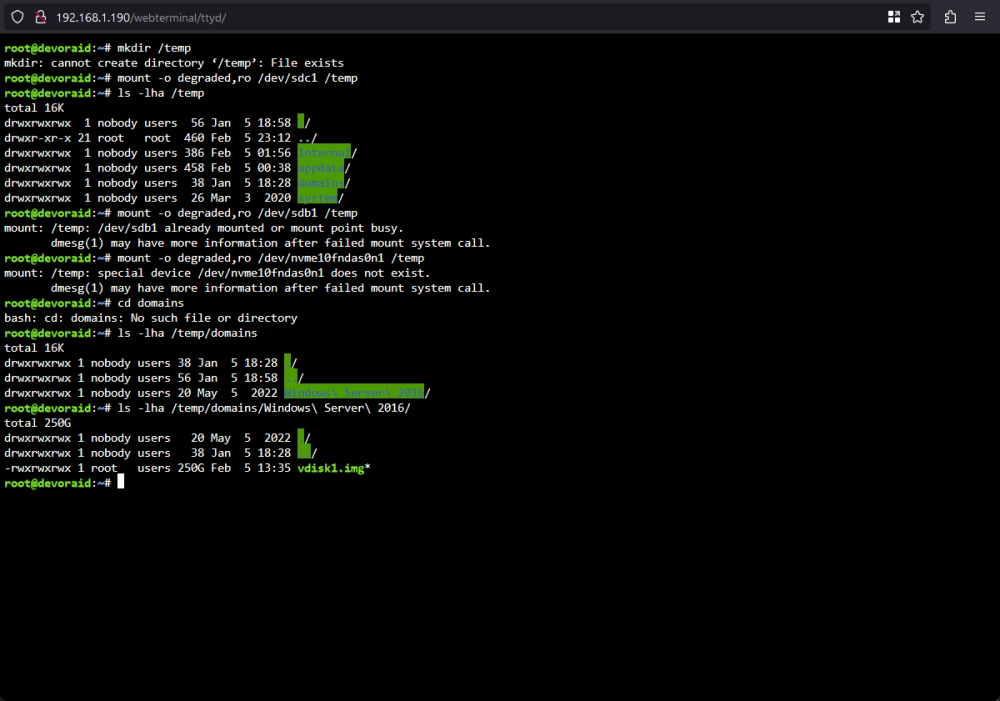
Thank you, was attempting to follow that but i wasn't sure what to point toward as the mount point. sdc1? edit: ok seems like there is some data in there. Just need to enable SFTP and copy it out i suppose?
-
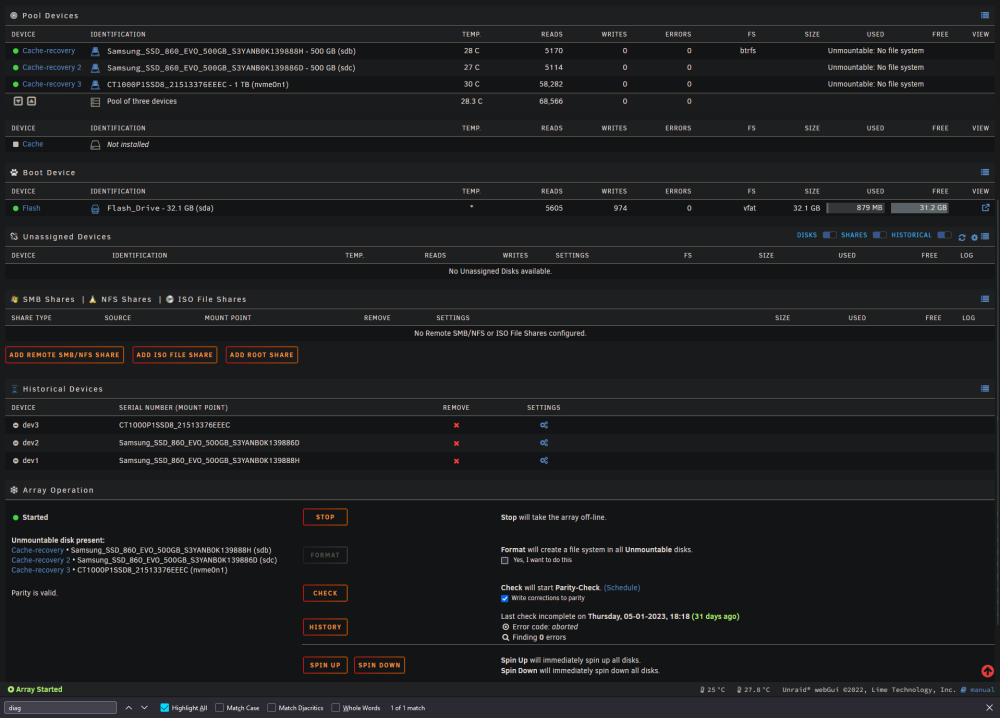
I ended up creating a new pool just to make sure i wasn't doubling up. See attached. This is what i'm looking at now. Thank you for your help thus far. devoraid-diagnostics-20230205-2312.zip
-
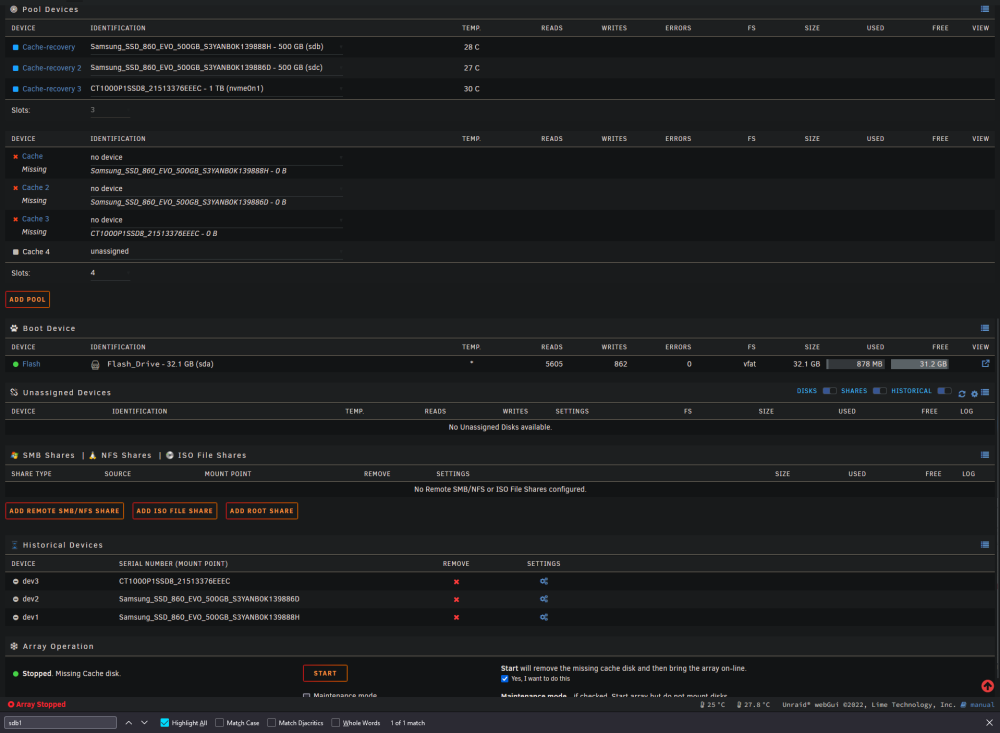
OK just to make sure i understand since i'm stressing about the data, you want me to take the array offline, create an entirely new pool, then assign the 3 alive SSD's to that new pool then start the array in maintenance mode? This is what i'm looking at:
-
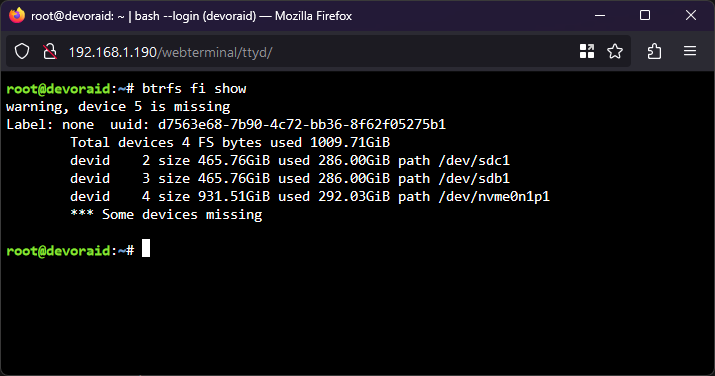
Thank you so much for the reply. Here is the output (array not running)
-
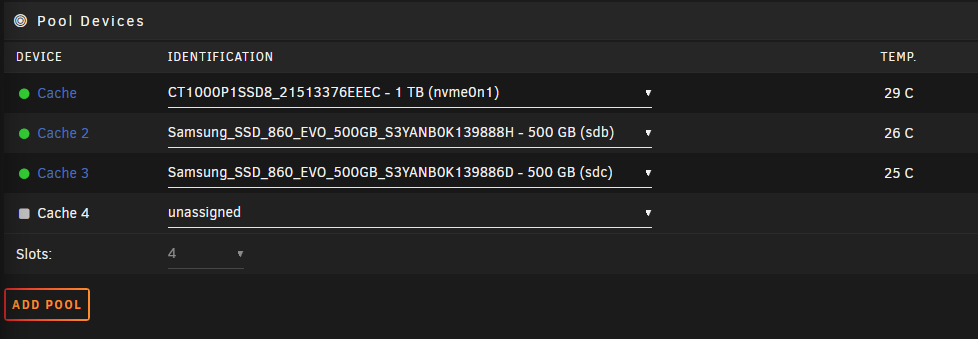
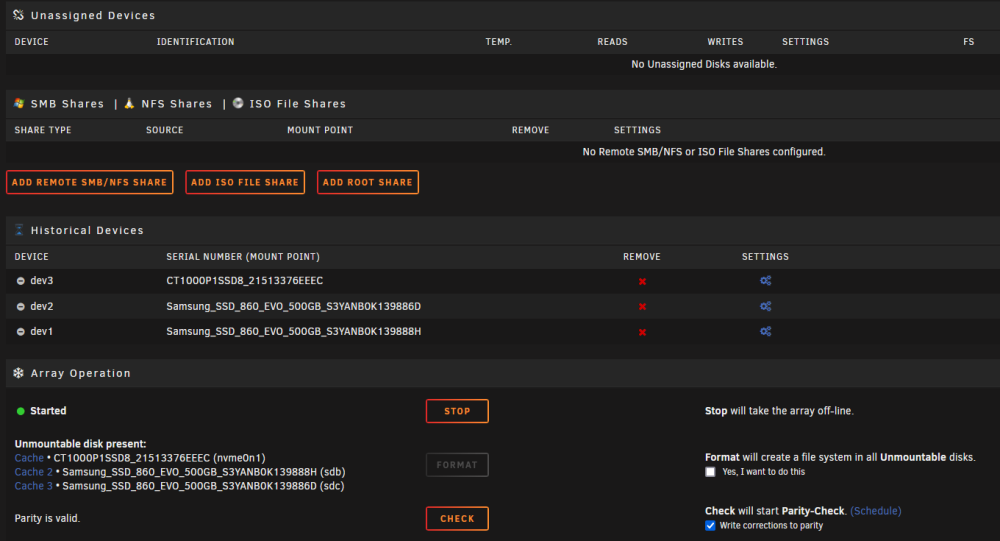
