




K1ng0011
Members
-
Joined
-
Last visited
Everything posted by K1ng0011
-
Perfect its fixed now my fans are being controlled via the unraid service docker I created. I also noticed the following issue below. I know I am just nit picking but the spelling is off. Also I find it odd that in the actual docker for the open fan controller that the max fan speed is 3000 rpm. Maybe there is a reason that I am not aware of but some fans like mine are capable of more than 3000rpm. Fix the "Crate new profile"
-
I have an odd issue. I have three drive cages. Each cage has the same fan in it. These PWM fans are capable of 4500rpm. When I am running the openfan docker I can manually adjust the PWM percentage of each fan and watch the RPM increase. When running the openfan unraid service docker the FAN#4 in my config wants to set itself to about 1500 RPM. I can see in the logs as the drive temp increases the unraid service docker continues to increase the commanded pwm percentage up to 90% but the fan stays around 1500rpm. The other fans seem to work fine. I did not find a reason for this behavior in the YAML config. Unraid Version: 7.1.2 fan_profiles.yaml
-
Yah I saw that as an option also. Unfortunately I live in the US and due to reasons (tariffs) the creator of the open fan is currently not selling to US customers. So this is not an option currently for me.
-
Anyone know of a fan controller that I could buy that this plugin would support natively. I am looking to control five fans. I may not be able to use my built in motherboard fan controller so I am looking for a different solution.
-
I have a Asrock Rack X470D4U2-2T. I can see the fan speeds in the IPMI tool but I cannot control the fans. On the fan control page I see the message (fan is not configured!) on all of my fans. Whenever I click the configure button I each of the locations shows none. Seems like it is not detecting the fan. Any idea of the cause. Seems like I might need an IPMI file that I somehow have to put in the unraid filesystem for the plugin to read.
-
I have unRAID Connect setup. To use unRAID Connect you need to setup a port forward for this function. If you know my public IP and the port you can reach my management page for unRAID to login. The unRAID Connect plugin should be reaching out to domains/IP to make the connection between my unRAID box and unRAIDs servers. I would like to know what those domains/IPs are so I can put a firewall policy in that will drop any traffic coming inbound into the port forward except the unRAID domains/IPs
-
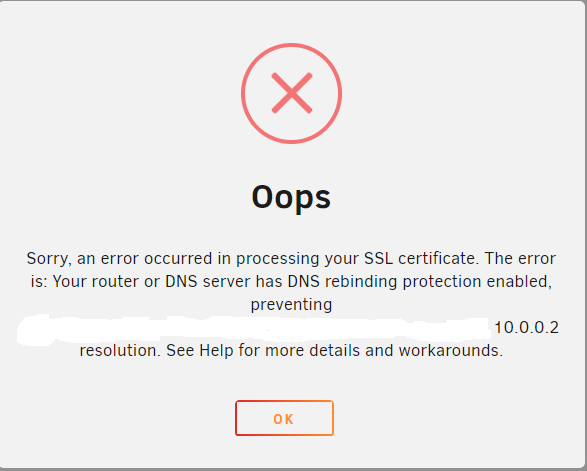
Updated to Unraid 6.10-RC2 based on the comment on this forum post and I was able to get my ssl cert.
-
Looks like my error changed when I tested it again today.
-
I cant provision a cert either and I am on 6.9.2
-
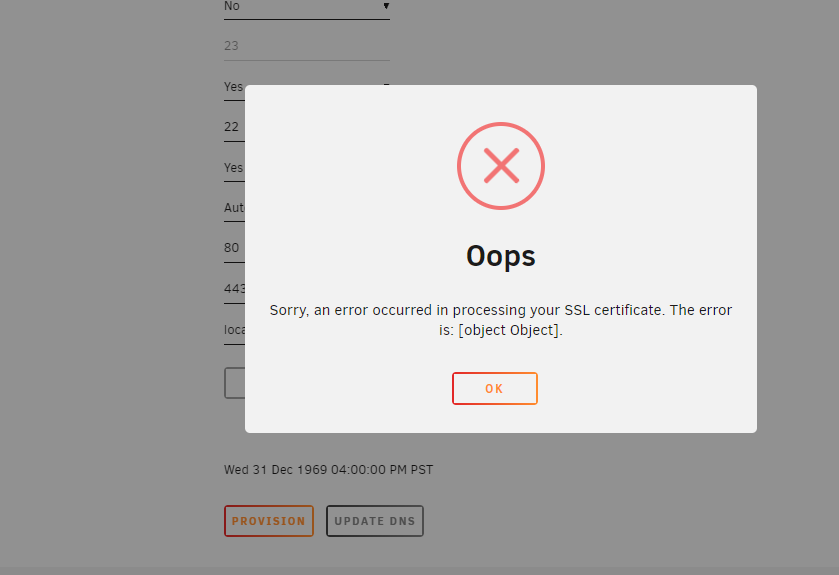
I get and object Object error.
-
I am currently running unraid 6.9.2 and I am in the Settings>Management Access Page. I am trying to provision an SSL cert but it gives me an error of "object Object" and I have no idea what that means. Any help on how to resolve the issue?
-
I am not super familiar with IPMI does anyone know why I am having the following issue? When I hit the configure button it does not appear to actually detect the fans based on what it is showing me. I followed the post that Vendigroth created but it did not seem to remedy the issue. I am also successfully connected to between unraid and the BMC. Motherboard: ASRockRack X470D4U2-2T BMC Version: 1.8.3 BIOS Version: 3.4.0 Unraid Version: 6.9.2 Checking IPMI fan Locations... Location 0-1: none Location 0-2: none Location 0-3: none Location 0-4: none Location 0-5: none Location 0-6: none Location 0-7: none Location 0-8: none Location 0-9: none Location 0-10: none Location 0-11: none Location 0-12: none Location 0-13: none Location 0-14: none Location 0-15: none Location 0-16: none Saving board configuration...
-
I got the newest version of locast2plex 5.3 to work on my unraid 6.8.3. I followed the guide that Untamedgorilla posted. I set my network interface to Custom br0 with a static IP on my network and pointed plex at that IP. I shared my appdata folder on my local network and navigated to it using windows explorer and created the locast2plex folder and saved the config.ini file there. Then I followed Untamedgorilla's path setup and it worked fine. If you are struggling for whatever reason to get versions of 5.x of locast to plex to work you can force v4.2 to install via tgorg/locast2plex:0.4.2 in your repository setting for the locast to plex docker. My docker updated and broke things a while back and I forced the docker to that version until I decided to try v5.3 today. config.ini github: https://github.com/tgorgdotcom/locast2plex/blob/master/config_example.ini common issues: https://github.com/tgorgdotcom/locast2plex/wiki/Troubleshooting-and-Common-Issues docker path to config.ini: /app/config.ini <--> /app/config.ini/mnt/user/appdata/locast2plex/config.ini
-
I found someone with the same issue and the URL to whitelist get.geojs.io https://github.com/tgorgdotcom/locast2plex/issues/28
-
If you run this locast2plex docker through Ad Guard-Home docker it will prevent the docker from starting. Some part of DNS resolution in the geolocation process is being blocked via the Ad Guard-Home docker. I had to go into Ad Guard and stop it temporarily until the docker has finished booting then works fine. I have not figured out the domain it is reaching out to yet. Locast2Plex v0.4.2 DEBUG MODE ACTIVE UUID found. UUID set to: hmwhuwux... Logging into Locast using username Validating User Info... User Info obtained. User didDonate: True User donationExpire: 1600482103 Getting user location... Error during geo IP acquisition: [Errno -2] Name does not resolve Exiting...
-
I am new to unraid but I just saw this post so I thought I would give it a shot to see if I could get it to work. I am happy to report I did get it to work. I was having issues making my docker containers connect to each other (ping). I ended up setting the locast2plex docker container network type to "Host" and I got it to work. However if I end up having issues with that the thread below seems to have a solution to why my plex and locast2plex containers cannot connect to each other.



