




acosmichippo
Members
-
Joined
-
Last visited
-
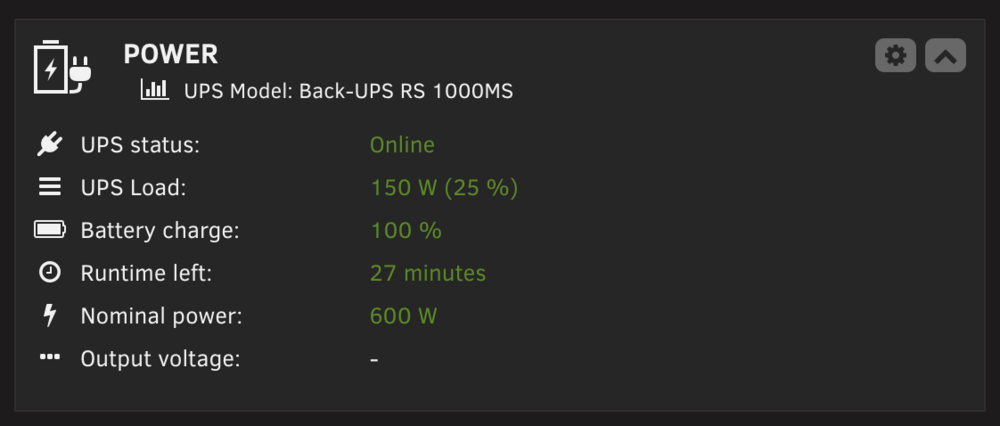
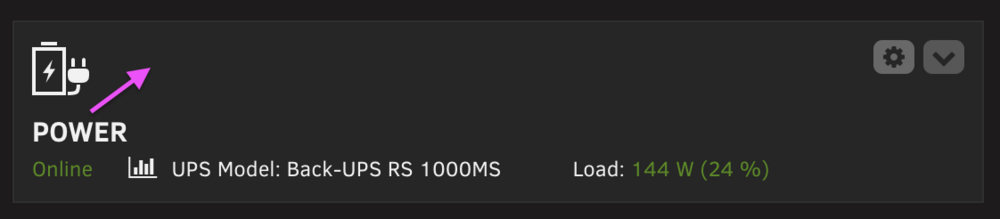
Sorry if this isn't considered a "bug" but on all other widgets (when full sized or minimized), the title is directly to the right of the icon (first attachment). This is what I expect. But when the power widget is minimized the "Power" title is moved underneath the icon and wastes vertical space on the dashboard (second attachment). Can you move it up like all the other widgets? Thank you for reading!
-
Hi all. I've tried searching this thread for the question i have but it's a bit hard to search for. Anyway, I have GluetunVPN basically working and most of my containers routed through it. The problem i have is two of my containers use port 8080, and I guess even if I use a new host port for one of them (like 8081), they still clash on container port 8080 in the Guetun container. Is there any way around this? Thanks!
-
I have not tried safe mode yet but that is next on my list.
-
Hello All, Over the last couple days I've had this happen twice. I also recently updated to 7.1.4, perhaps that is related, perhaps not. I also feel like the web gui has been generally really slow as of late, but maybe I'm imagining that. Anyway, this first happened two days ago which i didn't try to troubleshoot much, just SSHed in, rebooted, web gui was back up, no big deal. Then late last night I noticed the GUI was down again. Did some basic searching and generated a diag file. I was unable to bring the GUI back up by restarting various services, but again after a full reboot this morning it is working. I also looked through a few other "500" posts here and on reddit but none of those root causes seem to apply to my situation. After a perusal through the diag files I see this in the PHP logs: [01-Sep-2025 01:57:55 America/New_York] PHP Fatal error: Uncaught TypeError: extract(): Argument #1 ($array) must be of type array, false given in /usr/local/emhttp/plugins/dynamix/template.php:50 Stack trace: #0 /usr/local/emhttp/plugins/dynamix/template.php(50): extract(false) #1 {main} thrown in /usr/local/emhttp/plugins/dynamix/template.php on line 50 [01-Sep-2025 01:58:02 America/New_York] PHP Fatal error: Uncaught TypeError: extract(): Argument #1 ($array) must be of type array, false given in /usr/local/emhttp/plugins/dynamix/template.php:50 Stack trace: #0 /usr/local/emhttp/plugins/dynamix/template.php(50): extract(false) #1 {main} thrown in /usr/local/emhttp/plugins/dynamix/template.php on line 50 I have not yet tried booting into safe mode, but that is next on my list if it keeps happening and nothing else can be found here. Thank you for any help! edit: forgot to mention I checked /usr/local/emhttp/plugins/dynamix/template.php and the file seems to be at least intact. Line 50 is: extract(parse_ini_file('state/network.ini',true)); maybe the network.ini file is getting borked somehow? unraid-diagnostics-20250901-0200.zip template.php edit 2, a couple weeks later: so far this has not reoccurred. the only thing i did was uninstall a couple plugins i don't really use anymore like Disk Locations, and one other io can't recall. Not sure if that was a fix or just coincidence.
-
just wanted to randomly drop in and say thanks for keeping this plugin going. the development over the last year or whatever has been excellent.
