




spamalam
Members
-
Joined
-
Last visited
Everything posted by spamalam
-
Short, sweet and very helpful. Thank you very much.
-
I've had a bout of instability recently, and I'm pretty sure my Areca SAS controller is a problem and preventing a boot. I have a spare SAS controller, but found my supermicro server won't boot if i put the same brand of sas controller in (it gets to the sas controller bootscreen and gets confused and holts during controller POST). I have 24x SATA drives powered by 6x SAS ports (2x on the supermicro, 4x on the areca) connected to a SAS backplane, and 4 additional drives on the mainboard SATA ports. To solve this I figured I would by a 4 or 6 port SAS controller and disable onboard and pull the areca. I have a few questions: 1) Will I hit any bandwidth problems with a single controller over a single PCI-E 3.0 port to a SAS backplane? I'm assuming I'm still going to be limited by the SATA drive speed here. Would it be better for more than one controller or is all sharing the same channel anyway? 2) If i'm running in IT mode, is there any point in a battery on the card? Particularly under a heavy write? 3) I found this: NEW LSI Logic Controller Card 05-25699-00 9305-24i 24-Port SAS 12Gb/s pci-e 3.0 Does this work well with Unraid? It has no battery, considering 2, is this a problem? 4) With LSI, in passthrough/jbod, I am assuming i can switch out to any controller/direct sata and its not doing any fruity logical volumes work when flashed to IT. Thanks.
-
I've been having some fun, I have several SSDs and recently found that several files have input/output error when read. I have tried xfs_repair but the files aren't moved / dealt with. I've rebooted with the array stopped (since this concerns cache only), and mounted the disk: root@xxx-xxx:/path/Games.1952.1080p.BluRay.Remux.AVC.FLAC.2.0-HiFi# mv Games.1952.BluRay.Remux.1080p.AVC.FLAC.2.0-HiFi.mkv /mnt/downloads/completes/sabnzbd/movies/completes/Games.1952.1080p.BluRay.Remux.AVC.FLAC.2.0-HiFi/ mv: error reading 'Games.1952.BluRay.Remux.1080p.AVC.FLAC.2.0-HiFi.mkv': Input/output error [ 294.995043] xfs filesystem being mounted at /mnt/disks/cache supports timestamps until 2038 (0x7fffffff) [ 483.438612] ata4.00: exception Emask 0x0 SAct 0x600000 SErr 0x0 action 0x0 [ 483.438616] ata4.00: irq_stat 0x40000008 [ 483.438622] ata4.00: failed command: READ FPDMA QUEUED [ 483.438628] ata4.00: cmd 60/00:a8:10:7d:07/02:00:21:00:00/40 tag 21 ncq dma 262144 in res 41/40:00:30:7e:07/00:02:21:00:00/00 Emask 0x409 (media error) <F> [ 483.438630] ata4.00: status: { DRDY ERR } [ 483.438632] ata4.00: error: { UNC } [ 483.439080] ata4.00: supports DRM functions and may not be fully accessible [ 483.442157] ata4.00: supports DRM functions and may not be fully accessible [ 483.444552] ata4.00: configured for UDMA/133 [ 483.444569] sd 5:0:0:0: [sdd] tag#21 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s [ 483.444573] sd 5:0:0:0: [sdd] tag#21 Sense Key : 0x3 [current] [ 483.444576] sd 5:0:0:0: [sdd] tag#21 ASC=0x11 ASCQ=0x4 [ 483.444580] sd 5:0:0:0: [sdd] tag#21 CDB: opcode=0x28 28 00 21 07 7d 10 00 02 00 00 [ 483.444584] blk_update_request: I/O error, dev sdd, sector 554139184 op 0x0:(READ) flags 0x80700 phys_seg 2 prio class 0 [ 483.444606] ata4: EH complete [ 483.444729] ata4.00: Enabling discard_zeroes_data [ 483.762728] ata4.00: exception Emask 0x0 SAct 0x2000000 SErr 0x0 action 0x0 [ 483.762731] ata4.00: irq_stat 0x40000008 [ 483.762737] ata4.00: failed command: READ FPDMA QUEUED [ 483.762743] ata4.00: cmd 60/08:c8:b0:7e:07/00:00:21:00:00/40 tag 25 ncq dma 4096 in res 41/40:08:b0:7e:07/00:00:21:00:00/00 Emask 0x409 (media error) <F> [ 483.762746] ata4.00: status: { DRDY ERR } [ 483.762748] ata4.00: error: { UNC } [ 483.762996] ata4.00: supports DRM functions and may not be fully accessible [ 483.765512] ata4.00: supports DRM functions and may not be fully accessible [ 483.767510] ata4.00: configured for UDMA/133 [ 483.767524] sd 5:0:0:0: [sdd] tag#25 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s [ 483.767528] sd 5:0:0:0: [sdd] tag#25 Sense Key : 0x3 [current] [ 483.767531] sd 5:0:0:0: [sdd] tag#25 ASC=0x11 ASCQ=0x4 [ 483.767534] sd 5:0:0:0: [sdd] tag#25 CDB: opcode=0x28 28 00 21 07 7e b0 00 00 08 00 [ 483.767538] blk_update_request: I/O error, dev sdd, sector 554139312 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [ 483.767552] ata4: EH complete [ 483.767653] ata4.00: Enabling discard_zeroes_data [ 483.932594] ata4.00: exception Emask 0x0 SAct 0x20000 SErr 0x0 action 0x0 [ 483.932597] ata4.00: irq_stat 0x40000008 [ 483.932602] ata4.00: failed command: READ FPDMA QUEUED [ 483.932608] ata4.00: cmd 60/08:88:b0:7e:07/00:00:21:00:00/40 tag 17 ncq dma 4096 in res 41/40:08:b0:7e:07/00:00:21:00:00/00 Emask 0x409 (media error) <F> [ 483.932610] ata4.00: status: { DRDY ERR } [ 483.932612] ata4.00: error: { UNC } [ 483.932858] ata4.00: supports DRM functions and may not be fully accessible [ 483.935448] ata4.00: supports DRM functions and may not be fully accessible [ 483.937495] ata4.00: configured for UDMA/133 [ 483.937509] sd 5:0:0:0: [sdd] tag#17 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 cmd_age=0s [ 483.937513] sd 5:0:0:0: [sdd] tag#17 Sense Key : 0x3 [current] [ 483.937516] sd 5:0:0:0: [sdd] tag#17 ASC=0x11 ASCQ=0x4 [ 483.937519] sd 5:0:0:0: [sdd] tag#17 CDB: opcode=0x28 28 00 21 07 7e b0 00 00 08 00 [ 483.937523] blk_update_request: I/O error, dev sdd, sector 554139312 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 [ 483.937537] ata4: EH complete [ 483.937632] ata4.00: Enabling discard_zeroes_data I feel like really there's a bad block and these files need to be hidden/removed (the disk is an SSD), but I was expecting xfs_repair /dev/sdd1 to take care of that ¯\_(ツ)_/¯ beyonder-nas-diagnostics-20220105-1734.zip
-
As soon as I get settled in a location and some time, I'll stop, clear my logs, then upgrade and share everything. It hit the second start script in the web logs then nothing, and it wouldn't respond to shutdown, kill, etc. Had to do a force kill.
