





bunkermagnus
Members
-
Joined
-
Last visited
-
Did that but no difference. Only thing that worked was to roll back from flash backup before update.
-
After using the UnRAID USB creator to restore my 6.12.6 flash backup I am up and running again and can draw a sigh of relief. This was the worst update experience for me so far, don't really understand what went wrong but I guess I'm staying at 6.12.6 for now.
-
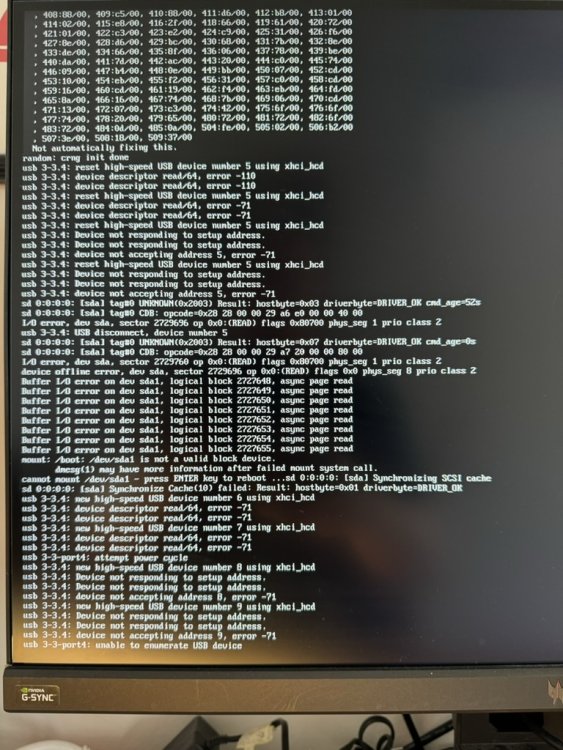
Actually now my system won't boot at all, just getting errors like these, I updated to the latest BIOS of my motherboard, fiddle with settings to get it to work, no luck, reverted to an older bios, just won't work: Gonna try to restore from flash backup before the update to 6.12.8
-
I have a weird problem that has plagued my last 1-2 years. I've been using UnRAID since 2019 and never had any problems with the automatic update process until the last 4-5 (stable) releases. I've only followed the stable release and only followed the recommended update path. This is what haoppens: I make sure my plugins and dockers are updated I backup my flash drive using the standard UnRAID WebGUI, following the recommended guide I shut down all my dockers I click the "update OS" under Tools. So after the update is done and it says "Reboot to upgrade" I click on that. The update fails since it doesn't recognize the flash drive. I take out the flash drive, put it in my mac and run the Make bootable Mac script on the flash drive. Put the flash back on the server and reboot without a problem. I though my flash drive was getting worn out so I got a brand new flash drive, a Samsung FIT 64 Gb. and transferred my license after updating last time to 6.12.6. Everything has been running just fine since last update. So this morning I did the update to 6.12.8 and the exakt same thing happened again, requiring me to run the "make bootable" script on the flash for it to work. Any ideas as to what is going on?
-
I have version 11.2.0.520
-
There seems to be a new version out, will the docker container be updated soon, thanks for your work?

-
Thank you, I have edited the Syslinux configuration and will reboot now. Also, a powercycle brought the ZFS pool back online like nothing ever happened, all I hade to do was a "clear". I have also updated to the latest Motherboard BIOS F38f and I have also removed all USB devices connected to the "blue" USB slots directly connected to the CPU as some explained that their NVMe problems disappeared when doing that. I will give it a try, too bad it's a sneaky problem that can occur after 1 hour or 2 months. Thank you anyway!
-
It would seem this is most likely a Gigabyte x570 hardware issue, so many have reported NVMe issues with M.2 slot one which is PCI 4.0. That the motherboard just suddenly removes the drive from that slot. Reddit thread on Gigabyte boards dropping NVMe SSD
-
unraid-diagnostics-20230926-1926.zip Thank you for your reply, enclosing diagnostics file.