I upgraded my server today -- Replaced the motherboard, CPU, and added additional RAM. When i came home i shut down UNRAID gracefully, however after a full graceful shutdown my server LED was still on and the fans were running. I checked the monitor connected to my server and it was completely blank and unresponsive. After waiting 15 minutes i force shut down the server by holding the power button. I upgraded the server and put everything back together, booted into BIOS, updated to the latest firmware as of today (Gigabyte Z690 Gaming X - BIOS version F22), enabled virtualisation on the CPU, turned on XMP, and booted into UNRAID. Unfortunately 1 of my 4 cache drives was not detected. I reseated everything, rebooted multiple times, but it's simply not detected, even in BIOS. I'm wondering if the forced shutdown corrupted the drive's firmware. I inserted the drive into an NVMe caddy and connected it to my Windows PC and it's unable to read the drive, stating that it is uninitialized. I haven't attempted to initialize it because i don't want to nuke the data that's on it. I connected a known working NVMe from UNRAID to the same caddy and it was immediately detected and showed a healthy 1TB partition in Windows. I've tried cleaning the gold contacts on the NVMe with electrical PCB cleaner as well, but that did not work. My cache was set up as a 4 drive BTRFS pool (balanced? striped? not sure of the terminology) I attempted following advice from some of the moderators on this forum after hours of searching, including starting the array with no cache drives to forget the config then starting it again with the drives, but unfortunately my cache drives/shares are not mountable. I got a bunch of errors from UNRAID about missing shares and files, and my Docker containers and VM's are all missing. My "pool devices" was set to 4 devices, and UNRAID was complaining that a drive was missing / config not valid. I made the mistake of clicking "3 slots", then it immediately dropped the drive from the configuration. When i selected "4" slots again, UNRAID was no longer complaining about invalid configuration. I'm unsure how a BTRFS pool works, but if it is striped then i assume my data is not recoverable. I am willing to pay for data recovery from a local reputable data recovery company that specialises in