




in_trauma
Members
-
Joined
-
Last visited
-
I was using that last one in my first attempts. The first few times I modified it to my needs to begin and it wouldn't load gui. Then I dropped it in as-is, Since in theory that should just work as-is, but nothing. Nuked it all, changed share and port numbers in the example config. Still nothing. Then I dropped in the sample docker config and it worked. So now im working on modifying to my needs and exploring the app. Thanks for your work and response.
-
Realized I needed to start with the docker compose .conf example and mod to my needs and not the generic .conf linked in the description for the template. Maybe worth updating to link the docker example .conf? Or do people have success starting with the the generic conf template?
-
Re: copyparty Tried several times. Logs look good but the webgui never works. conf file in place I have no port conflicts Tried various other ports Completely removed and started over several times unraid 7.0.0
-
UPDATE: After more trial an error with trying to nail down the problem I found that it was definitely docker related. It had to do with Plex having a host network. So I did the following: Settings > Docker > Host access to custom networks: > set to "Disabled" (was enabled previously) Stop Plex from auto starting and started all other dockers. DuckDNS and Tailscale still both have host networks. I set the unraid box to ping cloudflare 1.1.1.1, 8hr later and it and all was well. Then started Plex container. 4hr later all is well. So, for the time being it seems I've resolved the issue. Now I would just like to learn why this happened. I changed nothing and all of sudden Plex broke things, did a container update change some fundamental setting for communication in the container? Two posts that helps point me in the right direction:
-
Ever find a solution/cause?
-
Same here.
-
TLDR: Starting array I have internet connection, can ping sites from CLI and have remote access via wireguard. When I start docker I get between 2-20minutes before it looses connection. Tried starting one docker at a time looking for patterns but cant nail it down to anyone thing. At a loss as to what to do. unraid Version: 6.11.5 So everything was fine. But, now things are borked and driving me crazy. The only changes that occurred with my unraid setup is that I removed HomeAssistant OS VM and disabled VMs in settings. As for my network, I added a few IOT devices to my network and moved HAOS to a new piece of hardware that I added to the network. That's the only changes. Now unraid looses Internet access/connection shortly after starting array and dockers start. LAN will continue to work, I can access shares and web GUI locally. But connection to the internet and external access drops. Cant even access with Tailscale or Wireguard. No network configs changed on uraid or router. All I did on unraid was stop the VM and disable VMS in settings. The only change on the router was to set static ip for the new HAOS box. When it happens and I attempt to check for docker updates in the web UI will give me an error about DNS and unable to connect and there's no access