




Refrigerator
Members
-
Joined
-
Last visited
-
Is there a way to exclude directories from the scan? Example: I scan /mnt/user/, but I'd like to exclude my Thunderbird directory so that I don't get warnings about spoofed domains (I'm aware that my junk folder contains phishing attempts). Can I pass an argument to tell it to ignore or exclude specific (sub) directories?
-
Everything was going great until it wasn't... Hoping someone might have some insights – did a lot of Googling, but have hit a wall. Issue: After many months of smooth sailing, I can no longer access the web when connected to WireGuard, I only have access to the LAN (Unraid Dashboard plus dockers, even those on their own IPs). Desired behaviour: I want to route my mobile traffic through Unraid and my pi-hole when remote, like I had it going before, via Remote tunneled access. Everything was working fine for months, then it suddenly stopped working Changes to the server prior to the issue: Upgraded from Unraid Plus to Pro Added new parity drives and disks Changed docker network type from macvlan to ipvlan (tried changing back, doesn't seem to be the cause) Handshake and ping successful Wireguard is on a different network pool, as required Unraid v6.10.3 I've tried rebooting Unraid, switching back to macvlan, re-configuring Wireguard from scratch, using 8.8.8.8 as DNS instead of the router's DNS. None of that worked. Port forwarding on the router is correct; as mentioned, I'm able to connect to the VPN, but then just can't access anything external. Here's my config, for what it's worth:
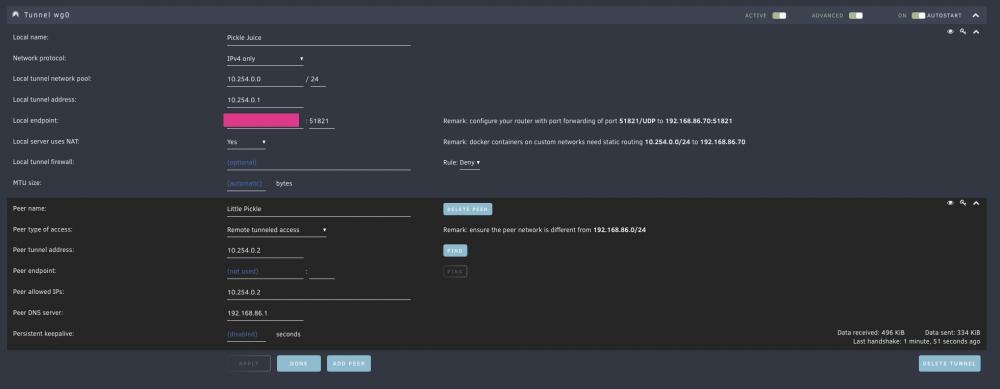
-
Thanks for the suggestion, @JorgeB – I was able to complete the parity sync and switch to ipvlan. So far, the only issue since the change is that Wireguard isn't working properly, which is odd. Anyhow, I'll update the thread in a while to say for sure if this ended up preventing the problem after several days of uptime.
-
Hi there, folks – I've had some crashes recently that have been happening with increasing frequency. I thought it might have been a temperature problem (the room my server is in gets very hot in the summer), but I added more cooling and got another crash this afternoon 80% of the way into a 20 hour parity sync (sigh). I have my diagnostic file and my logs (attached), but I'm finding the log a bit tough to interpret; I'm hoping someone with more specific knowledge might be able to give me a better idea of what the log might be suggesting is the problem. My layman interpretation is it's the CPU experiencing hardware failure and I may need to replace it, but that's almost a guess based on skimming the log. Appreciate any help. Let me know if you need more background. Excerpt right before the crash from the log – more in the attached file: syslog.log tower-diagnostics-20220819-1506.zip
-
OK, just in case someone comes here later with a similar problem – I solved this by using the docker Rebuild-DNDC, which will monitor the host VPN docker and if it goes down, it will rebuild the dependent dockers so that they stay connected. Additionally, I changed the approach to connecting to the host VPN docker, using the creating a new network connection method as outlined here, and that made matters a little easier when adding new docker "children" and whatnot (rather than using the advanced parameters method outlined in this thread's tutorial).
-
@JimmyGerms – how'd you end up fixing this? I have the same problem as you (error below), using prerequisite #2 set up having previously followed the SpaceInvader tutorial as well. /usr/bin/docker: Error response from daemon: Container cannot be connected to network endpoints
-
Similar pickle on my end to @AustinTylerDean's: If the VPN connection goes down in the "parent" docker (with killswitch), e.g., 2021-05-03 16:12:50.229168 [ERROR] Network is down, exiting this Docker All the "child" dockers that rely on the "parent" seem to melt down (Radarr and Sonarr in this case) and are inaccessible until I restart them, despite the "parent" reconnecting moments later. Is there a way around this? It wasn't a problem when going the proxy route (although I agree this method is preferable for other reasons).


