

flyize
-
Posts
429 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by flyize
-
-
I assume it just keeps running even after it shows PASSED?
-
memtest worked fine. And as a refresher, I moved everything off, reformatted, put everything back. It still crashed this morning. After the memtest passed I recreated the docker.img. Then I ran a scrub of /mnt/cache and see this:
Dec 20 14:45:20 Truffle kernel: BTRFS warning (device nvme1n1p1): csum failed root 5 ino 18511597 off 102273024 csum 0x9cd7e7f9 expected csum 0x00000000 mirror 1 Dec 20 14:45:20 Truffle kernel: BTRFS error (device nvme1n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 1, gen 0 Dec 20 14:45:20 Truffle kernel: BTRFS warning (device nvme1n1p1): csum failed root 5 ino 18511597 off 102273024 csum 0x9cd7e7f9 expected csum 0x00000000 mirror 1 Dec 20 14:45:20 Truffle kernel: BTRFS error (device nvme1n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 2, gen 0 Dec 20 14:45:20 Truffle kernel: BTRFS warning (device nvme1n1p1): csum failed root 5 ino 18511597 off 102273024 csum 0x9cd7e7f9 expected csum 0x00000000 mirror 1 Dec 20 14:45:20 Truffle kernel: BTRFS error (device nvme1n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 3, gen 0 Dec 20 14:45:20 Truffle kernel: BTRFS warning (device nvme1n1p1): csum failed root 5 ino 18511597 off 102273024 csum 0x9cd7e7f9 expected csum 0x00000000 mirror 1 Dec 20 14:45:20 Truffle kernel: BTRFS error (device nvme1n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 4, gen 0 Dec 20 14:45:20 Truffle kernel: BTRFS warning (device nvme1n1p1): csum failed root 5 ino 18511597 off 102273024 csum 0x9cd7e7f9 expected csum 0x00000000 mirror 1 Dec 20 14:45:20 Truffle kernel: BTRFS error (device nvme1n1p1): bdev /dev/nvme1n1p1 errs: wr 0, rd 0, flush 0, corrupt 5, gen 0Suggestions?
edit: Note that nvme1n1p1 is a different drive than we were talking about above.
-
That seemed to work perfectly. However, the server crashed again this morning. Running a memtest. Anything else you guys think I should look at?
Thank you so much for all the help so far!
-
Is there a simple 'reformat' command or should I change to XFS then change back?
-
1 minute ago, trurl said:
Why are you talking about reiserfs? None of your disks are reiserfs. I thought we were discussing btrfs disk.
How exactly did you check filesystem?
Apologies for my confusion. The drive is btrfs, and I used the command in the WebGUI with the default --readonly (IIRC) flag.
-
If it matters, the unmountable issue was resolved with a reboot. The server is up and running now without any obvious issue or errors (other than the reiserfsck error listed above).
-
So this drive only contains appdata and *appears* to be working fine. I ran a scrub, which completed without errors. Just to confirm, you're suggesting:
- Shut down VMs and Docker
- Move everything off
- Reformat the drive
- Move everything back
- Restart VMs and Docker
Is there any way to figure out what happened and/or verify that the drive is actually okay?
-
No, just reboot.
-
Actually ran a read-only check and got this back. Should I run a repair? If it matters, its only a single drive.
root 5 inode 4863356 errors 200, dir isize wrong root 5 inode 259419657 errors 1, no inode item unresolved ref dir 4863356 index 3495 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259419732 errors 1, no inode item unresolved ref dir 4863356 index 3501 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259419798 errors 1, no inode item unresolved ref dir 4863356 index 3507 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259419823 errors 1, no inode item unresolved ref dir 4863356 index 3510 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259419861 errors 1, no inode item unresolved ref dir 4863356 index 3513 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259419922 errors 1, no inode item unresolved ref dir 4863356 index 3519 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259419960 errors 1, no inode item unresolved ref dir 4863356 index 3525 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259420005 errors 1, no inode item unresolved ref dir 4863356 index 3531 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259420011 errors 1, no inode item unresolved ref dir 4863356 index 3537 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259420018 errors 1, no inode item unresolved ref dir 4863356 index 3543 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259420022 errors 1, no inode item unresolved ref dir 4863356 index 3549 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259420031 errors 1, no inode item unresolved ref dir 4863356 index 3555 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 259420130 errors 1, no inode item unresolved ref dir 4863356 index 3573 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 264036884 errors 1, no inode item unresolved ref dir 4863356 index 11666 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref root 5 inode 264036930 errors 1, no inode item unresolved ref dir 4863356 index 11696 namelen 15 name tautulli.db-wal filetype 1 errors 5, no dir item, no inode ref ERROR: errors found in fs roots -
Do we know what 'it' possibly is?
-
Hmmm, I rebooted the server and everything seems back to normal. What do I need to check to verify the integrity of that drive?
-
Just now, trurl said:
Did you backup the whole drive to the array or what?
You must disable Docker and VM Manager in Settings until you get your pool fixed.
I used the (new) CA appdata backup tool, as appdata is the only thing on that drive.
-
Not sure if you saw it, but it (thankfully) just happened after a backup. So the solution is to just reformat it (and wipe everything I assume)? What's weird is that while I can't see any files, some Docker containers *are* running.
edit: And if I have to wipe it, what does that process look like?
-
Not sure what my first step should be here. Here's a snip of the errors.
Dec 19 07:18:00 Truffle kernel: BTRFS error (device nvme0n1p1): Unsupported V0 extent filesystem detected. Aborting. Please re-create your filesystem with a newer kernel Dec 19 07:18:00 Truffle kernel: BTRFS: error (device nvme0n1p1) in print_extent_item:96: errno=-22 unknown Dec 19 07:18:00 Truffle kernel: WARNING: CPU: 0 PID: 5745 at fs/btrfs/print-tree.c:166 btrfs_print_leaf+0x5de/0x99e Dec 19 07:18:00 Truffle kernel: CPU: 0 PID: 5745 Comm: btrfs-transacti Not tainted 5.19.17-Unraid #2 Dec 19 07:18:00 Truffle kernel: Call Trace: Dec 19 07:18:00 Truffle kernel: BTRFS error (device nvme0n1p1: state E): block=8761425575936 write time tree block corruption detected -
On 11/29/2022 at 11:15 AM, MaxAbsorbency said:
Define "wifi issues"? I've been running the container most of 2022 without problem. What should I look out for?
You'd know. In my case, just extremely poor wifi performance. It started with my wife's connection too slow and unstable for Zoom meetings. I troubleshooted it off and on for months, assuming it was her PC (BIOS, NIC settings, new NICs, etc). Then it started happening to my PC. And then I would get notifications that my phone dropped offline. That's when I started looking at my wifi infrastructure. In my case, the only thing I have that this container controls is two EAP610 APs.
My APs should be doing the *vast* majority of the work here, so I honestly have no explanation as to why this container would screw things up. I fully admit that it doesn't make sense. But what does make sense is that as soon as I installed the controller into an Ubuntu VM (still on the same Unraid server) all the problems disappeared.
-
I managed to 3d print an extra drive cage to go into my Unraid server. Sucks, but I guess I'll just sell this enclosure.

-
I don't think this warning is as clear as it could be. Do the excluded folders really need to be in the dialog?
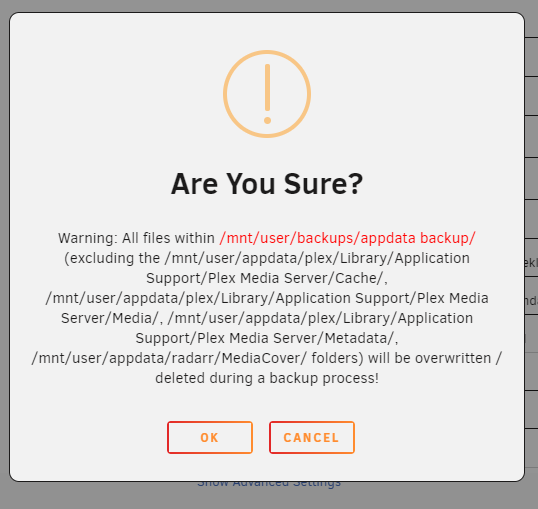
Shouldn't it just say:
Warning: All files within /mnt/user/backups/appdata backup/ will be overwritten / deleted during a backup process!
-
 1
1
-
-
On 12/4/2022 at 11:32 AM, ConnerVT said:
Not even close to an expert at this. But a quick Google search of "ASM1153 SATA 3Gb/s bridge" finds many hits going back ro 2017 and beyond, with other ASM chips at 6Gb/s. Makes me think nothing may have changed in the base kernel/drivers of Linux in general.
Thanks!
Its definitely something that changed in the last couple releases of 6.11. It worked flawlessly before that.
-
Anyone have any idea or am I just dead in the water with this USB enclosure?
-
@limetech any chance you might be able to share some quick wisdom here?
-
Well that's less exciting than I was hoping for.
-
Anyone else here know where I can find out more information about this change? Thanks!
-
Yeah, shouldn't there be a repo somewhere for us to check? It's GPL'd code...
-
Would it be possible for me to find out more information from somewhere? I'd really rather not abandon this thing unless I have to...


unRAIDFindDuplicates.sh
in User Customizations
Posted
Since that uses /mnt/user by default, how can it be setup to search each disk? One of the first replies in that thread seems to suggest that won't, but maybe I'm missing something?