AceRimmer
Members
-
Joined
-
Last visited
-
This is from the "main" tab, it's spilling out, but I suspect it's because I had the Unlimited Width plugin installed, I've now uninstalled but was notified I need a reboot to see the changes from uninstalling and I don't fancy having a 10 minute outage right now so this can wait. 😄
-
Your scsi card is in IT mode? Do you know is it on the latest firmware? Since you said "most" of your drives are in the netapp I would start by disconnecting that from your pc and try spin up what's in the pc first. If that works then pull some drives out of the netapp to reduce the load and see can you get less drives to spin up on Unraid without crashing.
-
Check cabling going to sas controller. Run lsscsi on terminal and ensure all drives are showing up. Check smart status of each disk if you can. My sas controller cables aren't great, a small bit of flex on the cable and my disks start throwing CRC errors. Also assuming your PSU is large enough to handle all the drives and the rest of the system?
-
The logs suggest that your Unraid server is experiencing issues related to device resets and network connectivity. Areas to investigate: 1. SAS/SCSI Devices: Several devices are showing "Power-on or device reset occurred" messages. This could indicate a problem with the SAS controller, cabling, or power delivery to your drives. Check connections and ensure all drives and enclosures are securely connected. 2. Network Interface (eth0): There's a recurring "Link is Down" and "Link is Up" cycle for the eth0 interface. This could indicate network instability, a cable issue, or a problem with the network card. Verifying the network cable, switch, or network card could help. 3. mpt2sas Log Entries: The "mpt2sas_cm0: log_info" messages might indicate a hardware issue related to your SAS controller. Consider checking the controller's health, firmware, and updating if necessary.
-
If you don't have a separate syslog server then enable syslog mirroring to flash, that will write all events to the log directory and will hopefully help you help you figure out whats causing the shutdown. Just remember to turn it off again and delete the logs from your flash when you are done.
-
Vivaldi
-
Also testing now, it's certainly an improvement!
-
Are you using the VPN manager in settings? I thought the wireguard plugin got depreciated a long time ago. I'm running WG without issues. If you are using the sam check your config against mine. Also assuming you've done your port forwarding on your router as well?
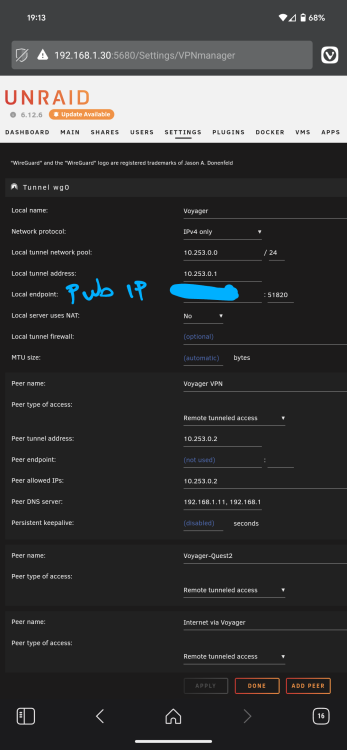
-
Ok ill try that, thank you.
-
I keep getting an error on my appdata backup (errors below). Tar files are being made, I see 80GB files in the backup directory. When i go to restore my appdata it only allows me to select the non errored backup from 2022-08-01. Any folder names that contain 'error' can't be used. I assume if i rename the folder it will take but im curious if someone could advise what the error is or how to investigate this? I dont need the backups at the moment, just doing some housekeeping on the server. [20.03.2023 03:00:01] Backup of appData starting. This may take awhile [20.03.2023 03:00:01] AdGuard-Home set to not be stopped by ca backup's advanced settings. Skipping [20.03.2023 03:00:01] Stopping binhex-krusader... done! (took 0 seconds) [20.03.2023 03:00:01] Not stopping binhex-minidlna: Not started! [ / Created] [20.03.2023 03:00:01] Stopping binhex-prowlarr... done! (took 0 seconds) [20.03.2023 03:00:01] Not stopping changedetection.io: Not started! [ / Created] [20.03.2023 03:00:01] Stopping EmbyServer... done! (took 4 seconds) [20.03.2023 03:00:05] Stopping MariaDB-Official... done! (took 1 seconds) [20.03.2023 03:00:06] Stopping nextcloud... done! (took 4 seconds) [20.03.2023 03:00:10] Stopping Nginx-Proxy-Manager-Official... done! (took 4 seconds) [20.03.2023 03:00:14] Stopping overseerr... done! (took 4 seconds) [20.03.2023 03:00:18] Not stopping Portainer-CE: Not started! [ / Created] [20.03.2023 03:00:18] Stopping qbittorrent... done! (took 8 seconds) [20.03.2023 03:00:26] Stopping radarr... done! (took 4 seconds) [20.03.2023 03:00:30] Stopping Sonarr... done! (took 4 seconds) [20.03.2023 03:00:34] Not stopping syncthing: Not started! [ / Created] [20.03.2023 03:00:34] unifi-controller set to not be stopped by ca backup's advanced settings. Skipping [20.03.2023 03:00:34] Stopping unpackerr... done! (took 4 seconds) [20.03.2023 03:00:38] Stopping Unraid-API... done! (took 1 seconds) [20.03.2023 03:00:39] Not stopping wikijs: Not started! [ / Created] [20.03.2023 03:00:39] Backing up libvirt.img to /mnt/user/system/libvert/ [20.03.2023 03:00:39] Using Command: /usr/bin/rsync -avXHq --delete --log-file="/var/lib/docker/unraid/ca.backup2.datastore/appdata_backup.log" "/mnt/user/system/libvert/libvirt.img" "/mnt/user/system/libvert/" > /dev/null 2>&1 2023/03/20 03:00:39 [3469] building file list 2023/03/20 03:00:39 [3469] sent 68 bytes received 12 bytes 160.00 bytes/sec 2023/03/20 03:00:39 [3469] total size is 1,073,741,824 speedup is 13,421,772.80 [20.03.2023 03:00:39] Backing Up appData from /mnt/user/appdata/ to /mnt/user0/backups/appdata backup/[email protected] [20.03.2023 03:00:39] Separate archives disabled! Saving into one file. [20.03.2023 03:00:39] Backing Up [20.03.2023 03:17:35] Verifying Backup ./unifi-controller/data/db/diagnostic.data/metrics.2023-03-19T00-01-15Z-00000: Mod time differs ./unifi-controller/data/db/diagnostic.data/metrics.2023-03-19T00-01-15Z-00000: Size differs ./unifi-controller/data/db/diagnostic.data/metrics.interim: Mod time differs ./unifi-controller/data/db/diagnostic.data/metrics.interim: Size differs ./unifi-controller/data/db/WiredTiger.turtle: Mod time differs ./unifi-controller/data/db/WiredTiger.turtle: Contents differ ./unifi-controller/data/db/journal/WiredTigerLog.0000000468: Mod time differs ./unifi-controller/data/db/journal/WiredTigerLog.0000000468: Contents differ ./unifi-controller/data/db/WiredTiger.wt: Mod time differs ./unifi-controller/data/db/WiredTiger.wt: Contents differ ./unifi-controller/data/db/sizeStorer.wt: Mod time differs ./unifi-controller/data/db/sizeStorer.wt: Contents differ ./unifi-controller/data/db/collection-101--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-101--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-215--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-215--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-179--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-179--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-323-3780217339629934391.wt: Mod time differs ./unifi-controller/data/db/collection-323-3780217339629934391.wt: Contents differ ./unifi-controller/data/db/collection-206--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-206--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-186--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-186--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-190--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-190--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-36--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-36--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-102--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-102--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-103--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-103--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-104--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-104--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-105--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-105--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-106--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-106--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-107--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-107--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-158--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-158--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-165--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-165--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-180--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-180--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-187--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-187--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-188--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-188--632181887443358492.wt: Size differs ./unifi-controller/data/db/index-189--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-189--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-191--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-191--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-192--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-192--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-193--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-193--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-207--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-207--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-208--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-208--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-209--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-209--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-216--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-216--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-217--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-217--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-218--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-218--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-41--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-41--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-42--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-42--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-0--8116669766152780928.wt: Mod time differs ./unifi-controller/data/db/collection-0--8116669766152780928.wt: Contents differ ./unifi-controller/data/db/index-1--8116669766152780928.wt: Mod time differs ./unifi-controller/data/db/index-1--8116669766152780928.wt: Contents differ ./unifi-controller/data/db/index-2--8116669766152780928.wt: Mod time differs ./unifi-controller/data/db/index-2--8116669766152780928.wt: Contents differ ./unifi-controller/data/db/index-1-622574346060731590.wt: Mod time differs ./unifi-controller/data/db/index-1-622574346060731590.wt: Contents differ ./unifi-controller/data/db/index-15-622574346060731590.wt: Mod time differs ./unifi-controller/data/db/index-15-622574346060731590.wt: Contents differ ./unifi-controller/data/db/index-16-622574346060731590.wt: Mod time differs ./unifi-controller/data/db/index-16-622574346060731590.wt: Size differs [20.03.2023 03:36:50] tar verify failed! [20.03.2023 03:36:50] done [20.03.2023 03:36:50] Starting qbittorrent... (try #1) done! [20.03.2023 03:36:50] Waiting 2 seconds before carrying on [20.03.2023 03:36:52] Starting Unraid-API... (try #1) done! [20.03.2023 03:36:53] Waiting 2 seconds before carrying on [20.03.2023 03:36:55] Starting Nginx-Proxy-Manager-Official... (try #1) done! [20.03.2023 03:36:55] Waiting 2 seconds before carrying on [20.03.2023 03:36:57] Starting unpackerr... (try #1) done! [20.03.2023 03:36:59] Starting binhex-prowlarr... (try #1) done! [20.03.2023 03:36:59] Waiting 2 seconds before carrying on [20.03.2023 03:37:01] Starting radarr... (try #1) done! [20.03.2023 03:37:02] Waiting 1 seconds before carrying on [20.03.2023 03:37:03] Starting Sonarr... (try #1) done! [20.03.2023 03:37:03] Waiting 1 seconds before carrying on [20.03.2023 03:37:04] Starting overseerr... (try #1) done! [20.03.2023 03:37:05] Waiting 2 seconds before carrying on [20.03.2023 03:37:07] Starting EmbyServer... (try #1) done! [20.03.2023 03:37:10] Starting MariaDB-Official... (try #1) done! [20.03.2023 03:37:10] Waiting 2 seconds before carrying on [20.03.2023 03:37:12] Starting nextcloud... (try #1) done! [20.03.2023 03:37:12] Waiting 2 seconds before carrying on [20.03.2023 03:37:14] Starting binhex-krusader... (try #1) done! [20.03.2023 03:37:15] Waiting 2 seconds before carrying on [20.03.2023 03:37:17] A error occurred somewhere. Not deleting old backup sets of appdata [20.03.2023 03:37:17] Backup / Restore Completed
-
I keep getting an error on my appdata backup (errors below). Tar files are being made, See screenshot 2. When i go to restore my appdata it only allows me to select the non errored backup from 2022-08-01. I assume if i rename the folder it will take but im curious if someone could advise what the error is or how to investigate this? I dont need the backups at the moment, just doing some housekeeping on the server. [20.03.2023 03:00:01] Backup of appData starting. This may take awhile [20.03.2023 03:00:01] AdGuard-Home set to not be stopped by ca backup's advanced settings. Skipping [20.03.2023 03:00:01] Stopping binhex-krusader... done! (took 0 seconds) [20.03.2023 03:00:01] Not stopping binhex-minidlna: Not started! [ / Created] [20.03.2023 03:00:01] Stopping binhex-prowlarr... done! (took 0 seconds) [20.03.2023 03:00:01] Not stopping changedetection.io: Not started! [ / Created] [20.03.2023 03:00:01] Stopping EmbyServer... done! (took 4 seconds) [20.03.2023 03:00:05] Stopping MariaDB-Official... done! (took 1 seconds) [20.03.2023 03:00:06] Stopping nextcloud... done! (took 4 seconds) [20.03.2023 03:00:10] Stopping Nginx-Proxy-Manager-Official... done! (took 4 seconds) [20.03.2023 03:00:14] Stopping overseerr... done! (took 4 seconds) [20.03.2023 03:00:18] Not stopping Portainer-CE: Not started! [ / Created] [20.03.2023 03:00:18] Stopping qbittorrent... done! (took 8 seconds) [20.03.2023 03:00:26] Stopping radarr... done! (took 4 seconds) [20.03.2023 03:00:30] Stopping Sonarr... done! (took 4 seconds) [20.03.2023 03:00:34] Not stopping syncthing: Not started! [ / Created] [20.03.2023 03:00:34] unifi-controller set to not be stopped by ca backup's advanced settings. Skipping [20.03.2023 03:00:34] Stopping unpackerr... done! (took 4 seconds) [20.03.2023 03:00:38] Stopping Unraid-API... done! (took 1 seconds) [20.03.2023 03:00:39] Not stopping wikijs: Not started! [ / Created] [20.03.2023 03:00:39] Backing up libvirt.img to /mnt/user/system/libvert/ [20.03.2023 03:00:39] Using Command: /usr/bin/rsync -avXHq --delete --log-file="/var/lib/docker/unraid/ca.backup2.datastore/appdata_backup.log" "/mnt/user/system/libvert/libvirt.img" "/mnt/user/system/libvert/" > /dev/null 2>&1 2023/03/20 03:00:39 [3469] building file list 2023/03/20 03:00:39 [3469] sent 68 bytes received 12 bytes 160.00 bytes/sec 2023/03/20 03:00:39 [3469] total size is 1,073,741,824 speedup is 13,421,772.80 [20.03.2023 03:00:39] Backing Up appData from /mnt/user/appdata/ to /mnt/user0/backups/appdata backup/[email protected] [20.03.2023 03:00:39] Separate archives disabled! Saving into one file. [20.03.2023 03:00:39] Backing Up [20.03.2023 03:17:35] Verifying Backup ./unifi-controller/data/db/diagnostic.data/metrics.2023-03-19T00-01-15Z-00000: Mod time differs ./unifi-controller/data/db/diagnostic.data/metrics.2023-03-19T00-01-15Z-00000: Size differs ./unifi-controller/data/db/diagnostic.data/metrics.interim: Mod time differs ./unifi-controller/data/db/diagnostic.data/metrics.interim: Size differs ./unifi-controller/data/db/WiredTiger.turtle: Mod time differs ./unifi-controller/data/db/WiredTiger.turtle: Contents differ ./unifi-controller/data/db/journal/WiredTigerLog.0000000468: Mod time differs ./unifi-controller/data/db/journal/WiredTigerLog.0000000468: Contents differ ./unifi-controller/data/db/WiredTiger.wt: Mod time differs ./unifi-controller/data/db/WiredTiger.wt: Contents differ ./unifi-controller/data/db/sizeStorer.wt: Mod time differs ./unifi-controller/data/db/sizeStorer.wt: Contents differ ./unifi-controller/data/db/collection-101--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-101--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-215--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-215--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-179--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-179--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-323-3780217339629934391.wt: Mod time differs ./unifi-controller/data/db/collection-323-3780217339629934391.wt: Contents differ ./unifi-controller/data/db/collection-206--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-206--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-186--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-186--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-190--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-190--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-36--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/collection-36--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-102--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-102--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-103--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-103--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-104--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-104--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-105--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-105--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-106--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-106--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-107--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-107--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-158--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-158--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-165--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-165--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-180--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-180--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-187--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-187--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-188--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-188--632181887443358492.wt: Size differs ./unifi-controller/data/db/index-189--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-189--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-191--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-191--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-192--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-192--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-193--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-193--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-207--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-207--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-208--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-208--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-209--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-209--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-216--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-216--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-217--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-217--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-218--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-218--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-41--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-41--632181887443358492.wt: Contents differ ./unifi-controller/data/db/index-42--632181887443358492.wt: Mod time differs ./unifi-controller/data/db/index-42--632181887443358492.wt: Contents differ ./unifi-controller/data/db/collection-0--8116669766152780928.wt: Mod time differs ./unifi-controller/data/db/collection-0--8116669766152780928.wt: Contents differ ./unifi-controller/data/db/index-1--8116669766152780928.wt: Mod time differs ./unifi-controller/data/db/index-1--8116669766152780928.wt: Contents differ ./unifi-controller/data/db/index-2--8116669766152780928.wt: Mod time differs ./unifi-controller/data/db/index-2--8116669766152780928.wt: Contents differ ./unifi-controller/data/db/index-1-622574346060731590.wt: Mod time differs ./unifi-controller/data/db/index-1-622574346060731590.wt: Contents differ ./unifi-controller/data/db/index-15-622574346060731590.wt: Mod time differs ./unifi-controller/data/db/index-15-622574346060731590.wt: Contents differ ./unifi-controller/data/db/index-16-622574346060731590.wt: Mod time differs ./unifi-controller/data/db/index-16-622574346060731590.wt: Size differs [20.03.2023 03:36:50] tar verify failed! [20.03.2023 03:36:50] done [20.03.2023 03:36:50] Starting qbittorrent... (try #1) done! [20.03.2023 03:36:50] Waiting 2 seconds before carrying on [20.03.2023 03:36:52] Starting Unraid-API... (try #1) done! [20.03.2023 03:36:53] Waiting 2 seconds before carrying on [20.03.2023 03:36:55] Starting Nginx-Proxy-Manager-Official... (try #1) done! [20.03.2023 03:36:55] Waiting 2 seconds before carrying on [20.03.2023 03:36:57] Starting unpackerr... (try #1) done! [20.03.2023 03:36:59] Starting binhex-prowlarr... (try #1) done! [20.03.2023 03:36:59] Waiting 2 seconds before carrying on [20.03.2023 03:37:01] Starting radarr... (try #1) done! [20.03.2023 03:37:02] Waiting 1 seconds before carrying on [20.03.2023 03:37:03] Starting Sonarr... (try #1) done! [20.03.2023 03:37:03] Waiting 1 seconds before carrying on [20.03.2023 03:37:04] Starting overseerr... (try #1) done! [20.03.2023 03:37:05] Waiting 2 seconds before carrying on [20.03.2023 03:37:07] Starting EmbyServer... (try #1) done! [20.03.2023 03:37:10] Starting MariaDB-Official... (try #1) done! [20.03.2023 03:37:10] Waiting 2 seconds before carrying on [20.03.2023 03:37:12] Starting nextcloud... (try #1) done! [20.03.2023 03:37:12] Waiting 2 seconds before carrying on [20.03.2023 03:37:14] Starting binhex-krusader... (try #1) done! [20.03.2023 03:37:15] Waiting 2 seconds before carrying on [20.03.2023 03:37:17] A error occurred somewhere. Not deleting old backup sets of appdata [20.03.2023 03:37:17] Backup / Restore Completed
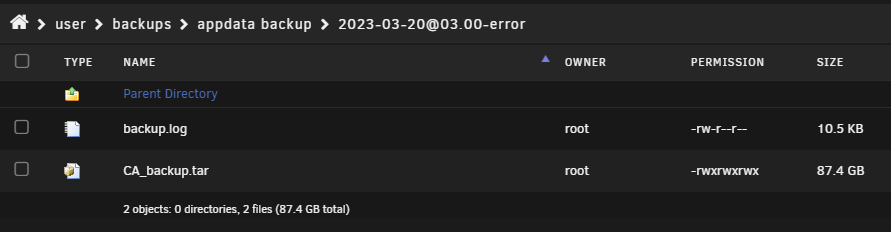
-
I also have an issue with my Unifi Controller flagging multiple devices are using the same IP because the shim is using the same IP as my Unraid server IP.
-
Oh ok, I must check the XML. Maybe the same had happened in the XML but it's displayed differently in the GUI dropdowns.
-
It sounds a bit similar. Have you tried testing the transfer speed in Unraid only (not the VM) with the same usb device & port? I never found an issue to this problem.
-
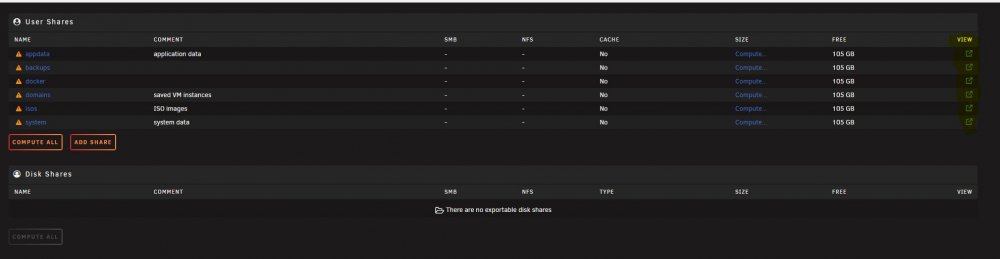
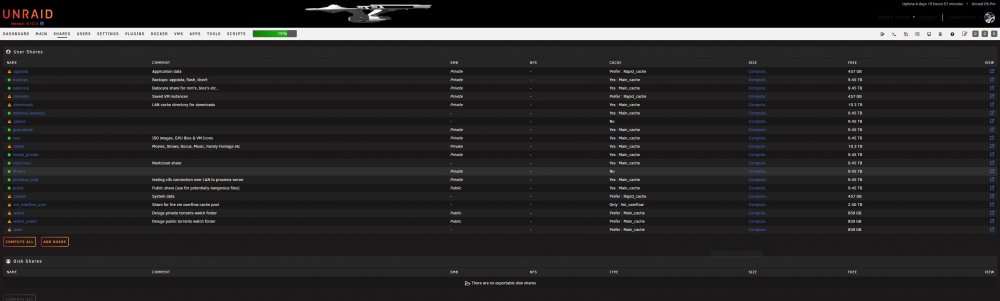
Could there be any way to code in an option to move the "view" column where you open "file browser" (hilighted in yellow in IMAGE1) over to the left side of the shares and disks tables. Its not too bad on my test server (IMAGE1) but its annoying on my production ultrawide with the Unlimited Width plugin (IMAGE2). In a traditional sense you would open a folder by clicking the name or the folder icon which is beside the name. Having the entry point to the folder for browsing all the way on the other side of the window is a slow. My eyes constantly have to drift across the screen to verify if im hovering on the correct entry point. IMAGE1: IMAGE2: