




Gnomuz
Members
-
Joined
-
Last visited
-
Hi there, A new version seems to be available, an updated image would be appreciated
-
Hi, It seems a new version is available and an update of the docker image is required. Thanks in advance.
-
Thanks for the update, running again
-
Hi there, It seems there's been a new version of Crash Plan for 3 days or so, and it's repeatedly trying to update, ofc without success. Thanks in advance for an updated image !
-
Just updated the container, thanks for the quick support as usual
-
Hello, An upgrade of Crashplan to a new version 15252000006882 is attempting to install, thanks in advance for upgrading the container if ever the upgrade were to become mandatory later.
-
The latest version of the official telegraf container no longer runs as root, which explains the issue. Here I used "telegraf:latest" (i.e. 1.20.3 currently), with apt-get update and install commands in the Post Argument, and ofc that can't work without root privileges. Pulling "telegraf:1.20.2" instead (previous version running as root) solved the issue, but it's only a temporary workaround ...
-
Thanks for the feedback, I had noticed this "not-available" exit code but didn't pay attention it was a 'Warning" log entry. So I understand the problem would be in the scan phase. If I may, the warning line you point out is related with the first file, the one that unBALANCE will move happily : I: 2021/09/16 22:15:26 planner.go:351: scanning:disk(/mnt/disk2):folder(XXXX/portables/1f7n0em0/plot-k32-2021-07-26-14-12-92fa0e550e27c898b01b7d7b839da2a60d7b2ad6f55a9ecf86f1a78627a62b4e.plot) W: 2021/09/16 22:15:26 planner.go:362: issues:not-available:(exit status 1) I: 2021/09/16 22:15:26 planner.go:380: items:count(1):size(108.83 GB) I: 2021/09/16 22:15:26 planner.go:351: scanning:disk(/mnt/disk2):folder(XXXX/portables/1f7n0em0/plot-k32-2021-07-26-15-08-b9330f6ab9e903b464cc97adfecb410f678c90d51b702dbde33c9b58d36de453.plot) W: 2021/09/16 22:15:26 planner.go:362: issues:not-available:(exit status 1) I: 2021/09/16 22:15:26 planner.go:380: items:count(1):size(108.84 GB) I: 2021/09/16 22:15:26 planner.go:110: scatterPlan:items(2) The warnings are the same on both files, but in the end the result of the planning phase is that the first file is transferred, the second is not. And it's the same if I select 3 of them or more, only the first one is selected for transfer as expected, the next ones "will NOT be transferred", same warning on all files including the first one in the scan phase. Permissions and timestamps seem fine -rw-rw-rw- 1 nobody users 102G Jul 26 15:36 plot-k32-2021-07-26-14-12-92fa0e550e27c898b01b7d7b839da2a60d7b2ad6f55a9ecf86f1a78627a62b4e.plot -rw-rw-rw- 1 nobody users 102G Jul 26 16:33 plot-k32-2021-07-26-15-08-b9330f6ab9e903b464cc97adfecb410f678c90d51b702dbde33c9b58d36de453.plot As for a file corruption, these are chia plots as you have seen. There are chia specific tools which check the integrity of the plots and I'm positively sure these are not corrupted at application level, a fortiori at block level. Other similar transfers worked just fine with unBALANCE on smaller files. I also transferred manually a few chia plots with CLI from disk2 to disk3 using the exact same rsync command as the one generated by unBALANCE, it worked like a charm. So I really suspect the unitary size of the files somehow raises an exception in the code behind the "scan" phase, which prevents the transfer of more than one file at a time. Should you need any further information from me, do not hesitate.