-
Latest builds seem to be unbootable, and now it refuses to shutdown and is now a hung process. Seems to hang on the second start script. Not even responding to docker stop <containerid>
-
Okay thanks, will wait for it to finish and stop radarr and sonarr so they don't redownload
-
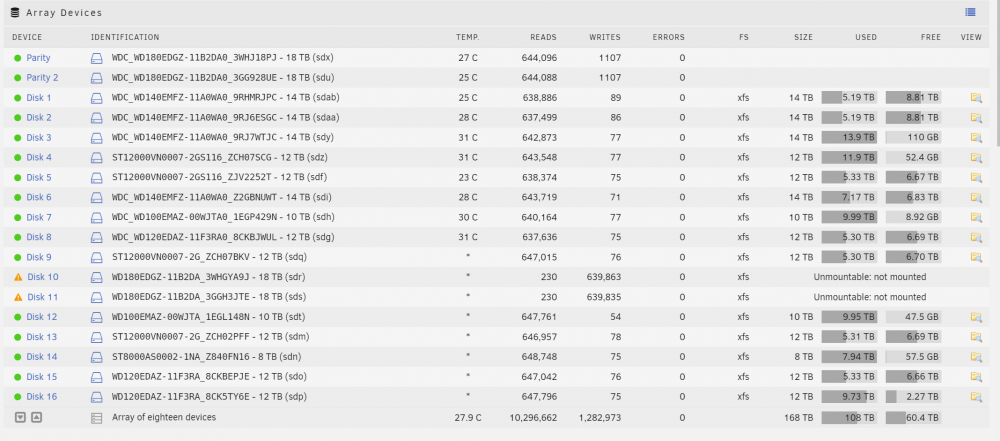
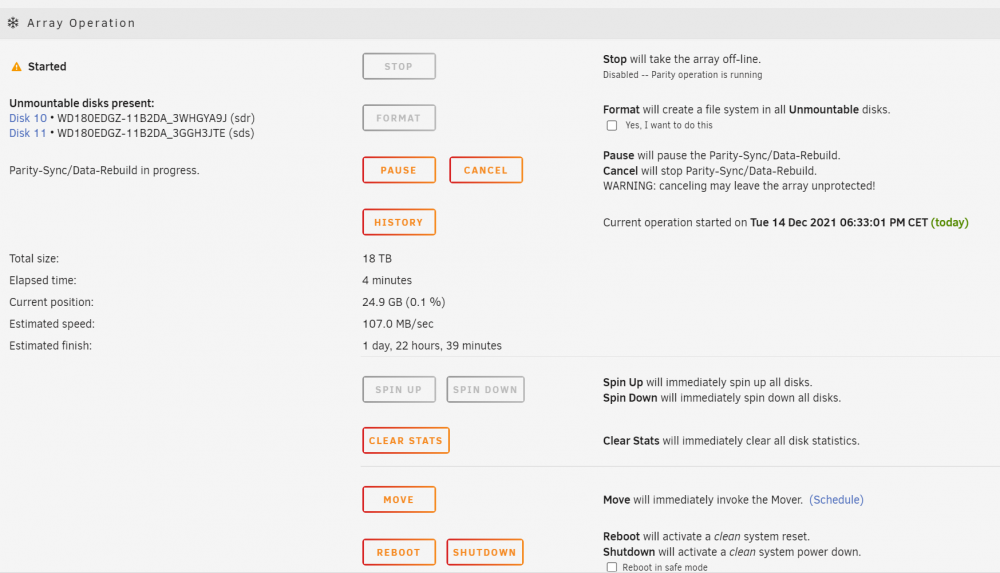
I'm currently going through a data rebuilt, where I expect the contents to be emulated but unraid seems to be misbehaving. root@beyonder-nas:/mnt# ls -l /mnt/ total 0 drwxrwxrwx 19 nobody users 291 Oct 28 01:12 apps/ drwxrwxrwx 7 nobody users 73 Dec 14 18:15 cache/ drwxrwxrwx 7 nobody users 89 Dec 14 18:15 disk1/ drwxrwxrwx 13 nobody users 188 Dec 14 18:15 disk12/ drwxrwxrwx 5 nobody users 58 Dec 14 18:15 disk13/ drwxrwxrwx 13 nobody users 188 Dec 14 18:15 disk14/ drwxrwxrwx 5 nobody users 58 Dec 14 18:15 disk15/ drwxrwxrwx 8 nobody users 105 Dec 14 18:15 disk16/ drwxrwxrwx 4 nobody users 42 Dec 14 18:15 disk2/ drwxrwxrwx 12 nobody users 170 Dec 14 18:15 disk3/ drwxrwxrwx 10 nobody users 138 Dec 14 18:15 disk4/ drwxrwxrwx 9 nobody users 121 Dec 14 18:15 disk5/ drwxrwxrwx 11 nobody users 154 Dec 14 18:15 disk6/ drwxrwxrwx 13 nobody users 188 Dec 14 18:15 disk7/ drwxrwxrwx 4 nobody users 42 Dec 14 18:15 disk8/ drwxrwxrwx 9 nobody users 126 Dec 14 18:15 disk9/ drwxrwxrwt 2 nobody users 40 Dec 14 18:05 disks/ drwxrwxrwx 5 nobody users 47 Dec 14 02:24 plex/ drwxrwxrwt 2 nobody users 40 Dec 14 18:05 remotes/ drwxrwxrwx 1 nobody users 89 Dec 14 18:15 user/ drwxrwxrwx 1 nobody users 89 Dec 14 18:15 user0/ Disk 10 and Disk 11 are missing, I was expecting the emulated volumes to be mounted with my files from parity. In syslog it looks like the emulated filesystem might be broken? Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (405): mkdir -p /mnt/disk10 Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (406): mount -t xfs -o noatime /dev/md10 /mnt/disk10 Dec 14 18:32:55 beyonder-nas kernel: XFS (md10): Mounting V5 Filesystem Dec 14 18:32:55 beyonder-nas kernel: XFS (md10): Starting recovery (logdev: internal) Dec 14 18:32:55 beyonder-nas kernel: XFS (md10): Metadata CRC error detected at xfs_agf_read_verify+0x26/0x54 [xfs], xfs_agf block 0x1 Dec 14 18:32:55 beyonder-nas kernel: XFS (md10): Unmount and run xfs_repair Dec 14 18:32:55 beyonder-nas kernel: XFS (md10): First 128 bytes of corrupted metadata buffer: Dec 14 18:32:55 beyonder-nas kernel: 00000000: 58 41 47 46 00 00 00 01 00 00 00 00 0a ea 85 1b XAGF............ Dec 14 18:32:55 beyonder-nas kernel: 00000010: 00 86 c4 83 00 86 99 f5 00 00 00 00 00 00 00 01 ................ Dec 14 18:32:55 beyonder-nas kernel: 00000020: 00 00 00 01 00 00 00 00 00 00 00 00 00 00 00 03 ................ Dec 14 18:32:55 beyonder-nas kernel: 00000030: 00 00 00 04 00 13 05 34 00 0d 6c 0c 00 00 00 00 .......4..l..... Dec 14 18:32:55 beyonder-nas kernel: 00000040: f3 41 8d 35 53 e0 47 71 81 0b 39 b3 87 33 9c a9 .A.5S.Gq..9..3.. Dec 14 18:32:55 beyonder-nas kernel: 00000050: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Dec 14 18:32:55 beyonder-nas kernel: 00000060: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Dec 14 18:32:55 beyonder-nas kernel: 00000070: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Dec 14 18:32:55 beyonder-nas kernel: XFS (md10): metadata I/O error in "xfs_read_agf+0x6d/0xa3 [xfs]" at daddr 0x1 len 1 error 74 Dec 14 18:32:55 beyonder-nas root: mount: /mnt/disk10: mount(2) system call failed: Structure needs cleaning. Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (406): exit status: 32 Dec 14 18:32:55 beyonder-nas emhttpd: /mnt/disk10 mount error: not mounted Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (407): umount /mnt/disk10 Dec 14 18:32:55 beyonder-nas root: umount: /mnt/disk10: not mounted. Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (407): exit status: 32 Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (408): rmdir /mnt/disk10 Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (409): mkdir -p /mnt/disk11 Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (410): mount -t xfs -o noatime /dev/md11 /mnt/disk11 Dec 14 18:32:55 beyonder-nas kernel: XFS (md11): Metadata CRC error detected at xfs_sb_read_verify+0x10e/0x158 [xfs], xfs_sb block 0xffffffffffffffff Dec 14 18:32:55 beyonder-nas kernel: XFS (md11): Unmount and run xfs_repair Dec 14 18:32:55 beyonder-nas kernel: XFS (md11): First 128 bytes of corrupted metadata buffer: Dec 14 18:32:55 beyonder-nas kernel: 00000000: 58 46 53 42 00 00 10 00 00 00 00 01 05 ef ff f3 XFSB............ Dec 14 18:32:55 beyonder-nas kernel: 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ Dec 14 18:32:55 beyonder-nas kernel: 00000020: 9d cc 23 71 ff 3b 49 50 9d 7f ae fc d6 7b 75 81 ..#q.;IP.....{u. Dec 14 18:32:55 beyonder-nas kernel: 00000030: 00 00 00 00 20 00 00 05 00 00 00 00 00 00 00 60 .... ..........` Dec 14 18:32:55 beyonder-nas kernel: 00000040: 00 00 00 00 00 00 00 61 00 00 00 00 00 00 00 62 .......a.......b Dec 14 18:32:55 beyonder-nas kernel: 00000050: 00 00 00 01 0e 8e 05 f3 00 00 00 12 00 00 00 00 ................ Dec 14 18:32:55 beyonder-nas kernel: 00000060: 00 07 47 02 b4 b5 02 00 02 00 00 08 00 00 00 00 ..G............. Dec 14 18:32:55 beyonder-nas kernel: 00000070: 00 00 00 00 00 00 00 00 0c 09 09 03 1c 00 00 05 ................ Dec 14 18:32:55 beyonder-nas kernel: XFS (md11): SB validate failed with error -74. Dec 14 18:32:55 beyonder-nas root: mount: /mnt/disk11: mount(2) system call failed: Structure needs cleaning. Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (410): exit status: 32 Dec 14 18:32:55 beyonder-nas emhttpd: /mnt/disk11 mount error: not mounted Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (411): umount /mnt/disk11 Dec 14 18:32:55 beyonder-nas root: umount: /mnt/disk11: not mounted. Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (411): exit status: 32 Dec 14 18:32:55 beyonder-nas emhttpd: shcmd (412): rmdir /mnt/disk11 What happened was i had a loose cable so had to stop the rebuild and replug it in, when i rebooted the parity process started again from zero. I have the original disks, but all the files from the emulated system seem to have gone. Do i need to wait for a parity rebuild and then do some kind of repair?
-
tl;dr Is there a good CPU and Motherboard combo that has 4x SAS ports, and ideally .m2, etc. for a Plex server? I am getting a bit worried about the age of my dual xeon server, its doing well but I started to notice some CRC UDMA errors on the onboard SATA and now SAS drives which makes me think that there's an issue brewing. I also seem to have lost power to the management port. I don't have access to the server to check until a few weeks but I'm reluctant to power cycle without physical access. Also want to check for condensation or anything else in the setup. I had got some CPU errors but it was power related and fixed that quite some time back. At the moment I have the following setup: When it works it's great (apart from Sabnzbd post-process time is horrendously slow), but it's a bit old (2012 motherboard and cpus, 2010 sas) which makes me worried about hardware failure. I have a server case that takes 12 SAS drives (i have mostly shucked slower drives), and 4x SATA attached SSD. What would be nice is a more modern Intel that can handle the 4k transcoding, etc. I also would like to retire the areca as i feel like I'm playing with fire there given the age. Budget would be 'reasonable', since its CPU/Motherboard/RAM/maybe a SAS card I'd expect it to not be more than 1k euros but I have been known to choose the 'top' model when given a choice
-
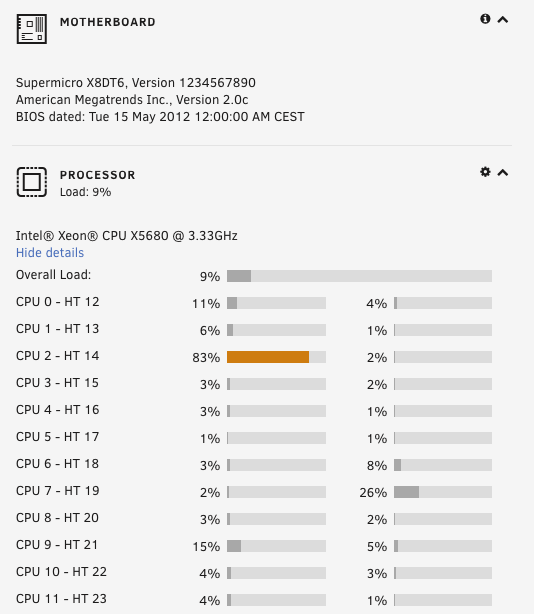
Hi, I'm wondering if someone can help. I'm being hit by incredibly slow unrar performance. I have some unrar actions that seem to be incredibly slow: root@beyonder-nas:/mnt/cache/downloads/sabnzbd/movies/completes# ps -ef | grep unrar nobody 12767 22961 0 10:35 ? 00:00:15 [unrar] <defunct> nobody 15296 22961 0 Oct24 ? 00:00:04 /usr/sbin/unrar x -vp -idp -scf -o+ -p- /downloads/American.Horror.Story.S09E09.Final.Girl.1080p.AMZN.WEB-DL.DD+5.1.H.264-AJP69/e0es2oakQoWkawaae0DvzN48TV.part01.rar /completes/tv/completes/_UNPACK_American.Horror.Story.S09E09.Final.Girl.1080p.AMZN.WEB-DL.DD+5.1.H.264-AJP69/ nobody 19565 22961 0 Oct24 ? 00:00:02 /usr/sbin/unrar x -vp -idp -scf -o+ -p- /downloads/The.Baby.of.Macon.1993.1080p.BluRay.x264-nikt0/75639703d605cb75783e2b0aec984fde.part01.rar /completes/movies/completes/_UNPACK_The.Baby.of.Macon.1993.1080p.BluRay.x264-nikt0/ root 21995 20089 0 12:23 pts/3 00:00:00 grep unrar nobody 23331 22961 0 10:57 ? 00:00:23 /usr/sbin/unrar x -vp -idp -scf -o+ -p- /downloads/The.Box.2009.Bluray.1080p.DTSHR5.1.x264.dxva-FraMeSToR/OAK2VnG5cqOXOXpDst50mft31c.part001.rar /completes/movies/completes/_UNPACK_The.Box.2009.Bluray.1080p.DTSHR5.1.x264.dxva-FraMeSToR/ nobody 24707 22961 0 Oct24 ? 00:00:16 /usr/sbin/unrar x -vp -idp -scf -o+ -p- /downloads/The.Seventh.Day.2021.1080p.Bluray.DTS-HD.MA.5.1.x264-EVO/401e446e9aaa2996da53d095d384931e.part01.rar /completes/movies/completes/_UNPACK_The.Seventh.Day.2021.1080p.Bluray.DTS-HD.MA.5.1.x264-EVO/ nobody 25939 22961 0 Oct24 ? 00:00:01 /usr/sbin/unrar x -vp -idp -scf -o+ -p- /downloads/American.Horror.Story.S09E07.The.Lady.in.White.REPACK.1080p.AMZN.WEB-DL.DD+5.1.H.264-AJP69/dCnVqHk50rhBFDj6d6v6uSOn40cAU2f1AbJY.part01.rar /completes/tv/completes/_UNPACK_American.Horror.Story.S09E07.The.Lady.in.White.REPACK.1080p.AMZN.WEB-DL.DD+5.1.H.264-AJP69/ nobody 29901 22961 0 Oct24 ? 00:00:00 /usr/sbin/unrar x -vp -idp -scf -o+ -p- /downloads/American.Horror.Story.S09E06.PROPER.1080p.WEB.H264-METCON/2TCryetkVyUD4RCs97otDw.part01.rar /completes/tv/completes/_UNPACK_American.Horror.Story.S09E06.PROPER.1080p.WEB.H264-METCON/ root@beyonder-nas:/mnt/cache/downloads/sabnzbd/movies/completes# date Mon Oct 25 12:23:29 CEST 2021 Unrar has always been quite slow, but this seems to be taking the mickey a bit. I set off a colossal amount of downloads so everything is stuck direct unpacking, unraring and post-processing. It very slowly processes but based on those times, some of the unrar actions are over 12hrs? My setup is on two disks outside of the array, so caching shouldn't be playing into it. Both the download disk and the cache disk are Samsung SSD EVO. root@beyonder-nas:/mnt/cache/downloads/sabnzbd/movies/completes# df -h Filesystem Size Used Avail Use% Mounted on rootfs 32G 1.1G 31G 4% / devtmpfs 32G 0 32G 0% /dev tmpfs 32G 0 32G 0% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 13M 116M 10% /var/log /dev/sda1 3.8G 1.1G 2.7G 28% /boot overlay 32G 1.1G 31G 4% /lib/modules overlay 32G 1.1G 31G 4% /lib/firmware /dev/sdb1 1.9T 794G 1.1T 43% /mnt/apps <-- SSD outside of array /dev/sdc1 1.9T 79G 1.8T 5% /mnt/plex /dev/md3 13T 13T 56G 100% /mnt/disk3 /dev/md4 11T 11T 19G 100% /mnt/disk4 /dev/md5 11T 4.9T 6.1T 45% /mnt/disk5 /dev/md6 13T 6.6T 6.2T 52% /mnt/disk6 /dev/md7 9.1T 9.1T 5.6G 100% /mnt/disk7 /dev/md8 11T 4.9T 6.1T 45% /mnt/disk8 /dev/md9 11T 4.9T 6.1T 45% /mnt/disk9 /dev/md10 7.3T 7.3T 13G 100% /mnt/disk10 /dev/md11 7.3T 7.3T 7.0G 100% /mnt/disk11 /dev/md12 9.1T 9.1T 14G 100% /mnt/disk12 /dev/md13 11T 4.9T 6.1T 45% /mnt/disk13 /dev/md14 7.3T 7.3T 44G 100% /mnt/disk14 /dev/md15 11T 4.9T 6.1T 45% /mnt/disk15 /dev/md16 11T 8.9T 2.1T 82% /mnt/disk16 /dev/sde1 1.9T 1.5T 393G 79% /mnt/cache <-- SSD cache disk, not a share. shfs 168T 108T 60T 65% /mnt/user0 shfs 168T 108T 60T 65% /mnt/user Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2021-10-17 21:19:49.997687 [info] Host is running unRAID 2021-10-17 21:19:50.037897 [info] System information Linux e4b9d99f5353 5.10.28-Unraid #1 SMP Wed Apr 7 08:23:18 PDT 2021 x86_64 GNU/Linux 2021-10-17 21:19:50.082427 [info] OS_ARCH defined as 'x86-64' 2021-10-17 21:19:50.126310 [info] PUID defined as '99' 2021-10-17 21:19:50.373103 [info] PGID defined as '100' 2021-10-17 21:19:50.493928 [info] UMASK defined as '000' 2021-10-17 21:19:50.536380 [info] Permissions already set for '/config' 2021-10-17 21:19:50.586917 [info] Deleting files in /tmp (non recursive)... 2021-10-17 21:19:53.008359 [info] Starting Supervisor... 2021-10-17 21:19:53,482 INFO Included extra file "/etc/supervisor/conf.d/sabnzbd.conf" during parsing 2021-10-17 21:19:53,482 INFO Set uid to user 0 succeeded 2021-10-17 21:19:53,490 INFO supervisord started with pid 7 2021-10-17 21:19:54,493 INFO spawned: 'sabnzbd' with pid 65 2021-10-17 21:19:54,495 INFO spawned: 'shutdown-script' with pid 66 2021-10-17 21:19:54,495 INFO reaped unknown pid 8 (exit status 0) 2021-10-17 21:19:55,497 INFO success: sabnzbd entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2021-10-17 21:19:55,497 INFO success: shutdown-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2021-10-19 12:52:31,465 DEBG 'sabnzbd' stderr output: 2021-10-19 12:52:31,463::WARNING::[nzbstuff:919] Unwanted Extension in file RARBG_DO_NOT_MIRROR.exe (Fear.the.Walking.Dead.S07E02.1080p.WEB.H264-GGWP[rarbg]-xpost) 2021-10-23 11:44:16,899 DEBG 'sabnzbd' stderr output: 2021-10-23 11:44:16,899::WARNING::[nzbstuff:919] Unwanted Extension in file RARBG_DO_NOT_MIRROR.exe (The.Walking.Dead.World.Beyond.S02E01.Konsekans.REPACK.1080p.AMZN.WEBRip.DDP5.1.x264-NTb[rarbg]-xpost) 2021-10-24 20:19:23,481 DEBG 'sabnzbd' stderr output: 2021-10-24 20:19:23,432::WARNING::[nzbstuff:908] Pausing duplicate NZB "Rurouni.Kenshin.The.Final.2021.1080p.BluRay.REMUX.AVC.TrueHD.7.1-TayTO.nzb" 2021-10-25 10:31:40,551 DEBG 'sabnzbd' stderr output: 2021-10-25 10:31:40,545::WARNING::[nzbstuff:908] Pausing duplicate NZB "Zone.414.2021.1080p.AMZN.WEBRip.DDP5.1.x264-AR.nzb" 2021-10-25 10:38:29,836 DEBG 'sabnzbd' stderr output: 2021-10-25 10:38:29,834::WARNING::[nzbstuff:908] Pausing duplicate NZB "Cruising.1980.1080p.BluRay.X264-AMIABLE.nzb" System doesn't appear to be doing much, occasionally there's a single core cpu processing. Attaching some screens on the setup incase there's some flag. The download and complete folders are on different disks, but both are SSD and my understanding is that since its an unrar it will be just as efficient, if not more so going across disks (i.e. read from one, write to another).


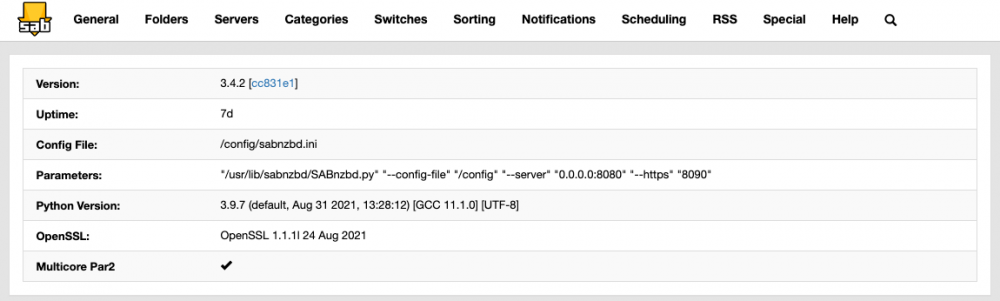
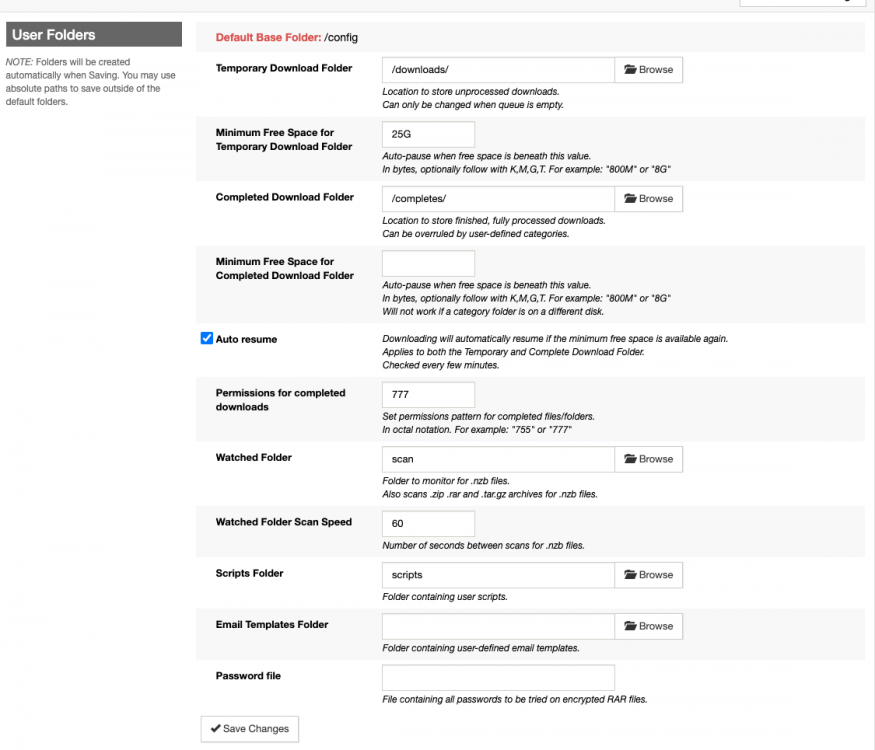
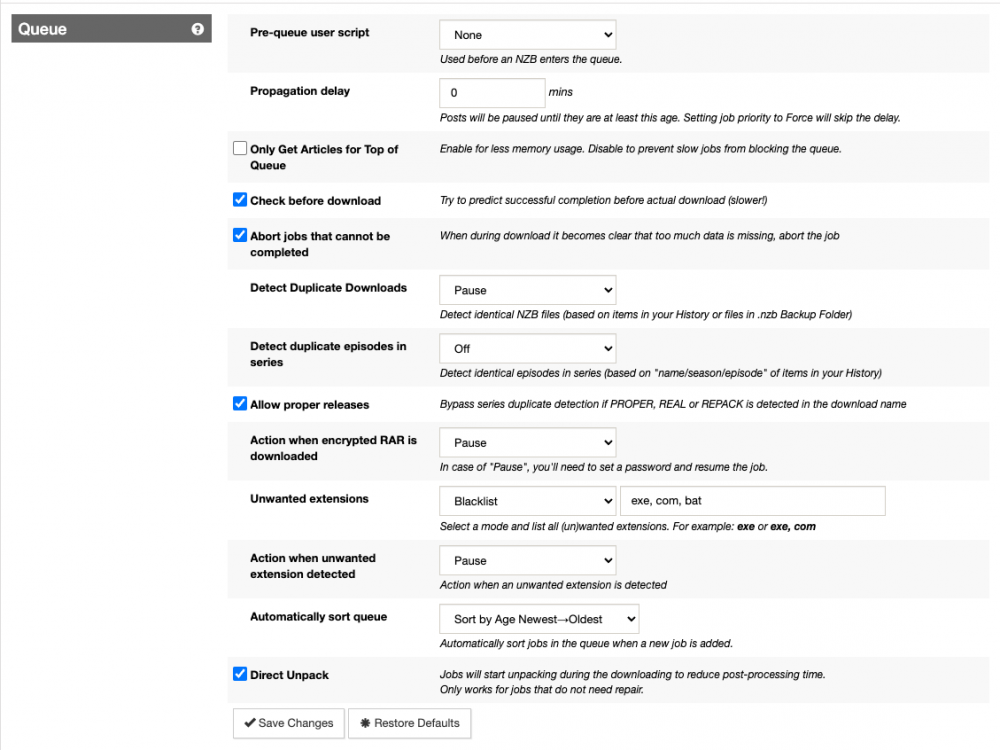
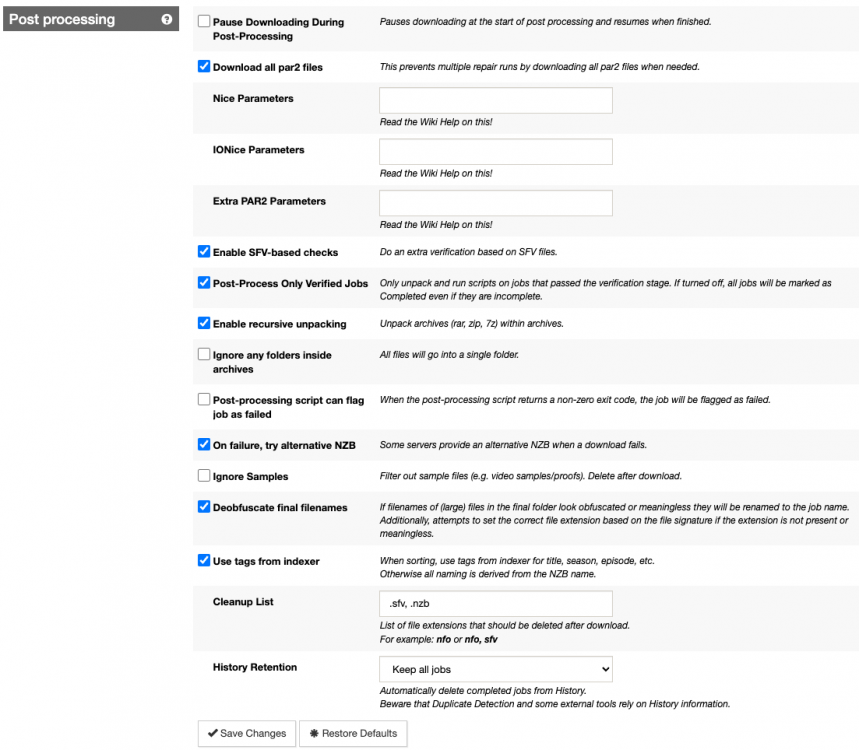

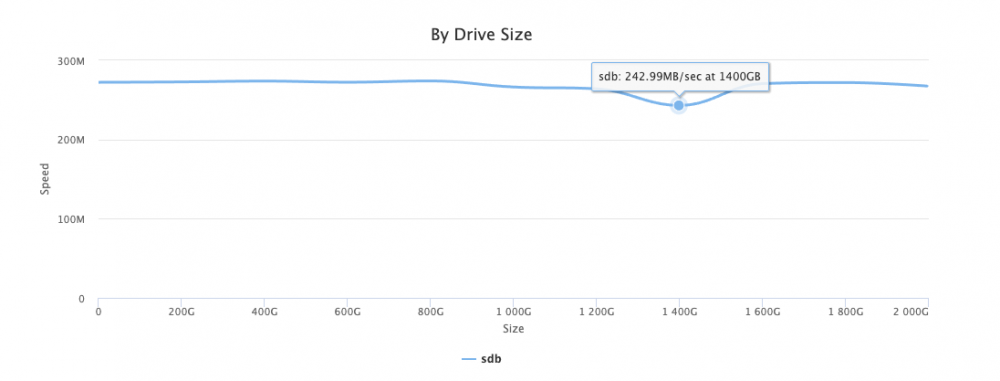
-
Ah, so the lack of post read could mean that maybe something didn't get overwritten correctly, although unlikely? Nice, thanks for the feedback, I'll do a single clear cycle. Takes a bit longer but no worries.
-
Nice. Erase or clear, or either?
-
This plugin is great, I have 3x18TB on preclear and 3x4TB on erase. I have a general question on erase vs clear: I understand erase writes over the entire disk with random junk, whilst clear writes a series of bits to the disk that make it ready for unraid to quickly format when you add to the array. How many erase cycles do you think is necessary for a drive that may have had say a passport photo or something 'private' but not ultra secret? I am running two erase cycles on the 4TB and I intend to ebay them. Would you consider this enough? In my mind, for consumer level a format makes it obfuscated but possible to pick up files and filenames, a single write across everything makes it hard, and two would mean at best you can get metadata without taking it to a forensics lab. Is this sound or would you prescribe more or less erase cycles?
-
Thanks this procedure worked great, I used unbalance to distribute data, I precleared the new parity disks, then I hit new config (you can put the disks in any order so i ordered them by disk slot), then removed the 6x 4TB, assigned the 14TB parity disks to data lots, 18TB to parity, reduced the number of drives down, hit start, acked i'd be rebuilding parity and hit format for the 14TB. All well so far.
-
I have a fairly large array, it has a total of 180 TB, 2 parity disks and 20 array disks. I have one spare slot in the hot swap bays. My 4TB disks are approaching 6 years old so want to switch them, I've shucked a series of 18TB drives, and two have finished a pre-clear. My parity is 14TB. I use 114TB, with 66.4TB free. New Disks: 5x 18TB Parity: 2x 14TB Disks to remove: 6x 4TB I would like to: Replace parity with 2x 18TB. Replace 6x 4TB with 2x 14TB old parity drives. Leave 3 hot swap 18tb to add to the array at later dates (I'm not going to have access to the hardware for a while and have enough space) What's the fastest way to achieve this? I'm thinking of: 1. Use Unbalance to evacuate the 6x4TB with the array up. 2. Pre-clear 2x18tb. 3. Use "New Config" to then remove all the 4tb, replace the parity, and rebuild without trusting parity. I understand this will effectively just make a filesystem from all the drives I choose and kick off a parity build as if it were new? 4. Wait for this to finish, stop the array, then add the two old parity drives to expand the array. 5. Re-run parity. Can i eliminate 4+5? I see the unassigned drives plugin can format disks. This would risk me going without parity, I have however recently completed parity checks without issue and my last disk failure was one of these ageing 4TB, the rest are much more modern.
-
Yeah its odd its just the one that has an issue. Both handbrake and mkvtoolsnix were running. I will try install this version again and nuke the appdata folder. Everything was default except the ports.
-
Wonderful! Works great!
-
Hi, I get extraction errors with rar files with jdownloader, is rar5 bundled with this container? https://board.jdownloader.org/showthread.php?t=77435
-
This container seems to hang forever on 00-app-script.sh for me: [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 00-app-niceness.sh: executing... [cont-init.d] 00-app-niceness.sh: exited 0. [cont-init.d] 00-app-script.sh: executing... I send the stop request: [s6-init] making user provided files available at /var/run/s6/etc...exited 0. [s6-init] ensuring user provided files have correct perms...exited 0. [fix-attrs.d] applying ownership & permissions fixes... [fix-attrs.d] done. [cont-init.d] executing container initialization scripts... [cont-init.d] 00-app-niceness.sh: executing... [cont-init.d] 00-app-niceness.sh: exited 0. [cont-init.d] 00-app-script.sh: executing... [services.d] stopping services [services.d] stopping s6-fdholderd... [cont-finish.d] executing container finish scripts... [cont-finish.d] done. [s6-finish] syncing disks. Hangs shutting down too. Had to kill -9. Clean removed and tried again and got the same. Switched to another container and it loads fine. Not sure what the problem is, I'm using your Handbrake and MKVToolsNix and they are both working wonderfully.
-
Is there a bug with custom locations and force_SSL not working? I'm using this to force the redirect: if ($scheme = 'http') { rewrite ^ https://$http_host$request_uri? permanent; }
-
Problem is probably shinobi doesn't have web paths set. I host my shinobi on a seperate NAS, so should be the same: This will make sure the websocket upgrade works, to get rid of your gateway issue that's a problem with shinobi itself. In super: http://192.168.1.200:9080/super Under config: "webPaths": { "home": "/shinobi", "super": "/super", "admin": "/admin" } Add it to the end and make sure the previous line has a ",". Save, then control and logs, and hit restart core.