-
I'm a bit lost here where I try to determine whether the ZFS mirror implementation is a bit shaky still or if I'm suffering from a hardware error and how to proceed. This has happened A couple of weeks ago I bought two Samsung 2 Tb Evo 970 plus devices to replace my pretty worn 512 Gb SSD of the same brand and model. My reaoning was that I wanted a mirrored cache to put some shares with semi-important data not to disturb the spin-down array disks unnecessarily. Everything went smooth and worked as planned for a couple of weeks. Today I noticed that my mirrored ZFS pool with these devices was degraded and that one of the SSD:s had been removed from the pool as shown below: I hadn't noticed anything and Unraid had not alerted me to this error, neither through e-mail or pushover. I consulted my SNMP log: So the "spin-down" of my one of the SSDs in my new mirrored cache pool happened a couple of days back. So now to my questions: I chose to make a ZFS pool but I now have doubts and are making preparations to rebuild the pool as an BRTFS mirror instead, is there any downsides doing that compared to keeping ZFS? What would be the best way to rule out that the disabled disk is actually faulty, I'm thinking about maybe run a diagnostics from the servers BIOS testing the NVME and maybe a SMART test, any other suggestions? What does the log tell you that are a bit more hardware savvy than I am, to me it sound like an potential HW I/O failure? Thanks in advance and sorry for lengthy post.
-
I hope this helps: a6d9c169-56d4-477b-9989-be8cca8a8f6e
-
I can second this. ISSUE 1: Problem occurs for dockers like "binhex-Krusader", "Plex Media Server" or "Crashplan Pro" which have a docker mapped to /mnt/user and the docker data that should be backed up is in /mnt/user/appdata In the "per docker settings" I can't exclude /mnt/user because then it will skip the appdata to as its in the same folder. What I had to do is to exclude all folders except /appdata/ in my exclude list, but also exclude every other docker data folder IN the /appdata folder. In the backup log it clearly states that the setting is to NOT include external folders but it will still go for the external folders unless I put them in the exclude list. This makes it very prone to user error and micro management and I don't think it's the expected behaviour. ISSUE2: While trying trial and error with this I had to abort the script during the backup of the "Crashplan Pro" data since it started working on my whole file system in /mnt. So ofcourse the Crashplan Pro docker didn't get restarted. This made me think that when the script evaluates whether a docker should be re-started or not after the backup should be based on the docker "autostart" on/off setting in UnRAID instead of the fact that the docker was started when the backup script start or not. I have enclosed the backup and config that created the desired behaviour below, showing the tedious exclusions I had to do for some containers. Thank you for this essential and great plugin. config.json backup.log
-
I've been running Unraid in the same configuration for over 2 years, it's been rock solid. Since I updated to 6.10.x I've experience 2 system crashes where I can't login, neither through web interface or ssh. Most systems are down, SMB, some dockers (pi-hole), while a few keep running, partly (plex). The first crash happened during a monthly scheduled parity check, the second happened just last night. I've been force to hardware reset and ofcourse a new parity check will start. I'm enclosing both diagnostics file from after the reboot, just now and the logfiles I've extracted from my syslog server surrounding the crash. sauron-diagnostics-20220727-1404.zip syslogs.zip
-
Thank you, that seems to be the case as the backup is running again after the update!
-
So I've been using thius docker since May 2020 without any problems, I have about 5 Tb in different backup sets. Since the last update, 8.8.1.36 (could also be the previous update since the last 2 were pretty close to eachother) some of my backup sets can't be backed up, it throws an exception in the Crashplan service.log due to invalid file paths, probably Swedish characters causing the problem. Since the docker is not officially supported I just wanted to rule out that it's some problem with the docker before raising this ticket to Code42 as an application bug. The error in question states, this ghets repeated all day long for 2 of my backup sets which only get to 50% and 75% respectively: Caused by: java.nio.file.InvalidPathException: Malformed input or input contains unmappable characters: /storage/backup_archive/PhotosArchive/Photos Vol 1/Backed up 030126/Backed up 020919/Äldre med digitalkamera/Storsjöyran2000/DSCF0024.JPG Anyone have any experience with this problem or input in the matter?



