



CS01-HS
Members
-
Joined
-
Last visited
-
Ah, that explains it. Thanks. Took some time but I got it working with qemu-8.2.
-
I have a Mojave VM that I run with pc-q35-5.1 With 7.3 it seems whenever I stop/start the array the machine setting in the XML (below) resets to pc-q35-8.0 Strange that UNRAID would make changes to VM XML surreptitiously. Is there any way to stop it? <os> <type arch='x86_64' machine='pc-q35-5.1'>hvm</type> <loader readonly='yes' type='pflash' format='raw'>/mnt/user/system/custom_ovmf/Macinabox_CODE-pure-efi.fd</loader> <nvram format='raw'>/etc/libvirt/qemu/nvram/318231bd-841c-44xa-a9f5-389c374b34cd_VARS-pure-efi.fd</nvram> </os>
-
My simple "fix" was a daily wakeup alarm in the BIOS. A day of downtime at worst. Alternatively a second UPS.
-
I was surprised to discover, after upgraded to 7.3 and internal boot, "flash backup" still works. No reconfiguration necessary. Thank you!
-
Is file manager the best way to copy or move? I worry using mover might conflict with the complex mover-tuning rules I set up.
-
Re: internal boot, if your existing pool is a BTRFS mirror and you want to preserve what's on it: Couldn't you remove one drive from the pool, provision it for internal boot, add it back to the pool (which would copy existing data to the BTRFS partition) then repeat the process with the other drive?
-
Yes but the VM is Mojave (with Q35-4.2) and the "new" device is an iPhone 5S. I don't want to take your time with what's likely an edge case.
-
USB 2.0 device but connected to a USB3 port. I switched to a USB2 port - no luck, same error. Thanks though. I went through hell trying to get the original device to sync before I discovered your plugin so maybe something I did in that process is the difference.
-
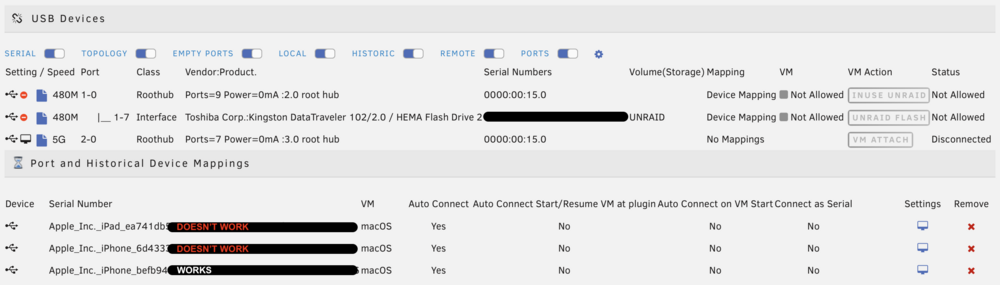
For a couple of years I've used this plugin to sync my iPhone to a macOS VM. Works great! But with two new iOS devices when I try to attach them I get a "bind" failure in the unraid log, the VM crashes, and the device restarts (which I believe is a security measure.) Same VM, same port, same cable for all 3. The original device (iPhone) still attaches and syncs perfectly. Any ideas? Log excerpt with phone that works: works Log excerpt with phone that doesn't: breaks
-
Right, "if 1 parity, and 1 disk lost, emulate the 1 lost disk." Makes sense. What I question is what I just experienced: "If 1 parity, and ALL disks lost, require 1 disk to be rebuilt." Why did that 1 data disk, and not the others, require a rebuild? Is there some advantage I'm missing or am I not explaining it clearly?
-
So, if I understand (and thank you for bearing with me): If all data disks go offline, writes to all will fail but because I have 1 parity I have to rebuild 1 disk (the first with a failed write.) If I had 2 parity's I'd have to rebuild 2 disks (the first 2 with failed writes.) I must be missing something because I don't see the benefit. Why not just handle the 1st failed write like all the rest and avoid the rebuild?
-
All 4 of my data disks dropped offline (red X) because the SATA card disconnected. Only the parity disk (and cache) connected to onboard ports remained. When I rebooted, after an XFS repair, disk1 was emulated (orange circle). The other 3 data disks mounted normally (green circle.) Is that because I was writing to disk 1 when SATA card glitched or for some other reason? I'm trying to understand how it works to distribute disks among my 4 onboard controllers and 4 from the card to mitigate risk.
-
So if I'd been writing to two disks it would have disabled the whole array or only 1 disk - or is this writing unrelating to the disabling?
-
I believe a software glitch (my fault) caused my SATA card to drop offline taking all 4 of my data disks with it. When it failed I was writing to Disk 1. A reboot fixed the card but when the server came back up Disk 1 was emulated. I ran XFS repair which worked and now I'm rebuilding the disk. But what if I had been writing to more than 1 data disk when the card failed? With 1 parity I can only emulate 1 disk so would however many disks I was writing (assuming the "writing to" caused the corruption/emulation) become un-rebuildable? If so, then is best practice to distribute disks among controllers to minimize the consequences of a single-point failure? Here's my syslog from the incident, in case it's interesting: syslog
-
A year or two ago I had strange "disappearing container" issues running Rebuild-DNDC so I uninstalled it. Maybe start there.


