




tlrmcknz
Members
-
Joined
-
Last visited
-
@adent042 Did you ever determine which disk this was from? I have the exact same issue, but have had it with two different HBAs. And it's the exact same count/sectors for me. kernel: md: recovery thread: PQ corrected, sector=1574961048 kernel: md: recovery thread: PQ corrected, sector=1574961056 kernel: md: recovery thread: PQ corrected, sector=1574961064 kernel: md: recovery thread: PQ corrected, sector=1574961072 kernel: md: recovery thread: PQ corrected, sector=1574961080
-
There is no question...I'm following up on our short conversation starting with the post I linked that there looks like a bug in folder exclusion.
-
Referring to this post: Where I had an exclusion of "/mnt/user/appdata/data" but that was causing "/mnt/user/appdata/ms-sql-server/data" to be excluded from the backup.
-
Update on this: Checked the backup after removing that path exclusion and it had the data folder as expected. So looks like there's a bug in the path matching, applying the data subfolder exclusion to all other folders.
-
Thanks for the reply. It slipped my mind because I thought it was empty, but interestingly enough I have this: Maybe some path matching issue?

-
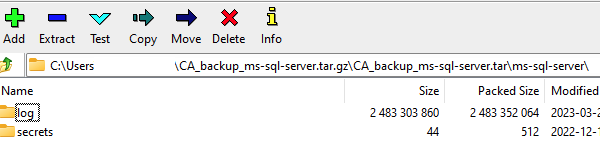
I seem to be having an issue with entire appdata subfolders missing. [03.04.2023 03:03:06] Stopping MS-SQL-Server... done! (took 1 seconds) ... [03.04.2023 03:12:40] Backing Up: ms-sql-server [03.04.2023 03:13:38] Verifying Backup ms-sql-server ... [03.04.2023 03:24:53] Starting MS-SQL-Server... (try #1) done! But inside the archive, there's no ms-sql-server\data folder, yet one exists on the filesystem and has the same permissions as ms-sql-server\log (which does get backed up in the archive properly) Filesystem: drwxrwxr-x 1 root root 28 Dec 12 14:30 ./ drwxrwxrwx 1 nobody users 2076 Mar 10 15:46 ../ drwxrwxr-x 1 root root 832 Mar 21 11:37 data/ drwxrwxr-x 1 root root 5234 Apr 10 03:27 log/ drwxrwxr-x 1 root root 22 Dec 12 14:30 secrets/ Archive: Any idea what's going on here?
-
Added the extended self test log to the first post just for reference, but it failed at 40%. Guess it's time to replace. Are there any steps to take to validate emulated data first? Or what's there now is all there is, and just need to disk swap and rebuild?
-
Thanks, doing that now. Would this the expected amount of time for it to finish? Extended self-test routine recommended polling time: 957 minutes.
-
Would like a second opinion on the health of this drive and whether or not I should rebuild it onto itself. Currently doing a read check on the array after an unplanned power outage. The read check stopped on it's own at about 50% and that's when I noticed the disk was disabled. I resumed the read check and it's now at about 58%. Attached is the short test log. The extended test seemed to still be at 10% after 30-60mins, so I didn't let it complete or run it again (yet). Also attached diagnostics that logged when the parity check errors started occuring. Thanks muchly. ryzen-smart-20220201-1447.zip ryzen-diagnostics-20220201-1514.zip ryzen-smart-20220201-2221.zip
-
Did you ever make any headway on this? Saw something extremely similar today for me: Short hardware list: MB: ASRock B450 Pro4 CPU: AMD Ryzen 7 1800X GPU1: Nvidia GeForce GTX 1650 My BIOS cstate = DISABLED Slightly truncated kernel log from remote syslog: general protection fault: 0000 [#1] SMP NOPTI CPU: 3 PID: 21050 Comm: nzbget Tainted: P W O 4.19.107-Unraid #1 Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./B450 Pro4, BIOS P4.20 06/18/2020 RIP: 0010:nf_nat_setup_info+0x365/0x666 [nf_nat] Code: ed 75 23 45 8b 17 48 8d 7c 24 58 b9 0a 00 00 00 48 8d 74 24 30 f3 a5 41 f6 c2 01 0f 85 c4 00 00 00 e9 25 02 00 00 8a 44 24 56 <41> 38 45 46 74 15 4d 8b ad 98 00 00 00 4d 85 ed 74 c7 49 81 ed 98 hrtimer: interrupt took 2467865 ns RSP: 0018:ffff88881e6c36d8 EFLAGS: 00010206 general protection fault: 0000 [#1] SMP NOPTI CPU: 3 PID: 21050 Comm: nzbget Tainted: P W O 4.19.107-Unraid #1 Hardware name: To Be Filled By O.E.M. To Be Filled By O.E.M./B450 Pro4, BIOS P4.20 06/18/2020 RIP: 0010:nf_nat_setup_info+0x365/0x666 [nf_nat] Code: ed 75 23 45 8b 17 48 8d 7c 24 58 b9 0a 00 00 00 48 8d 74 24 30 f3 a5 41 f6 c2 01 0f 85 c4 00 00 00 e9 25 02 00 00 8a 44 24 56 <41> 38 45 46 74 15 4d 8b ad 98 00 00 00 4d 85 ed 74 c7 49 81 ed 98 hrtimer: interrupt took 2467865 ns RSP: 0018:ffff88881e6c36d8 EFLAGS: 00010206 RAX: ffff88813f034906 RBX: ffffffff81e91080 RCX: 0000000086ee2de1 RDX: ffff8887d1180000 RSI: 0000000045680e5d RDI: 0000000087f6373f RBP: ffff88881e6c37b0 R08: ffff88881e6c3708 R09: ffffffff81c8a6e0 R10: ffff8884c1518388 R11: 0000000000000000 R12: 0000000000000000 R13: 04fa37f2f9f462ee R14: ffff888050b64b40 R15: ffff88881e6c37c4 FS: 0000153f3737bb20(0000) GS:ffff88881e6c0000(0000) knlGS:0000000000000000 CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 CR2: 0000153f36cc6fd0 CR3: 00000005711c0000 CR4: 00000000003406e0 Call Trace: ...