flash storage, however i want to know: A) If anything is currently salvageable. My hope is that the 250GB virtual machine lived on one SSD and that i'd be able to recover it by mounting that SSD and copying the virtual disk file. My docker containers are backed up, all i care about is my virtual machine. B) If i do take the NVMe to a data recovery company and they manage to fix it, have I completely nuked my cache drive by starting it with 3 drives instead of 4? I DID NOT choose the option to format when starting the array. Diagnostics attached. Thank you in advance. devoraid-diagnostics-20230205-2026.zip
-
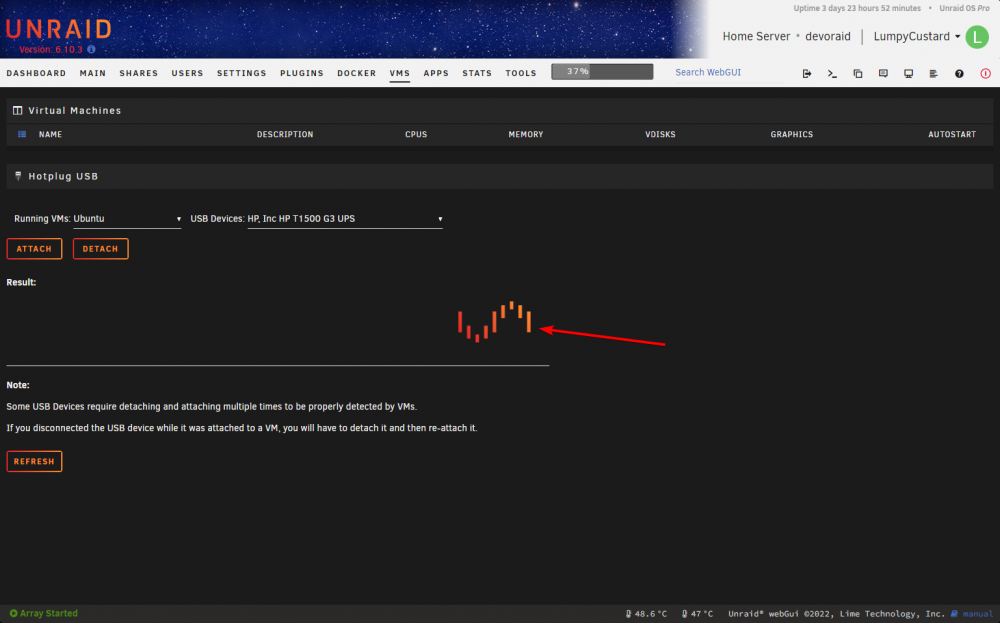
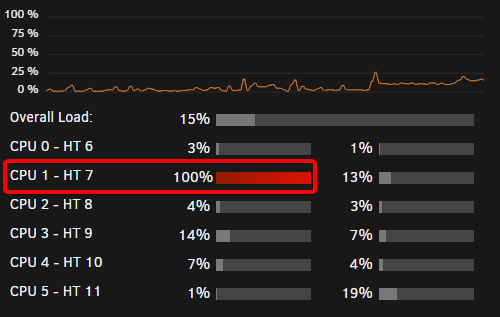
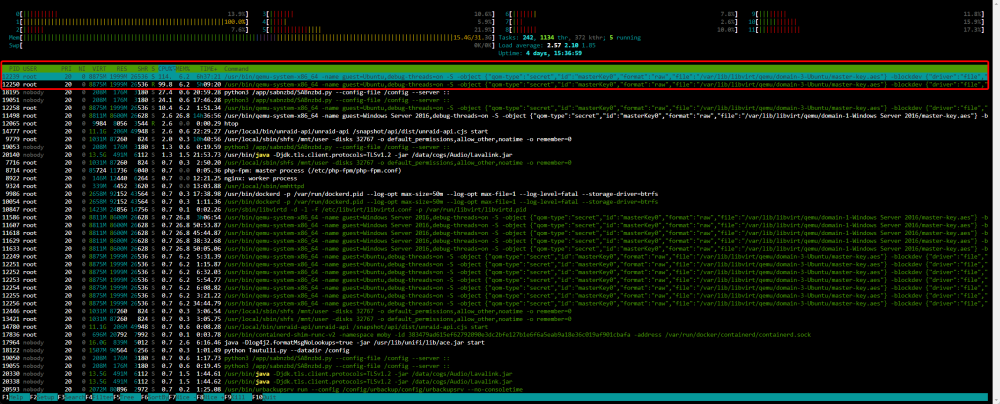
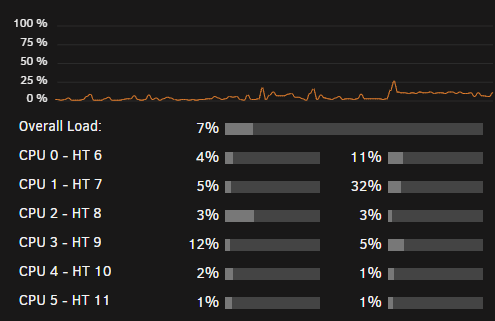
As you can see in the gif my adblocker is disabled. Clearing cookies does not resolve. I note that one of my CPU's cores is permanently pinned once this issue starts: After killing the below highlighted process with the SIGKILL command, the VM tab begins to work properly again. And after killing it my CPU is no longer pinned.