-
Thanks for answering, but sorry, I didn't solve it in the meantime. I tried to set the reserved space to the minimum with no effect. Here are the logs when I plan for transferring two ~109GB files to a drive (disk3) with 5.2 TB free : I: 2021/09/16 22:15:26 planner.go:70: Running scatter planner ... I: 2021/09/16 22:15:26 planner.go:84: scatterPlan:source:(/mnt/disk2) I: 2021/09/16 22:15:26 planner.go:86: scatterPlan:dest:(/mnt/disk3) I: 2021/09/16 22:15:26 planner.go:520: planner:array(8 disks):blockSize(4096) I: 2021/09/16 22:15:26 planner.go:522: disk(/mnt/disk1):fs(xfs):size(3998833471488):free(2304975196160):blocksTotal(976277703):blocksFree(562738085) I: 2021/09/16 22:15:26 planner.go:522: disk(/mnt/disk2):fs(xfs):size(3998833471488):free(509188435968):blocksTotal(976277703):blocksFree(124313583) I: 2021/09/16 22:15:26 planner.go:522: disk(/mnt/disk3):fs(xfs):size(13998382592000):free(5195027685376):blocksTotal(3417573875):blocksFree(1268317306) I: 2021/09/16 22:15:26 planner.go:522: disk(/mnt/disk4):fs(xfs):size(13998382592000):free(30423252992):blocksTotal(3417573875):blocksFree(7427552) I: 2021/09/16 22:15:26 planner.go:522: disk(/mnt/disk5):fs(xfs):size(13998382592000):free(30410973184):blocksTotal(3417573875):blocksFree(7424554) I: 2021/09/16 22:15:26 planner.go:522: disk(/mnt/disk6):fs(xfs):size(13998382592000):free(30273011712):blocksTotal(3417573875):blocksFree(7390872) I: 2021/09/16 22:15:26 planner.go:522: disk(/mnt/disk7):fs(xfs):size(13998382592000):free(29930565632):blocksTotal(3417573875):blocksFree(7307267) I: 2021/09/16 22:15:26 planner.go:522: disk(/mnt/cache):fs(xfs):size(511859089408):free(246631960576):blocksTotal(124965598):blocksFree(60212881) I: 2021/09/16 22:15:26 planner.go:351: scanning:disk(/mnt/disk2):folder(Chia/portables/1f7n0em0/plot-k32-2021-07-26-14-12-92fa0e550e27c898b01b7d7b839da2a60d7b2ad6f55a9ecf86f1a78627a62b4e.plot) W: 2021/09/16 22:15:26 planner.go:362: issues:not-available:(exit status 1) I: 2021/09/16 22:15:26 planner.go:380: items:count(1):size(108.83 GB) I: 2021/09/16 22:15:26 planner.go:351: scanning:disk(/mnt/disk2):folder(Chia/portables/1f7n0em0/plot-k32-2021-07-26-15-08-b9330f6ab9e903b464cc97adfecb410f678c90d51b702dbde33c9b58d36de453.plot) W: 2021/09/16 22:15:26 planner.go:362: issues:not-available:(exit status 1) I: 2021/09/16 22:15:26 planner.go:380: items:count(1):size(108.84 GB) I: 2021/09/16 22:15:26 planner.go:110: scatterPlan:items(2) I: 2021/09/16 22:15:26 planner.go:113: scatterPlan:found(/mnt/disk2/Chia/portables/1f7n0em0/plot-k32-2021-07-26-14-12-92fa0e550e27c898b01b7d7b839da2a60d7b2ad6f55a9ecf86f1a78627a62b4e.plot):size(108828032623) I: 2021/09/16 22:15:26 planner.go:113: scatterPlan:found(/mnt/disk2/Chia/portables/1f7n0em0/plot-k32-2021-07-26-15-08-b9330f6ab9e903b464cc97adfecb410f678c90d51b702dbde33c9b58d36de453.plot):size(108835523381) I: 2021/09/16 22:15:26 planner.go:120: scatterPlan:issues:owner(0),group(0),folder(0),file(0) I: 2021/09/16 22:15:26 planner.go:129: scatterPlan:Trying to allocate items to disk3 ... I: 2021/09/16 22:15:26 planner.go:134: scatterPlan:ItemsLeft(2):ReservedSpace(536870912) I: 2021/09/16 22:15:26 planner.go:463: scatterPlan:1 items will be transferred. I: 2021/09/16 22:15:26 planner.go:465: scatterPlan:willBeTransferred(Chia/portables/1f7n0em0/plot-k32-2021-07-26-14-12-92fa0e550e27c898b01b7d7b839da2a60d7b2ad6f55a9ecf86f1a78627a62b4e.plot) I: 2021/09/16 22:15:26 planner.go:473: scatterPlan:1 items will NOT be transferred. I: 2021/09/16 22:15:26 planner.go:479: scatterPlan:notTransferred(Chia/portables/1f7n0em0/plot-k32-2021-07-26-15-08-b9330f6ab9e903b464cc97adfecb410f678c90d51b702dbde33c9b58d36de453.plot) I: 2021/09/16 22:15:26 planner.go:488: scatterPlan:ItemsLeft(1) I: 2021/09/16 22:15:26 planner.go:489: scatterPlan:Listing (8) disks ... I: 2021/09/16 22:15:26 planner.go:503: ========================================================= I: 2021/09/16 22:15:26 planner.go:504: disk(/mnt/disk1):no-items:currentFree(2.30 TB) I: 2021/09/16 22:15:26 planner.go:505: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:506: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:507: I: 2021/09/16 22:15:26 planner.go:503: ========================================================= I: 2021/09/16 22:15:26 planner.go:504: disk(/mnt/disk2):no-items:currentFree(509.19 GB) I: 2021/09/16 22:15:26 planner.go:505: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:506: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:507: I: 2021/09/16 22:15:26 planner.go:492: ========================================================= I: 2021/09/16 22:15:26 planner.go:493: disk(/mnt/disk3):items(1)-(108.83 GB):currentFree(5.20 TB)-plannedFree(5.09 TB) I: 2021/09/16 22:15:26 planner.go:494: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:497: [108.83 GB] Chia/portables/1f7n0em0/plot-k32-2021-07-26-14-12-92fa0e550e27c898b01b7d7b839da2a60d7b2ad6f55a9ecf86f1a78627a62b4e.plot I: 2021/09/16 22:15:26 planner.go:500: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:501: I: 2021/09/16 22:15:26 planner.go:503: ========================================================= I: 2021/09/16 22:15:26 planner.go:504: disk(/mnt/disk4):no-items:currentFree(30.42 GB) I: 2021/09/16 22:15:26 planner.go:505: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:506: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:507: I: 2021/09/16 22:15:26 planner.go:503: ========================================================= I: 2021/09/16 22:15:26 planner.go:504: disk(/mnt/disk5):no-items:currentFree(30.41 GB) I: 2021/09/16 22:15:26 planner.go:505: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:506: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:507: I: 2021/09/16 22:15:26 planner.go:503: ========================================================= I: 2021/09/16 22:15:26 planner.go:504: disk(/mnt/disk6):no-items:currentFree(30.27 GB) I: 2021/09/16 22:15:26 planner.go:505: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:506: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:507: I: 2021/09/16 22:15:26 planner.go:503: ========================================================= I: 2021/09/16 22:15:26 planner.go:504: disk(/mnt/disk7):no-items:currentFree(29.93 GB) I: 2021/09/16 22:15:26 planner.go:505: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:506: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:507: I: 2021/09/16 22:15:26 planner.go:503: ========================================================= I: 2021/09/16 22:15:26 planner.go:504: disk(/mnt/cache):no-items:currentFree(246.63 GB) I: 2021/09/16 22:15:26 planner.go:505: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:506: --------------------------------------------------------- I: 2021/09/16 22:15:26 planner.go:507: I: 2021/09/16 22:15:26 planner.go:511: ========================================================= I: 2021/09/16 22:15:26 planner.go:512: Bytes To Transfer: 108.83 GB I: 2021/09/16 22:15:26 planner.go:513: --------------------------------------------------------- It clearly states that the second file will NOT be transferred, without further obvious explanation. I suspect the problem is due to the huge size of the files, as I managed to transfer multiple smaller files from disk2 to disk3 without any issue. Maybe some kind of overflow in an intermediate variable ? Thanks in advance for your support.
-
Hi, I've been using unBALANCE for quite some time now, it's really a great tool to reorganize data among disks. I have recently upgraded some of my disks to a higher capacity and hence reallocate their usage. And now I have an issue as I have some big files of ~100GiB to transfer in this example from disk2 to disk3. disk2 has 509GB free, and disk3 has 5.2TB free. Here's the output of the "Plan" phase when I try to transfer more than one file : PLANNING: Found /mnt/disk2/<sharename>/file1 (108.83 GB) PLANNING: Found /mnt/disk2/<sharename>/file2 (108.84 GB) PLANNING: Trying to allocate items to disk3 ... PLANNING: Ended: Sep 9, 2021 22:41:06 PLANNING: Elapsed: 0s PLANNING: The following items will not be transferred, because there's not enough space in the target disks: PLANNING: <sharename>/file2 PLANNING: Planning Finished I can transfer the files one at a time, but if I try to select two or more files, unBALANCE refuses to move after the first "because there's not enough space in the target disks:". No disk is indicated. Below a snapshot of the array : The share is set to include disk2 to disk7. As can be seen, disk4 to disk7 haven't 100GB free, but of course I only target disk3 in the move operation as the log shows. Also, I've never used unBALANCE before on such big files, maybe it's another possible cause. Any help or advice would be appreciated.

-
Hi, I think a new version is available, as my logs have been mentioning unsuccessful upgrade attempts for ~18 hours.
-
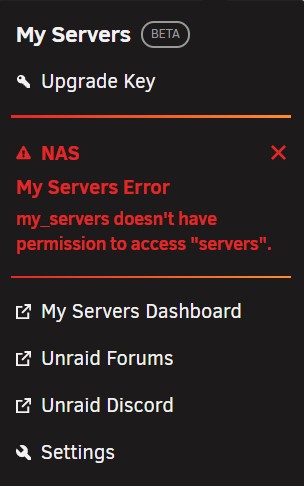
I just updated to 2021.06.07.1554. Everything seems fine, but I get the following error message in the dropdown :
-
I don't see any solution to change dynamically the final destination directory for a running plotting process. But if the final copy fails, due to destination drive full for instance, the process doesn't delete the final file in your temp directory, so you can just copy it manually to a destination with free space, and delete it from your temp directory once done.
-
I can't see then, but it's strange that your prompt is "#", like in unRAID terminal, where mine is "root@57ad7c0830ad:/chia-blockchain#" in the container console as you can see. Sorry, I can't help further, it must be something obvious, but it's a bit late here !
-
You have to be in the chia-blockchain directory, which happens to be a root directory in this container, for all that to work : cd /chia-blockchain source ./activate Here's the result in my container ; root@57ad7c0830ad:/chia-blockchain# cd /chia-blockchain root@57ad7c0830ad:/chia-blockchain# source ./activate (venv) root@57ad7c0830ad:/chia-blockchain# chia version 1.1.7.dev0 (venv) root@57ad7c0830ad:/chia-blockchain# Hey, btw, these commands must be entered in the container console, NOT in the unRAID terminal !



