
CS01-HS
-
Posts
475 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Report Comments posted by CS01-HS
-
-
2 hours ago, CS01-HS said:
I'm having the same problem - no spindown with telegraf running or any other app that calls smartctl. hdparm seems to be okay.
Alright, it seems that if drives are spun down by unraid, either manually with the web interface or automatically, calling smartctl wakes them up.
If they're spun down with hdparm -y, calling smartctl does NOT wake them up.
Is that intended behavior?
-
15 hours ago, sivart said:
@limetech I apologize. I think it was the telegraf docker image. Even though it was reporting not running, I think it was continuously trying to restart an issuing SMART commands. Disabling telgraf allowed the drives to spin down.
I'm having the same problem - no spindown with telegraf running or any other app that calls smartctl. hdparm seems to be okay.
-
This appears to be fixed in 6.9.0-rc1 but I base that only on one successful reboot. I'll keep monitoring and close the report if it doesn't reoccur.
-
 1
1
-
-
Any update on this? It's still a problem in 6.9.0-rc1
-
4 minutes ago, JorgeB said:
I would say that only confirms it's a problem with that specific computer/OS.
It happens on multiple computers, from Mojave to Catalina to Big Sur. It worked on all of them with 6.8.3. It broke sometime after I installed the first beta (beta25.)
I'm pretty certain that's the culprit - the question is whether it's a bug in the release or something went wrong during the install process, maybe particular to my setup.
To answer that it'd be helpful to know whether it's working with the beta for anyone on MacOS.
-
40 minutes ago, JorgeB said:
This looks more like a macOS problem.
Reasonable assumption but with same MacOSs searches on my Raspberry Pi share (with the standard packages) work properly.
*Website is the Raspberry Pi share.
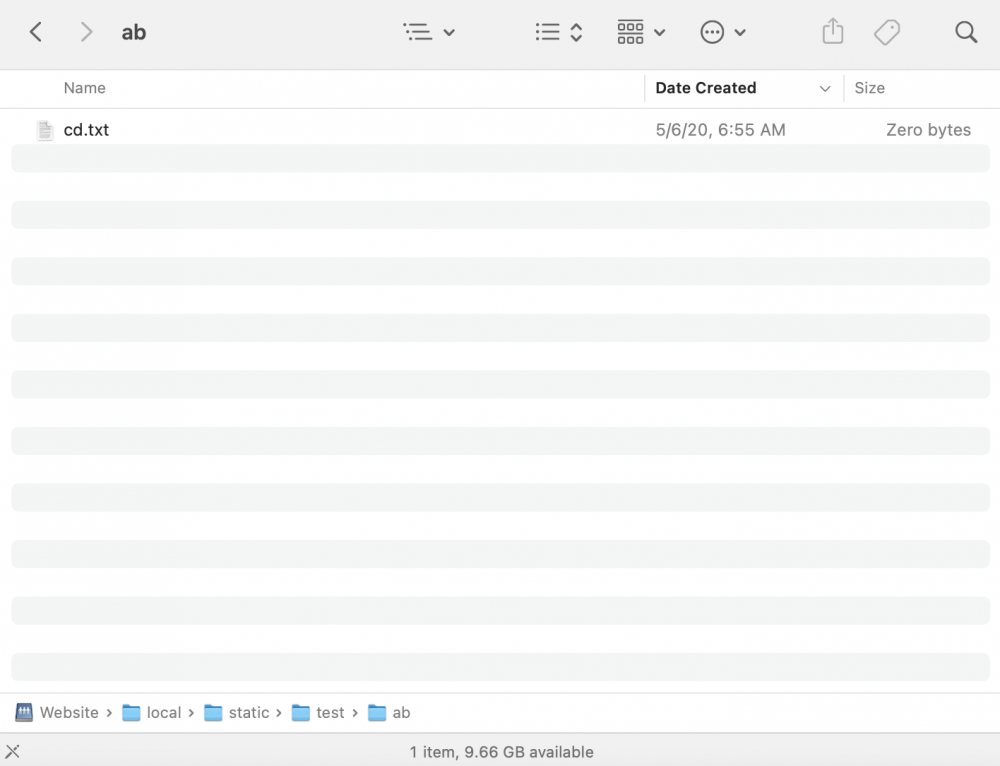
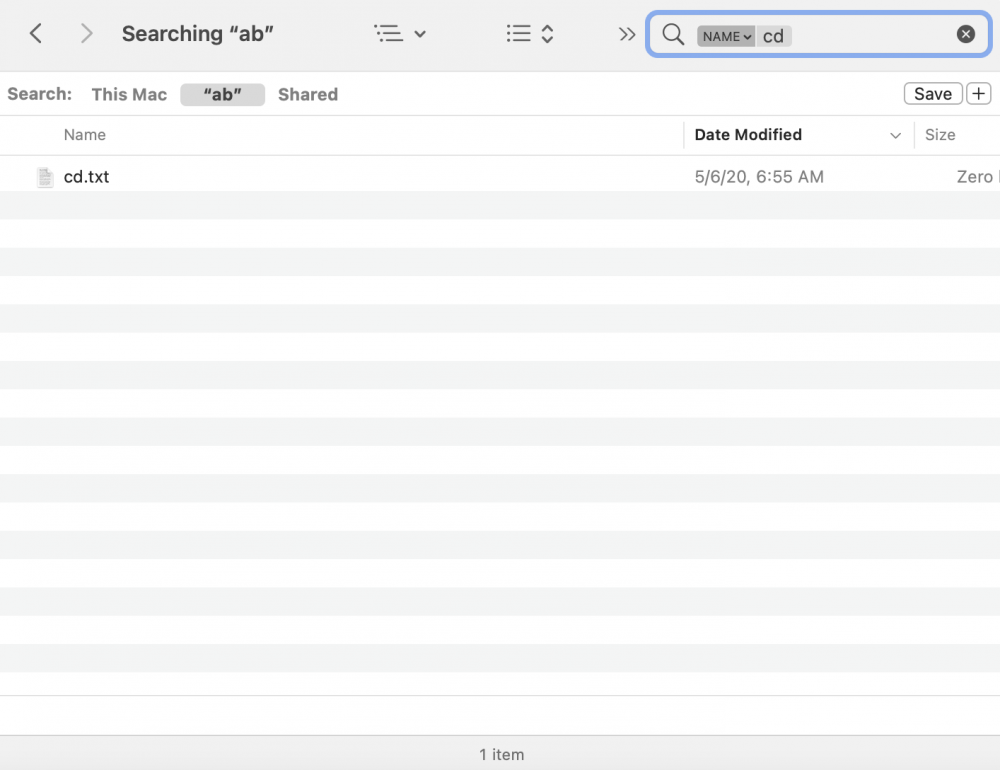
-
In case it's not clear from my description here it is in pictures:
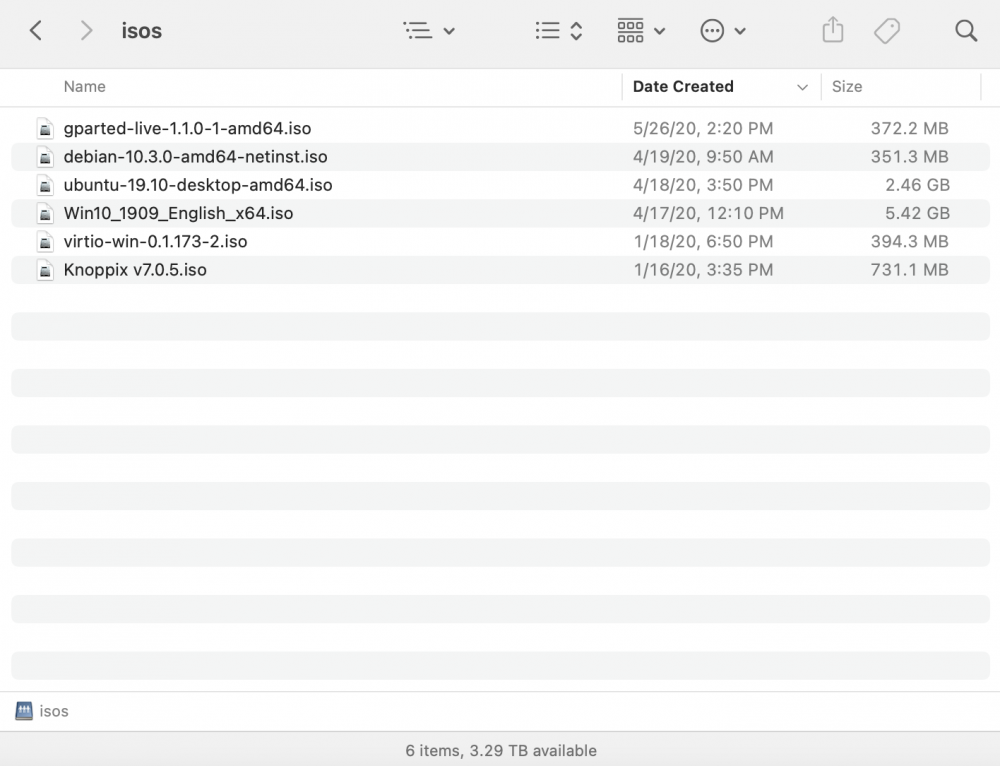
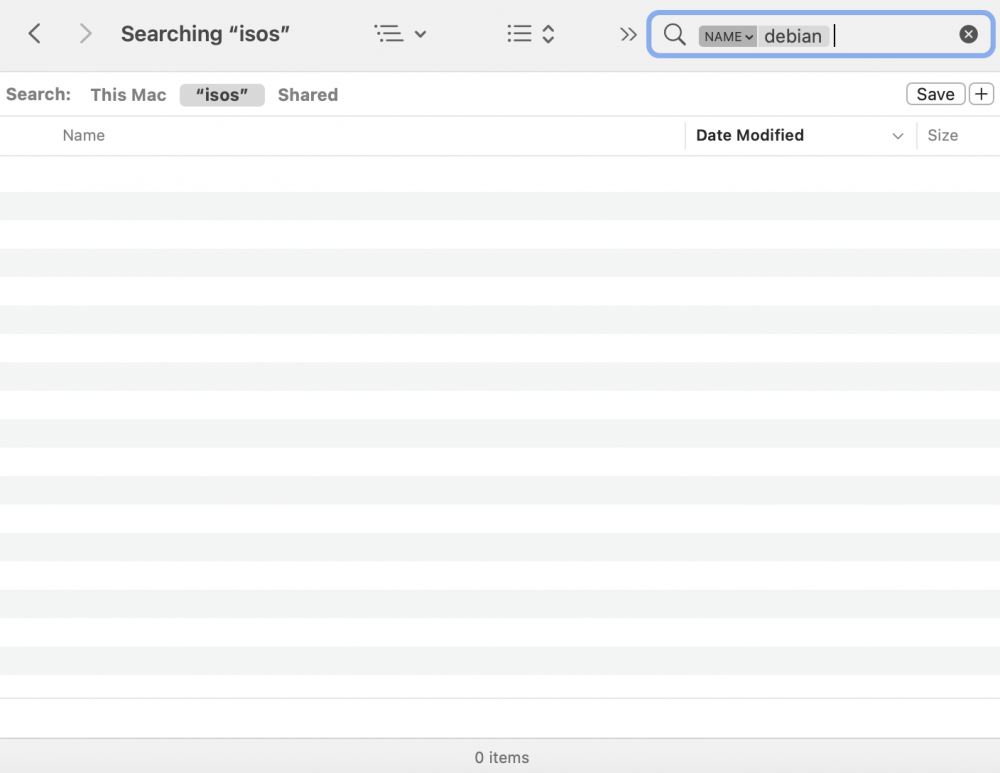
A search of "debian" in my isos share (which clearly contains it) returns no results.
Searching the full name debian-10.3.0-amd64-netinst.iso also returns no results.
This problem persisted through the upgrade from beta30 to beta35, and from Catalina to Big Sur.
-
On 11/16/2020 at 5:13 AM, sir_storealot said:
Hi, I want to use i915 IGPU acceleration in docker. Does it mean I should disable the stuff I have added to my go file before I upgrade to new beta:
modprobe i915 sleep 5 chmod -R 777 /dev/dri chown -R nobody:users /dev/driI'm also curious.
This line in the release notes, best I can tell, does not suggest i915 wasn't included in previous releases, only that it's among those now included - otherwise the modprobe command wouldn't have worked in previous releases, right?
QuoteUnraid OS now includes selected in-tree GPU drivers: ast (Aspeed), i915 (Intel), amdgpu and radeon (AMD).
If so there's a new way to load it but the earlier way also works. I confirmed by upgrading, rebooting (without changing the go file) and testing the Emby docker.
-
2 minutes ago, John_M said:
Are you referring to Spotlight searches for content that's stored on SMB shares, or to something else?
No. Just a simple search in the Finder window of a share.
-
Still a problem in beta-35.
Am I the only who searches SMB shares or are others not experiencing this?
-
2 hours ago, trurl said:
Syslog resets on reboot, and that is where we would look for evidence. Unless you also have Syslog Server setup to preserve syslogs
I do. Diagnostics and saved syslog attached.
Parity check
starts: 06-11-2020 07:35
finishes: 06-11-2020 21:01
You'll notice a lot of BTRFS messages. What caused the dirty shutdown was a system freeze while running rebalance.
-
I thought the error might have been legitimate until I rebooted and it went away.
Are the post-reboot diagnostics useful? If they are let me know and I'll upload them.
EDIT: Looks like I changed the bug status. Sorry about that, not sure what I changed it from.
-
Changed Status to Open
-
SSH keys suddenly stopped working.
The cause was root ./ and root parent(?) ../ were owned by nobody:users with group/other write permissions. I didn't notice any other directories affected. Not sure if the beta caused it but it's never happened before.
A reboot fixed it, back to normal:
root@NAS:~# ls -la / total 8 drwxr-xr-x 20 root root 440 Oct 1 23:02 ./ drwxr-xr-x 20 root root 440 Oct 1 23:02 ../EDIT: Just to add, the new multi-pool support which, with restrictions, can approximate multi-array is an amazing feature. I'm rebuilding parity while running time machine backups (to a dedicated RAID5 pool) with no adverse effects. It's also interesting to consider whether some setups might create exceptions to the fewer-bigger-drives-are-safer rule.
-
1
-
-
Not critical but VNC Remote for VMs fails to load with the following error in Safari 14 (latest version) for MacOS. Works properly in Brave.
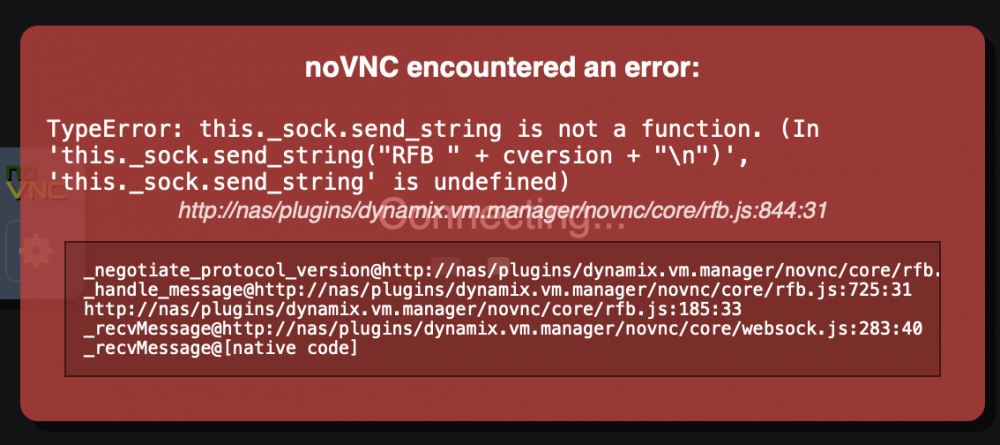
-
28 minutes ago, limetech said:
Here's another way to handle 2-device btrfs pool:
No need to change the shares' caching setting or run mover? Wow, that's easier than I expected, thanks.