-
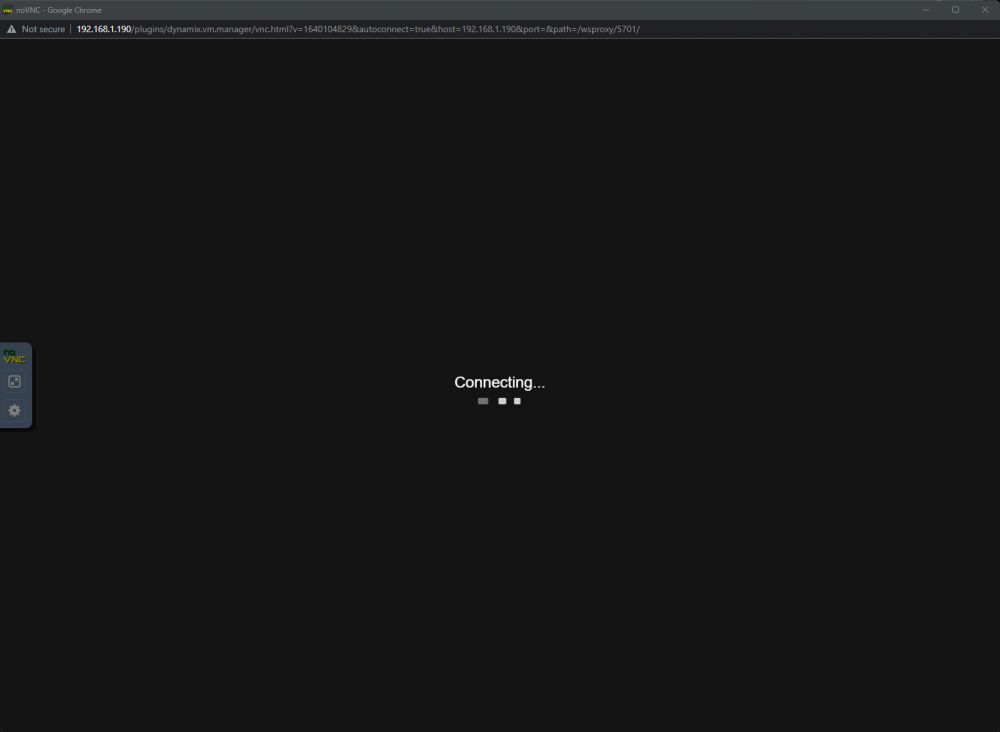
Add me to the list of people experiencing this issue. I recently assisted a friend with purchasing a new server and got him onto Unraid. While remotely configuring his brand new server and completely stock installation of Unraid (no plugins, no major configuration changes outside of setting a password), I noted that his VM tab would become unresponsive and load for minutes on end. Dashboard, Main, Shares, Users, Settings, Plugins, Docker, Apps, Stats, Tools -- all load instantly, but VM tab loads for ages and ages. The VM's are running fine, they can be remoted into using SSH and RDP, but the VM tab itself just doesn't load. I've begun to experience this on my own installation of Unraid as well which has been deployed for over a year. If i wait 5+ minutes the VM page contents appears (with no VM's visible) and i'm left with the Unraid loading symbol in the centre of the screen. After a few more minutes the VM's appear, but if i try to connect via VNC i get a "Connecting..." screen which i've never seen before. The only way to "fix" the issue is by rebooting the Unraid host. And again, to be clear, my friend is running a stock installation of Unraid with NOTHING installed on it, not a single docker image or plugin. All i did was create a blank Windows 10 VM with no GPU passthrough or any other advanced settings. Video: