





bunkermagnus
Members
-
Joined
-
Last visited
Everything posted by bunkermagnus
-
Did that but no difference. Only thing that worked was to roll back from flash backup before update.
-
After using the UnRAID USB creator to restore my 6.12.6 flash backup I am up and running again and can draw a sigh of relief. This was the worst update experience for me so far, don't really understand what went wrong but I guess I'm staying at 6.12.6 for now.
-
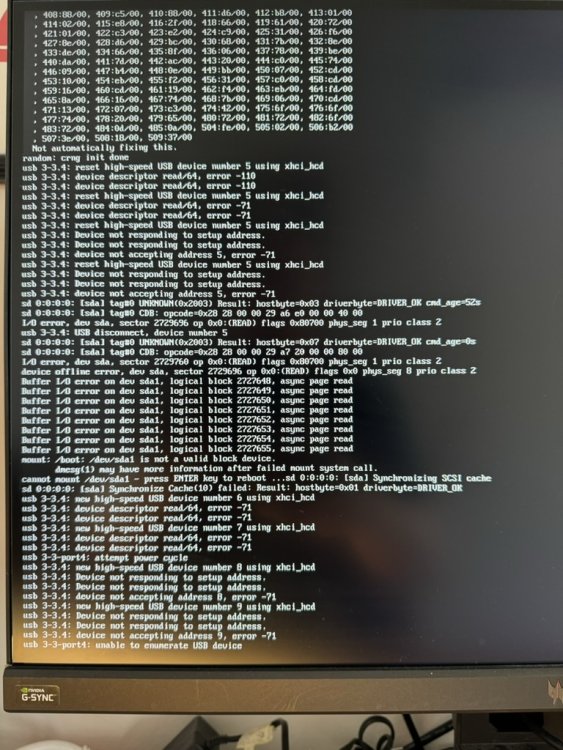
Actually now my system won't boot at all, just getting errors like these, I updated to the latest BIOS of my motherboard, fiddle with settings to get it to work, no luck, reverted to an older bios, just won't work: Gonna try to restore from flash backup before the update to 6.12.8
-
I have a weird problem that has plagued my last 1-2 years. I've been using UnRAID since 2019 and never had any problems with the automatic update process until the last 4-5 (stable) releases. I've only followed the stable release and only followed the recommended update path. This is what haoppens: I make sure my plugins and dockers are updated I backup my flash drive using the standard UnRAID WebGUI, following the recommended guide I shut down all my dockers I click the "update OS" under Tools. So after the update is done and it says "Reboot to upgrade" I click on that. The update fails since it doesn't recognize the flash drive. I take out the flash drive, put it in my mac and run the Make bootable Mac script on the flash drive. Put the flash back on the server and reboot without a problem. I though my flash drive was getting worn out so I got a brand new flash drive, a Samsung FIT 64 Gb. and transferred my license after updating last time to 6.12.6. Everything has been running just fine since last update. So this morning I did the update to 6.12.8 and the exakt same thing happened again, requiring me to run the "make bootable" script on the flash for it to work. Any ideas as to what is going on?
-
I have version 11.2.0.520
-
There seems to be a new version out, will the docker container be updated soon, thanks for your work?

-
Thank you, I have edited the Syslinux configuration and will reboot now. Also, a powercycle brought the ZFS pool back online like nothing ever happened, all I hade to do was a "clear". I have also updated to the latest Motherboard BIOS F38f and I have also removed all USB devices connected to the "blue" USB slots directly connected to the CPU as some explained that their NVMe problems disappeared when doing that. I will give it a try, too bad it's a sneaky problem that can occur after 1 hour or 2 months. Thank you anyway!
-
It would seem this is most likely a Gigabyte x570 hardware issue, so many have reported NVMe issues with M.2 slot one which is PCI 4.0. That the motherboard just suddenly removes the drive from that slot. Reddit thread on Gigabyte boards dropping NVMe SSD
-
unraid-diagnostics-20230926-1926.zip Thank you for your reply, enclosing diagnostics file.
-
I'm a bit lost here where I try to determine whether the ZFS mirror implementation is a bit shaky still or if I'm suffering from a hardware error and how to proceed. This has happened A couple of weeks ago I bought two Samsung 2 Tb Evo 970 plus devices to replace my pretty worn 512 Gb SSD of the same brand and model. My reaoning was that I wanted a mirrored cache to put some shares with semi-important data not to disturb the spin-down array disks unnecessarily. Everything went smooth and worked as planned for a couple of weeks. Today I noticed that my mirrored ZFS pool with these devices was degraded and that one of the SSD:s had been removed from the pool as shown below: I hadn't noticed anything and Unraid had not alerted me to this error, neither through e-mail or pushover. I consulted my SNMP log: So the "spin-down" of my one of the SSDs in my new mirrored cache pool happened a couple of days back. So now to my questions: I chose to make a ZFS pool but I now have doubts and are making preparations to rebuild the pool as an BRTFS mirror instead, is there any downsides doing that compared to keeping ZFS? What would be the best way to rule out that the disabled disk is actually faulty, I'm thinking about maybe run a diagnostics from the servers BIOS testing the NVME and maybe a SMART test, any other suggestions? What does the log tell you that are a bit more hardware savvy than I am, to me it sound like an potential HW I/O failure? Thanks in advance and sorry for lengthy post.
-
I hope this helps: a6d9c169-56d4-477b-9989-be8cca8a8f6e
-
I can second this. ISSUE 1: Problem occurs for dockers like "binhex-Krusader", "Plex Media Server" or "Crashplan Pro" which have a docker mapped to /mnt/user and the docker data that should be backed up is in /mnt/user/appdata In the "per docker settings" I can't exclude /mnt/user because then it will skip the appdata to as its in the same folder. What I had to do is to exclude all folders except /appdata/ in my exclude list, but also exclude every other docker data folder IN the /appdata folder. In the backup log it clearly states that the setting is to NOT include external folders but it will still go for the external folders unless I put them in the exclude list. This makes it very prone to user error and micro management and I don't think it's the expected behaviour. ISSUE2: While trying trial and error with this I had to abort the script during the backup of the "Crashplan Pro" data since it started working on my whole file system in /mnt. So ofcourse the Crashplan Pro docker didn't get restarted. This made me think that when the script evaluates whether a docker should be re-started or not after the backup should be based on the docker "autostart" on/off setting in UnRAID instead of the fact that the docker was started when the backup script start or not. I have enclosed the backup and config that created the desired behaviour below, showing the tedious exclusions I had to do for some containers. Thank you for this essential and great plugin. config.json backup.log
-
I've been running Unraid in the same configuration for over 2 years, it's been rock solid. Since I updated to 6.10.x I've experience 2 system crashes where I can't login, neither through web interface or ssh. Most systems are down, SMB, some dockers (pi-hole), while a few keep running, partly (plex). The first crash happened during a monthly scheduled parity check, the second happened just last night. I've been force to hardware reset and ofcourse a new parity check will start. I'm enclosing both diagnostics file from after the reboot, just now and the logfiles I've extracted from my syslog server surrounding the crash. sauron-diagnostics-20220727-1404.zip syslogs.zip
-
Thank you, that seems to be the case as the backup is running again after the update!
-
So I've been using thius docker since May 2020 without any problems, I have about 5 Tb in different backup sets. Since the last update, 8.8.1.36 (could also be the previous update since the last 2 were pretty close to eachother) some of my backup sets can't be backed up, it throws an exception in the Crashplan service.log due to invalid file paths, probably Swedish characters causing the problem. Since the docker is not officially supported I just wanted to rule out that it's some problem with the docker before raising this ticket to Code42 as an application bug. The error in question states, this ghets repeated all day long for 2 of my backup sets which only get to 50% and 75% respectively: Caused by: java.nio.file.InvalidPathException: Malformed input or input contains unmappable characters: /storage/backup_archive/PhotosArchive/Photos Vol 1/Backed up 030126/Backed up 020919/Äldre med digitalkamera/Storsjöyran2000/DSCF0024.JPG Anyone have any experience with this problem or input in the matter?
-
First off I'd like to say that my entry into the UnRAID universe happened last spring and I began with 6.8.3. This plattforms viability and stability has blown me away. So now with 6.9.x it's my first major update. I have been holding it off for a while since 6.8.3 has been so good but last night I decided it was time to make the jump to 6.9.1. Everything went really smooth, I ran the upgrade assistant and followed it's advice, like uninstallintg VFIO-PCI plugin etc etc. I have a question pertaining to VM's and Windows VMs in particular. I noticed that since 6.9.1 runs on a newer version of Hypervisor layer, there is a new virtIO ISO version available, so which one is the most accurate statement of the ones below: You should upgrade the drivers in your windows 10 guests to the latest (virtio-win-0.1.190-1) as soon as possible. If it works fine, don't touch it! It's not necessary but you could see some perfomance benefits by upgrading your VirtIO drivers. Thank you.
-
Yeah I figured it must be something network related closer to my end of things as I haven't seen a single post about someone with the same problem. The thing is that 5 minutes later the appfeed is there again like nothing happened. As for the DNS settings in my unraid server, they are locked down statically server side from day one.
-
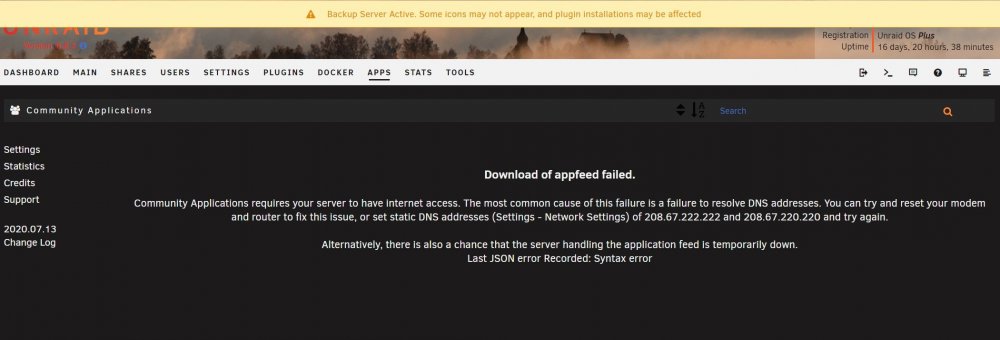
Hi, is there some maintenance or problems going on with CA related infrastructure? I've been getting this error (see image) often the last couple of days, I've been going through my network and rebooted routers, DNS settings etc but it seems to be OK. This occurs randomly a couple of times per day during the last week I would say. I'm on UnRAID 6.8.3 and CA plugin 2020.07.13 and I haven't seen this error before the last week.
-
Thank you, however there is an issue that appeared after the 06.19 version for me that is still persistent, the dashboard widget is stuck in "Retrievening stream data..." If I click on the stream icon in the widget it show the correct data but the widget simply refuses to update. Tried different browsers, Edge and Chrome with the same result.
-
First, thank you for putting this container together to tap into the potential of our unused CPU cycles. I've noticed a "quirk", the container does it's job and uploads the WU fine, but it fails to clean up the work folder after it's done and the log gets spammed with the below. If I restart the container it cleans up fine on startup, but when the next WU is done it fails to clean up again., 13:02:30:WU00:FS00:0xa7: Version: 0.0.18 13:02:30:WU00:FS00:0xa7: Author: Joseph Coffland <[email protected]> 13:02:30:WU00:FS00:0xa7: Copyright: 2019 foldingathome.org 13:02:30:WU00:FS00:0xa7: Homepage: https://foldingathome.org/ 13:02:30:WU00:FS00:0xa7: Date: Nov 5 2019 13:02:30:WU00:FS00:0xa7: Time: 06:13:26 13:02:30:WU00:FS00:0xa7: Revision: 490c9aa2957b725af319379424d5c5cb36efb656 13:02:30:WU00:FS00:0xa7: Branch: master 13:02:30:WU00:FS00:0xa7: Compiler: GNU 8.3.0 13:02:30:WU00:FS00:0xa7: Options: -std=c++11 -O3 -funroll-loops -fno-pie 13:02:30:WU00:FS00:0xa7: Platform: linux2 4.19.0-5-amd64 13:02:30:WU00:FS00:0xa7: Bits: 64 13:02:30:WU00:FS00:0xa7: Mode: Release 13:02:30:WU00:FS00:0xa7:************************************ Build ************************************* 13:02:30:WU00:FS00:0xa7: SIMD: avx_256 13:02:30:WU00:FS00:0xa7:******************************************************************************** 13:02:30:WU00:FS00:0xa7:Project: 16806 (Run 7, Clone 236, Gen 36) 13:02:30:WU00:FS00:0xa7:Unit: 0x0000002d82ed0b915eb41c47fe4bf238 13:02:30:WU00:FS00:0xa7:Reading tar file core.xml 13:02:30:WU00:FS00:0xa7:Reading tar file frame36.tpr 13:02:30:WU00:FS00:0xa7:Digital signatures verified 13:02:30:WU00:FS00:0xa7:Calling: mdrun -s frame36.tpr -o frame36.trr -cpt 15 -nt 2 13:02:30:WU00:FS00:0xa7:Steps: first=18000000 total=500000 13:02:31:WU00:FS00:0xa7:Completed 1 out of 500000 steps (0%) 13:02:35:WU01:FS00:Upload 50.94% 13:02:41:WU01:FS00:Upload complete 13:02:42:WU01:FS00:Server responded WORK_ACK (400) 13:02:42:WU01:FS00:Final credit estimate, 3275.00 points 13:02:42:WU01:FS00:Cleaning up [91m13:02:42:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 13:02:42:WU01:FS00:Cleaning up [91m13:02:42:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 13:03:42:WU01:FS00:Cleaning up [91m13:03:42:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 13:05:19:WU01:FS00:Cleaning up [91m13:05:19:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 13:07:56:WU01:FS00:Cleaning up [91m13:07:56:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 13:08:20:WU00:FS00:0xa7:Completed 5000 out of 500000 steps (1%) 13:12:11:WU01:FS00:Cleaning up [91m13:12:11:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 13:14:09:WU00:FS00:0xa7:Completed 10000 out of 500000 steps (2%) 13:19:02:WU01:FS00:Cleaning up [91m13:19:02:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 13:19:58:WU00:FS00:0xa7:Completed 15000 out of 500000 steps (3%) 13:25:47:WU00:FS00:0xa7:Completed 20000 out of 500000 steps (4%) 13:30:08:WU01:FS00:Cleaning up [91m13:30:08:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 13:31:35:WU00:FS00:0xa7:Completed 25000 out of 500000 steps (5%) 13:37:25:WU00:FS00:0xa7:Completed 30000 out of 500000 steps (6%) 13:43:13:WU00:FS00:0xa7:Completed 35000 out of 500000 steps (7%) 13:48:04:WU01:FS00:Cleaning up [91m13:48:04:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 13:49:02:WU00:FS00:0xa7:Completed 40000 out of 500000 steps (8%) 13:54:51:WU00:FS00:0xa7:Completed 45000 out of 500000 steps (9%) 14:00:40:WU00:FS00:0xa7:Completed 50000 out of 500000 steps (10%) 14:06:29:WU00:FS00:0xa7:Completed 55000 out of 500000 steps (11%) 14:12:19:WU00:FS00:0xa7:Completed 60000 out of 500000 steps (12%) 14:17:07:WU01:FS00:Cleaning up [91m14:17:07:ERROR:WU01:FS00:Exception: Failed to remove directory 'work/01': Directory not empty[0m 14:18:09:WU00:FS00:0xa7:Completed 65000 out of 500000 steps (13%) 14:23:58:WU00:FS00:0xa7:Completed 70000 out of 500000 steps (14%) 14:29:47:WU00:FS00:0xa7:Completed 75000 out of 500000 steps (15%) 14:35:35:WU00:FS00:0xa7:Completed 80000 out of 500000 steps (16%) 14:41:24:WU00:FS00:0xa7:Completed 85000 out of 500000 steps (17%) 14:47:14:WU00:FS00:0xa7:Completed 90000 out of 500000 steps (18%)
-
You're probably right, it's a fringe situation problem.
-
Well the lockup happened a couple of hours ago with the version that was new yesterday when I installed it. I notice you published a new version just recently but I haven't tried it again, as I said, it's no biggie but I suppose it could cause problems for someone who don't know about this. I just realized this on chance while searching for "Crashed webui interface" on google, someone mentioned that pausing certain Docker containers could cause this so I quickly had to learn the CLI commands for listing and unpausing dockers. Just to be clear, it happened when Plex container was paused, not stopped, I'm guessing a paused container confuses the TCP/IP stack in this case.
-
Hi there and thanks for a great plugin. Now I'm sorry if this has been covered before but I believe this plugin can hang the whole UnRAID WebUI if the Plex docker container is paused for too long, around 1 hrs or so. I just recently paused my Plex docker while using the UnBalance plugin to consolidate some media folders, after letting the plex container sit in a "paused" state for about an hour, my UnRAID Web UI was completely unreachable. Extract from syslog, this was spammed repeatedly until I ssh'ed into the server and unpaused the plex docker, then everything unlocked and started working again. I can't see any other connection between the webUI and the plex container than this plugin that I recently installed. This is not a major problem as I'll just turn off the plex container instead. Just thought I'd give you a heads up. It is also entirely possible that I am wrong about this, if so I apologize. Jun 11 19:41:44 Sauron nginx: 2020/06/11 19:41:44 [error] 11020#11020: *516793 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.1.200, server: , request: "GET /plugins/plexstreams/ajax.php HTTP/1.1", upstream: "fastcgi://unix:/var/run/php5-fpm.sock", host: "192.168.1.250", referrer: "http://192.168.1.250/Dashboard"
-
UnRAID noob as I am I am still just one week into my trial period. I have been working to transfer all my data and setup backup and media solutions with dockers. The system has been rock solid for the whole week but just now, when I am nearly done with the dockers that I need I had an unexpected kernel panic. I couldn't resist upgrading to the 6-9-0 Beta 1 but I suppose I'll downgrade to the stable version again to make sure it's not my hardware that's at fault. My rig is a brand new Ryzen 5 3600 + Aorus x570 Elite build with 16 Gb or corsair RAM with a bunch of WD Red 3Tb disks and a Samsung 970 plus 512 Gb NVMe M.2 drive as cache. I have no VMs installed, just a bunch of docker containers and what seem to be the most common plugins. I'm attaching the diagnostics below and I took a photo of my consoles "last breath". sauron-diagnostics-20200606-1230.zip