-
somehow i have messed up DNS for this after setting up local DNS in my pihole and nginx. all my other container apps went fine (just added local DNS entry on pihole and proxy hosts in nginx), then i repeated the same thing for this one and after restarting the image initially the wg0 interface would not come up at all. I tried un-doing all of the DNS changes I made for this container - deleted entries on pihole and nginx, and deleted/reinstalled the image via template. Also have gotten a completely fresh wg0.conf from VPN provider (mullvad). Now the interface comes up and web gui is accessible, but it is not able to resolve www.google.com and there is no external traffic obviously. If I disable the VPN everything works just fine. Do I need to just undo ALL of the local DNS stuff I did in pihole and nginx? Any help would be greatly appreciated! edit: whelp... after all that i finally realized my mullvad subscription just happened to run out exactly at the wrong time. so apparently it's NOT always DNS lol.
-
thanks for picking up this project, mover tuning like this should really be baked into unraid imo. anyway, random thought. Would it be beneficial to have an emergency auto-move trigger? You could set a cache threshold at, say, 95% that automatically triggers mover despite the set schedule.
-
did flaresolverr die overnight for anyone else? Not sure if it's a cloudflare update or more indexers are using it or what. for example: 2025-03-11 14:46:52.6|Warn|HttpClient|HTTP Error - Res: HTTP/1.1 [POST] http://10.0.0.186:8191/v1: 500.InternalServerError (182 bytes) {"status": "error", "message": "Error: Error solving the challenge. Timeout after 60.0 seconds.", "startTimestamp": 1741718751891, "endTimestamp": 1741718812651, "version": "3.3.21"}
-
may i suggest updating the top comment to clarify this from the beginning? I believe a lot of people like myself and others already will be coming here with this question, and they shouldn't have to read two pages of comments for this answer.
-
Hi all, i've tried searching but haven't found an answer to my question yet. apologies if i missed it. Is it possible for unmanic to skip files already in HEVC? I see there's a plugin to skip files based on metadata, but I'm not sure if/how that would work. Thank you for any tips!
-
Hello all, Last night a disk was disabled for read and write errors. Perhaps coincidentally (or not) i had a parity check running leading up to the failure, but the check did complete while correcting 1 error (Sep 13 23:36:40). A few hours later (Sep 14 02:17:26) disk15 started throwing read/write errors and was disabled. I looked through the SMART report for it and didn't see anything obviously wrong, but I'm not extremely familiar with reading SMART reports. It is an old-ish disk. But this is also a relatively new case to me (used Supermicro CSE-847BE1C-R1K28LPB) so i'm wondering if something could be wrong with that instead. It has hot-swap bays and very little actual cabling. If the disk seems fine otherwise i will double check all the connections and re-seat the disk in its slot. Thank you for any input! unraid-diagnostics-20230914-1125.zip update 9/28: I did update the LSI firmware on 9/14, but the issue just happened again. Luckily I have a spare disk of the same capacity, so I'm just going to swap that in and see if it's more stable. update 4 months later: everything has been good since i put in a spare disk, so it seems like it was just a bad disk.
-
I had a similar issue and it took some time with reboots and shuffling the flash drive around, but finally it booted. Is your BIOS set to UEFI boot? Mine is, I think I need to change it to legacy.
-
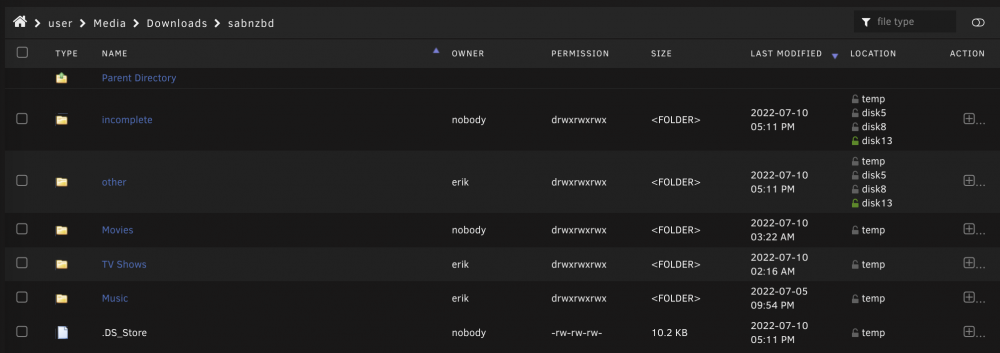
Hello all, This weekend i decided to try moving my downloads directory from the default dedicated Downloads share to a directory within the Media share (with Cache set to "Yes"). I wanted to make use of hardlinks when moving media around rather than full copies, but I was also hoping to keep downloads on the cache instead of waking up the disks. Unfortunately, it seems for some reason Unraid is not properly utilizing the cache - for example, when I start downloads in sabnzbd, it immediately crates directories on the array disks (see screenshot). I have tried deleting the stray directories on the disks a few times, making sure only "cache" is shown for the location of my downloads folder, but every time i retry a download new directories on the disks are made. Cache space is not a problem, the cache is 2TB and only 51% full. Also mover is not involved, it is not scheduled to run until 1am, and like i said these directories on the disks are created immediately when downloads are started. sabnzbd has no say in where in the array/cache the directories are created, right? I thought it was all up to Unraid and its filsystem to properly direct new data to the cache instead of the disks. The only volume mapping (besides config) i have in sabnzbd is: /data/Downloads/ <---> /mnt/user/Media/Downloads/ I guess I could try changing it to this instead to force using only the cache: /data/Downloads/ <---> /mnt/cache/Media/Downloads/ but I didn't think it would work with the hardlinks. Anyway, thanks for any help!
-
thanks, I think I turned it on at some point for mover tuning.
-
doesn't seem to have helped. also tried multiple browsers on two computers in private mode as well.