to my reverse proxies or cloudflare tunnel since it can't connect to internet. Not sure what those DNS IPs are. Of course changing DNS in network settings means stopping all dockers restarting them and things work but then it craps out again after 5-20min. Later, CA Fix Common Problems plug end says change DNS to Google DNS 8.8.8.8/8.8.4.4 I have 4 docker containers that I use externally using reverse proxies or Cloudflare tunnel: - Jellyfin (reverse proxy with SWAG) jellyfin.mydomain.com - Nextcloud (reverse proxy with SWAG) nextcloud.mydomain.com - FileRun (Cloudflare tunnel) filrun.mydomain.com - Filebrowser (Cloudflare tunnel) filebrowser.mydomain.com Also have Tailscale and Wireguard setup. Looking at the unraid log, there's no errors or warnings but I do see this at times: (TOWER is unraid) Jul 15 18:09:09 Tower nmbd[6696]: [2023/07/15 18:09:09.966523, 0] ../../source3/nmbd/nmbd_become_lmb.c:398(become_local_master_stage2) Jul 15 18:09:09 Tower nmbd[6696]: ***** Jul 15 18:09:09 Tower nmbd[6696]: Jul 15 18:09:09 Tower nmbd[6696]: Samba name server TOWER is now a local master browser for workgroup WORKGROUP on subnet 172.17.0.1 Jul 15 18:09:09 Tower nmbd[6696]: Jul 15 18:09:09 Tower nmbd[6696]: ***** Jul 15 18:09:13 Tower kernel: Everything has been rebooted/restarted (router, switch, unraid). I moved DHCP over to my pi-hole from the router thinking there was an issue with my router but that didn't help. Is my router crapping out for too many devices? I have no idea what's causing this issue. The unRAID box is the only thing on the network with issues now. Unraid and the HAOS box and a few other hardwired devices all have static IPs. There's no IP conflicts. Network setup: - Router (tp-link archer A7) + Switch (unmanaged): 192.168.1.1 - router is DHCP server, DNS servers = 1.1.1.1, 8.8.8.8 - Raspberry pi running pihole: 192.168.1.100 (primary DNS server for LAN) - unraid (static ip) - new HA box (static ip) - 3x computers, ~15 IOT devices (tvs, plugs, chromecasts, etc...) Also still curious about the message spamming my logs link to that post here tower-diagnostics-20230716-1236.zip
-
Not sure what this is or if it's a concern but my logs spammed with this a few times a minute. Nothing else in the logs of note. No warnings, no errors. The only post I could find with similar message on unraid mentioned C states of SSDs but doesn't really make sense to me? System info: Unraid v6.11.5 M/B: ASRockRack E3C246D4U2-2T Version 1.01 - s/n: XXXXXXXXXXXXXX BIOS: American Megatrends Inc. Version L2.02. Dated: 03/23/2020 CPU: Intel® Xeon® E-2176G CPU @ 3.70GHz Cache: 384 KiB, 1536 KiB, 12 MB Memory: 32 GiB DDR4 Single-bit ECC (max. installable capacity 128 GiB) Network: eth0: 10000 Mbps, full duplex, mtu 1500 Kernel: Linux 5.19.17-Unraid x86_64 OpenSSL: 1.1.1s 2x TEAMGROUP 512GB NVMe as cache pool 1x parity 3x array drives EDIT: diagnostics attached. tower-diagnostics-20230709-1316.zip
-
This worked for me! Thank you!
-
About to update to 6.10.3 from 6.9.2. One reason for the update is the cache replacement bug that exists in 6.9.2. I've been waiting for any bumps to get ironed out on the new release. I know there's been a change regarding root user and this might affect things. I know some users have had some hiccups with things after update to 6.10.X. I would like to take any preemptive steps to negate issues. I currently have many popular dockers running (PLEX, Jellyfin, Resilio, Nextcloud, Swag and others) and one VM (Home Assistant OS) Nothing too crazy. Hardware is a HP ProLiant MicroServer Gen10. What can I do before updating to reduce any permission issues regarding the root user change? Any other potential issues to look out for?
-
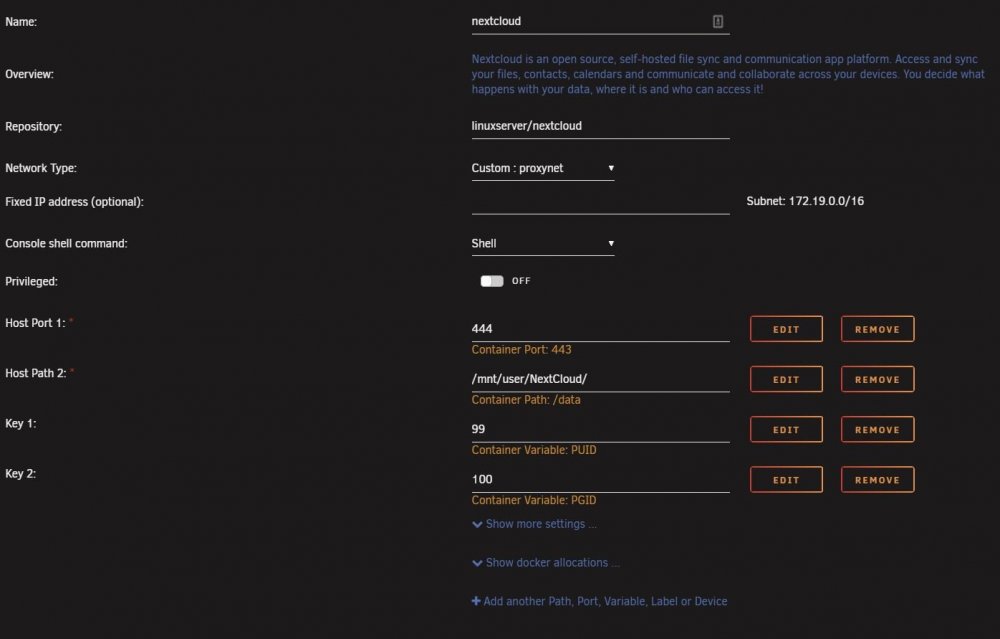
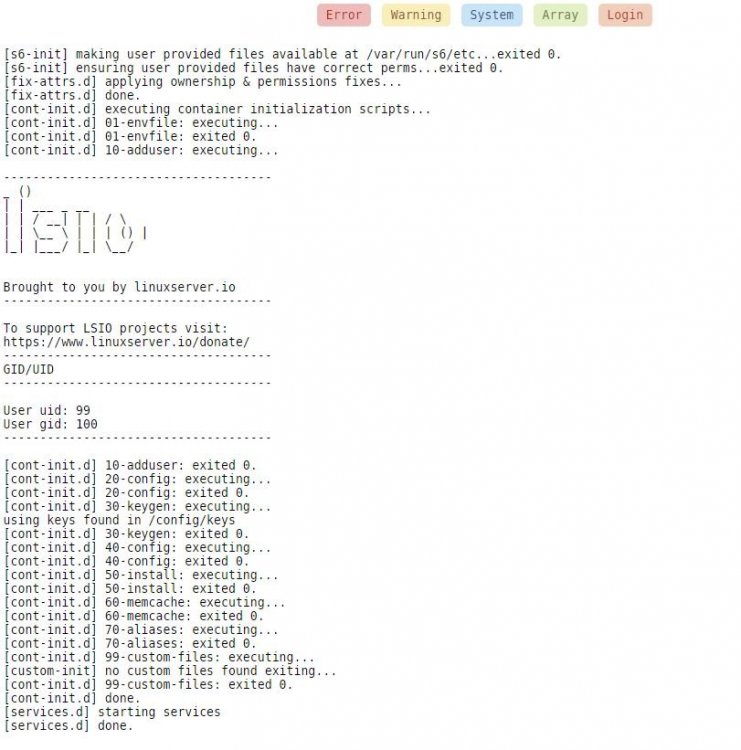
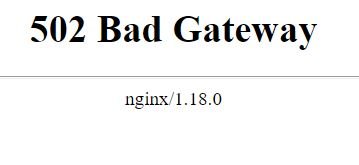
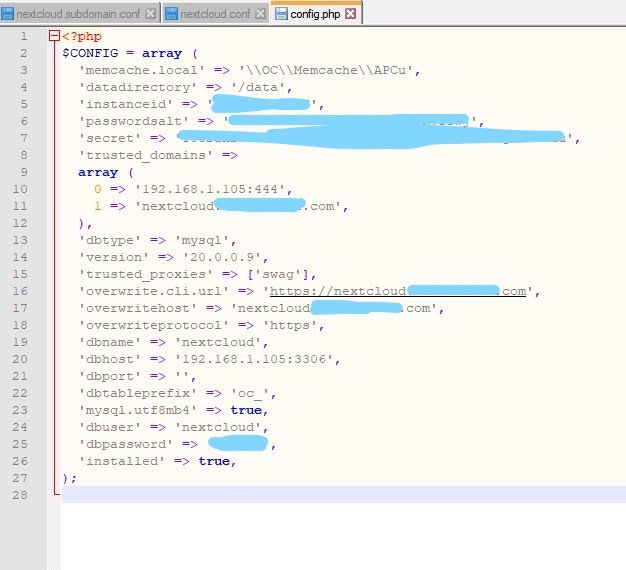
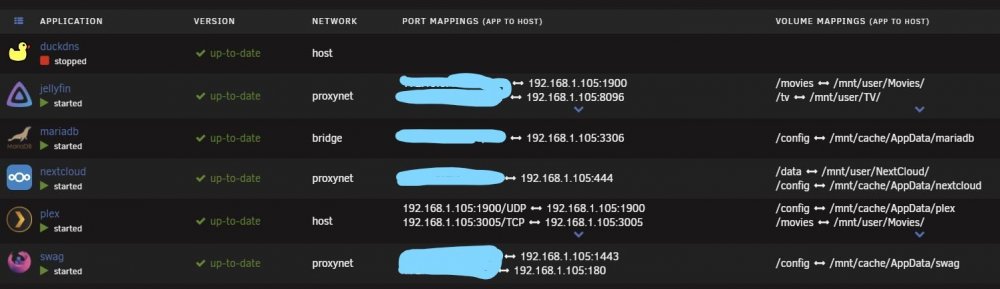
IM GOING INSANE. I had various issues that caused me to have to completely redo all my dockers and cache drive swap. That being said everything is back up and running as expected EXCEPT Nextcloud I can't access Nextcloud locally or remotely. I've gone through countless forums and threads trying to find help but they immediately go into the weeds and dead end or aren't helpful. Unraid v6.8.3 Using subdomains for access. (I had this all working perfectly before the cache swap.) Only difference now is Swag instead of letsencrypt docker) Swag for reverse proxy Ports forwarded properly on the router Mariadb make a database for Nextcloud to use (Jellyfin is using same custom network and I can locally and remotely access it) Right after I set up Nextcloud I was able to access it via local ip and set it up as you should and did some simple configuration. Then I moved on to other dockers. I added Jellyfin and configured it. Now Nextcloud is 100% inaccessible, they don't share any ports. I've edited all the config files as specified by SpaceInvader and various forum posts. Nothing helps. I've rebooted the server countless times during the whole process. Restarted dockers after any change. Locally with IP I get nothing "this site cannot be reached" with subdomain address I get 502 bad gateway ngix 1.18.0 Please be gentle Im not a pro with all this stuff. I followed SpaceInvaderOne tutorials for setting up Nextcloud, Letsencrypt/Swag as I did before and everything worked. Now this time around, it's just not working. (last time was 4 months ago) I don't understand how I did the Jellyfin setup the exact same way and it works but Nextcloud is just broken. I found others saying to just nginx proxy manager docker but no one has information on how to exactly do so. Some people said it's a DNS issue but didn't offer any help or information on how to resolve that. As much love as I have for SpaceInvader I think his video might be outdated or Nextcloud has been altered in someway to make it no longer relevant way to install and access remotely this is clear to me as im not the only one having these types of issues. It's always a headache... One little configuration screws it all up for me every single time I touch my server. tower-diagnostics-20201008-1650.zip

-
Thanks for the help! I've got a line out to Jellyfin about my current issue now. I just hoped someone here might have some insight as well..
-
I posted it to show that I've not modified it. Seems like every time someone needs assistance they need to show their log or config and no one trusts the user till they see it. I just reset the Jellyfin docker to the proxynet. Restarted the whole server and now it's working. Im not sure what's changed. Maybe my DNS for subdomain hadn't finalized. Thanks for letting me know it should be proxynet. I assumed this but was annoyed when it didn't work. Regarding the ping. I always instantly forget console stuff. Would I ping it via "ping local ip:port" ? I did ping of the local ip and it just keeps running. EDIT: I CAN access and login with iOS app, Chrome, Safari, Edge browser using the custom subdomain remotely and locally. The only thing that CAN'T login is the Android app. I can add the server but not login with any user. I can login with local address on same network but not when I try to use the custom domain. pixel 2 (v10 android) Jellyfin app version 1.0.1 Using the custom subdomain It lets me add the server just not login I see an error in the console but I have no idea what it means. (https://imgur.com/a/QY6n2mM) - link to errors
-
Unraid 6.8.3 installed linuxserver jellyfin docker Up and running fine. Added souce folders, metadata complied. Local access is fine. The issue Im having is that I can't access it remotely or with mobile app. Im using LetsEncrypt and DuckDNS with a custom subdomain. I've got the ports forwarded as directed. Letsencrypt states that the certs are fine for the new subdomain and my old one for nextcloud adn that server is ready. Things i've done/tried: I've done as directed by the Jellyfin networking documentation here I've configured the Network settings on Jellyfin webui as directed as well. (local ports left as-is, set external https to 443, secure connection mode "handled by reverse proxy") The container name is "jellyfin" My .conf file is setup as it should be and saved as .conf not .sample. I switched docker network type from "bridge" to "host" both get "502 Bad Gateway" I tried "proxynet" for network type and just get "this site cannot be reached" (this was setup for my nextcloud) I've restarted all dockers. Cleared browser cache and tried another browser and another device as well as ios app My nextcloud is fine and accessible remotely so there's one little thing im missing with the jellyfin configuration. proxy-conf: server { listen 443 ssl; listen [::]:443 ssl; server_name jellyfin.*; include /config/nginx/ssl.conf; client_max_body_size 0; location / { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app jellyfin; set $upstream_port 8096; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; proxy_set_header Range $http_range; proxy_set_header If-Range $http_if_range; } location ~ (/jellyfin)?/socket { include /config/nginx/proxy.conf; resolver 127.0.0.11 valid=30s; set $upstream_app jellyfin; set $upstream_port 8096; set $upstream_proto http; proxy_pass $upstream_proto://$upstream_app:$upstream_port; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $http_connection;
-
Well I don't know what happened I restarted a couple more times but now it works and i've signed into imessage successfully I think the restart with auto DHCP might have been the ticket.🤷♂️ If you mean "make inactive" and reactivate the connection the Network panel of my screenshot, then yes I've tried this and nothing happens. Tried auto and manual DHCP. I've remove the ethernet connection and made a new one. In Terminal when I listall hardwareports I have the following Hardware Port: Ethernet Device : en0 Ethernet Address : (my MAC address) Changing slot value: I assume you mean in the xml?