-
1 hour ago, limetech said:
You only need to use btrfs destination if you want to preserve 'NoCOW' share attribute, ie, on a share Settings page, if "Enable Copy-on-write" is set to "No". This is the default setting for the predefined 'domains' share used to store vdisk images.
II have a RAID 1 btrfs cache (with equally sized disks.) I figure I can convert it to a single-drive pool then use the newly-freed drive as my "btrfs destination." But is there a way do that without adding it to Array Devices (which will introduce new problems), maybe through unassigned devices?
Otherwise I'm not sure how most plan to do this.
NoCOW seems important so I don't want to lose it.
-
I discovered that if you leave the login popup open (without logging in) then repeat the action that opened it the previously-opened popup will update to show the expected data.
This works in all cases except Web VNC which opens a new window every time.
-
I watched your video again and noticed you can access docker logs but not docker consoles. I can access docker consoles but docker logs give a login prompt. Strange!
Can anyone point me in a direction to debug the php? I wonder if I can track the problem down.
I do see this ambiguous error in my log file when nginx is restarted
root: Error: Nothing to do -
11 minutes ago, bastl said:
This is a joke, isn't it? Are you really did this? You better don't!
No but only to test which is why I'd like a permanent solution.
Is there a fix?
(I use Safari on MacOS like the original poster)
-
I had this problem and the only way I found to fix it was setting a blank password for root in the users tab. If there's a better way I'd like to know.
-
Here's my test with 1 hour of iotop -ao
- Standard 6.8.3 with no customization
-
2x 500GB WD Blue SSD
-
BTRFS RAID-1 default
-
Cache, docker.img and libvirt.img with a dozen dockers and 2 VMs, mostly idle
I'd like to know what's responsible for the shfs /mnt/user -disks 7 entries
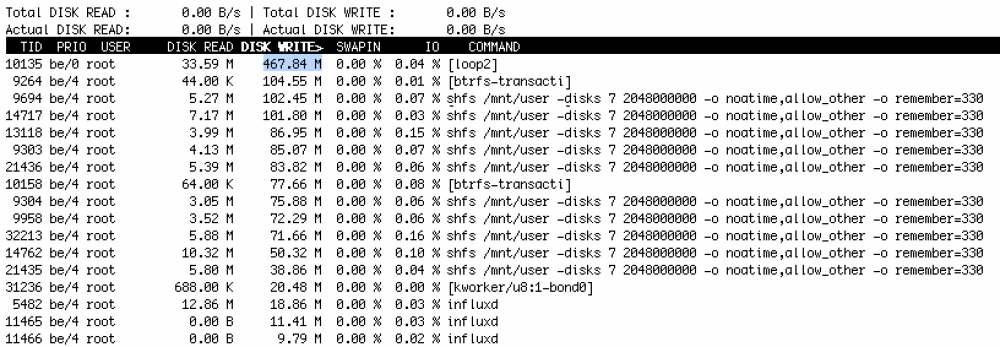
-
10 hours ago, mbuboltz said:
Will there be any way to upgrade when the time comes and make sure to keep AFP? AFP is still used and works so much better than SMB
I switched from AFP to SMB in preparation for 6.9.
In my environment (High Sierra, Mojave and Calatina) with regular shares and Time Machine, SMB is reliable but with consistently worse performance, and yes I've made the recommended client tweaks.
It's Apple's fault for dropping AFP without improving SMB, can't blame Unraid.
-
 1
1
-
-
13 hours ago, tech960 said:
Are unassigned devices (USB Drive) able to be spun down yet? Mine is always on and consistently over heats (it's a raid -0 unit). As it's hardly used, it would be nice if it went to sleep at some point.
I use a User Script to spin mine down. It works although I see occasional unexplained wake-ups which I haven't tracked down.








Unraid OS version 6.9.0-rc1 available
-
-
-
-
-
in Prereleases
Posted
Great.
Also, in case it's new/useful info, when drives are spun down with hdparm -y the web interface shows them active despite smartctl and hdparm reporting standby.