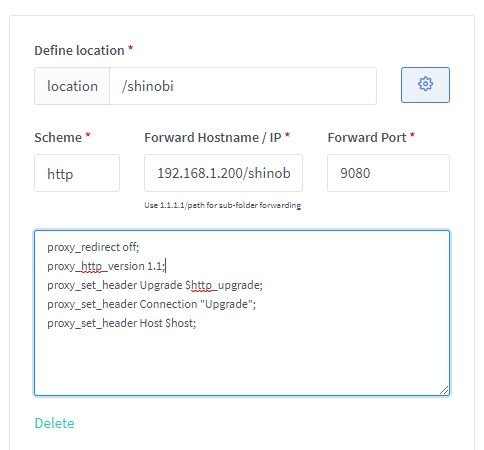
-
Hi I posted here, but I'm starting to think this might be a feature request for either this plugin or unraid itself? I have two 'hot standby' drives which I just want to be available but never spun-up, checked until i do an actual action on them so as assign, mount, etc.. They seem to always end up spinning for no reason though and never spin-down when idle times are met. Is there a way to stop these unassigned drives from being managed by Unraid (or have it manage them better by it)? Sorry if i'm missing something
-
Since subversion seems to be non-functioning in this pack, you need to install the following as well: mkdir -p /boot/config/plugins/NerdPack/packages/extra cd /boot/config/plugins/NerdPack/packages/extra wget http://slackware.cs.utah.edu/pub/slackware/slackware64-14.2/slackware64/l/apr-1.5.2-x86_64-1.txz wget http://slackware.cs.utah.edu/pub/slackware/slackware64-14.2/slackware64/l/apr-util-1.5.4-x86_64-2.txz wget http://slackware.cs.utah.edu/pub/slackware/slackware64-current/slackware64/n/openssl10-1.0.2u-x86_64-1.txz wget http://slackware.cs.utah.edu/pub/slackware/slackware64-14.2/slackware64/l/serf-1.3.8-x86_64-1.txz wget http://slackware.cs.utah.edu/pub/slackware/slackware64-14.2/slackware64/l/icu4c-56.1-x86_64-2.txz wget https://www.ifconfig.com.ua/slackware/slackware64-current/slackware64/ap/mariadb-10.4.12-x86_64-2.txz wget http://slackware.cs.utah.edu/pub/slackware/slackware64-current/slackware64/l/utf8proc-2.4.0-x86_64-1.txz installpkg apr-1.5.2-x86_64-1.txz apr-util-1.5.4-x86_64-2.txz openssl10-1.0.2u-x86_64-1.txz serf-1.3.8-x86_64-1.txz icu4c-56.1-x86_64-2.txz mariadb-10.4.12-x86_64-2.txz utf8proc-2.4.0-x86_64-1.txz Not sure if its documented in this thread, but that should save the googling for each dependency. I think the issue is that the configure flags are for the server side subversion, meaning it needs apr, mariadb, etc. Not sure if it can be switched to a statically linked or client only subversion package? Probably should move my files to git at some point anyway
-
Hey, is it just me or does this container erase your .conf file everytime you reboot? I enable the fTP and then it erases my config next restart. Set keys for CRON and PLUGINS from environment variables ... cpuUsageMarker: CPU Changes Complete. Here is what it is now. { "port": 8080, "addStorage": [ { "name": "second", "path": "__DIR__/videos2" } ], "host": "127.0.0.1", "user": "majesticflame", "password": "", "database": "ccio", "port": 3306 }, "mail": { "service": "gmail", "auth": { "user": "[email protected]", "pass": "your_password_or_app_specific_password" } }, "cron": { "key": "fd6c7849-904d-47ea-922b-5143358ba0de" }, "pluginKeys": { "Motion": "b7502fd9-506c-4dda-9b56-8e699a6bc41c", "OpenCV": "f078bcfe-c39a-4eb5-bd52-9382ca828e8a", "OpenALPR": "dbff574e-9d4a-44c1-b578-3dc0f1944a3c" }, "productType": "Pro", "cpuUsageMarker": "CPU" } Seems to be the offending section. For example, delete the second video location and it comes back next time the container restarts.
-
Great plugin, really is very cool. I installed it to see if I could have a performance indicator to decide which drive to pull and replace with a 12TB Iron Wolf. Unfortunately I couldn't determine which drive to pull from the 4TBs since they all look pretty consistent. Which leads me to a feature request: would it be possible to put a roll up of the smart data for the drives on the view? I think if on the main view it could show things like drive age, errors, and indicators, combined with the performance it could be a "replace this drive" decision making plugin. Still not sure which drive to replace with the new iron wolf, although the internet always says replace seagate 😁😂 I have loads of problems with spinning up the drives, it rarely works on the Areca SAS controller for example.
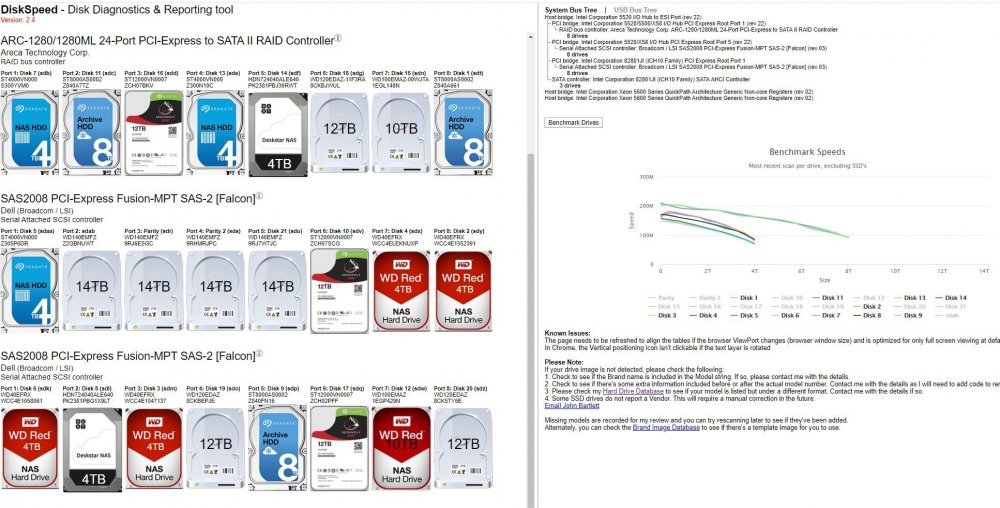
-
nth parity seems like something that should be up to the user, so i'd vote for an nth parity option. Is it more complicated programatically to add n vs 3? Seems to be the best if it was uncapped and people can have between 0 and n if they wish. ATM I'm happy with 2 but I can see why its a bit nerve racking if you have multiple SAS enclosures.














