




unevent
Members
-
Joined
-
Last visited
Everything posted by unevent
-
Thank you
-
Exploring utilizing a ZFS pool for a Windows Server VM for data. I've seen in the docs how to assign a VM to a physical disk, but is it possible to assign a ZFS pool to a VM vs a virtiual disk (single file)? Say I want the OS to be a RAW virtual disk not on the array, but want the Server VM to have storage to it's own ZFS vdev pool vs. just a single file virtual disk. Possible? If so, can someone provide the details? With multiple ZFS pools being a thing know, being able to have a ZFS pool to each VM would be useful. Thanks
-
Please move post as needed. I have a few questions regarding the phone home/cloud ability of 6.10.x releases. Is the phone home function on by default or you have to install the My Server plugin? Do I need to create unraid.net credentials if I would like to keep my server offline and not be apart of the cloud capabilities? Another way of asking, are the new credential and online/cloud functions and other requirements off by default and need to be turned on if you want to use the features? Thanks
-
Just a thought, can the update plugin ( for upgrade to 6.10.x) do a check for tg3 driver and iommu enabled and if so display a message notifying the user of the potential issue and option to abort the upgrade?
-
Not sure if this falls under a feature request though There is already a system in place on unRAID to handle plugin updates on a schedule or manually. Seems the issue is more the plugin authors or perhaps the unRAID team are not enforcing plugin protocols.
-
Problem is it triggers when I access the GUI, which is the main page. Unraid core does not do this when there is an update unless you click the appropriate controls to do a manual or automatic check on a schedule. I don't see why plugins cannot be the same. The notification settings (under settings) have plugin update check turned off so why not have all plugins honor that setting?
-
That on the radar to add to add at some point? Thanks
-
To bump the post, is there a way to suppress plugin update banners? Thanka
-
Will this be posted somewhere so can fast forward/skip through? Watched the first 30mins before having to leave and didn't really get anything out of that.
-
Not sure if reported yet. When formatting ext4 says 64-bit filesystem support is not enabled: Jan 13 20:32:06 Tower unassigned.devices: Format disk '/dev/nvme0n1' with 'ext4' filesystem result: mke2fs 1.45.0 (6-Mar-2019) 64-bit filesystem support is not enabled. The larger fields afforded by this feature enable full-strength checksumming. Pass -O 64bit to rectify. Discarding device blocks: 4096/250050816#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010#010 629555{.....}done
-
Is 'Direct Unpack' checked under switches?
-
I have /mnt/cache/.apps/calibre_library/ and /mnt/cache/.appdata/nginx/ as the only maps.
-
This is on cache only and no maps to user shares. Can you elaborate on how spin up groups will solve the issue? Thanks
-
------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io We gratefully accept donations at: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 20-config: executing... [cont-init.d] 20-config: exited 0. [cont-init.d] 30-keygen: executing... using keys found in /config/keys [cont-init.d] 30-keygen: exited 0. [cont-init.d] done. [services.d] starting services [services.d] done. Signal handled: Terminated. [cont-finish.d] executing container finish scripts... [cont-finish.d] done. [s6-finish] syncing disks. Signal handled: Terminated. [cont-finish.d] executing container finish scripts... [cont-finish.d] done. [s6-finish] syncing disks.
-
Is there a reason for a sync being issued on container stop? Can it be removed? It spins up the entire array when this container is stopped or updated. Thanks
-
From this post SNMP Config UPSCABLE ether UPSTYPE snmp DEVICE 192.168.1.60:161:APC:private PCnet Config UPSCABLE ether UPSTYPE pcnet DEVICE 192.168.1.60:apc:admin-user-phrase The above is assuming defaults and the 'admin-user-phrase' is what you changed it to from the default (not the user interface login). Once configured do a restart of apcupsd or reboot. If still doesn't work and your UPS is new, try the NUT plugin. APC may have changed their protocol. Suggest starting a new thread.
-
In Sabnzbd adjust the min free space setting under 'config - folders - minimum free space for temporary downloads folder'. Probably set at least double what you expect the largest single download to be. Another option is to put in a disk using unassigned devices to only use for download processing.
-
In my opinion, for your current build a 550 would be sweet spot. For your future build, if going with say i7-8700 and 1070ti and what you listed then your choice of 750 seems reasonable. Solid choice on the FSP. Adjust accordingly for what you expect to have for future CPU and GPU as those can vary the requirements the most.
-
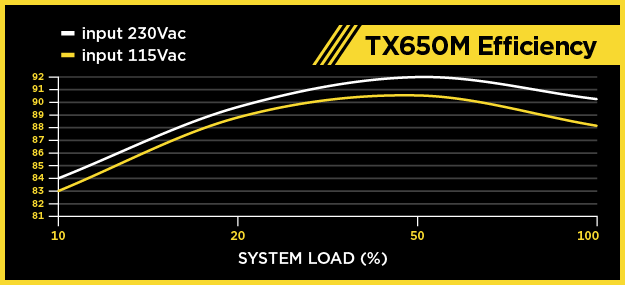
For a constant load, yes, I would agree with that. unRAID is a different animal in that the load is usually not very constant for most. Depending on your power saving schemes such as CPU throttling, drives spin down timers, usage, etc. the load seen by the supply for your configuration could be less than 60W all the way up to 175W or more. Best thing to do is monitor/measure wattage under normal usage such as power up, idle, heavy load, etc. to figure out min and max. With that data focus on trying to size to stay near 20% minimum supply loading and also do not exceed single rail wattage with a reasonable buffer when all your drives being spin up with processor at full load (e.g. prime 95 and manual spin-up). The supply you have listed is more than enough for your application with plenty of room to spare for hardware upgrade. At idle your very close to the 10% loading which puts the efficiency at around 83% based on the graphic below. I would guess your normal loading would be in the low 20% range which puts the efficiency at 88-89%, assuming 115V. Not sure on the Seasonic marketing. Prime is their high end and Focus is on the low end, but even their low end is well above a lot of other brands. Review sites like Toms Hardware and Anandtech have reviews of their supplies where they may explain the marketing.
-
Is there a trick to get the DVR commercial skip that is in Plex Pass work? I have it enabled under DVR settings, but I still get commercials.
-
-
Yeah, 450W would just be enough, 550W gives you some room and moves the draw back more into the peak of the efficiency curve. 650W would be less efficient than the 550W for this app, but is an option if you plan to upgrade and draw more in the future - like 125W CPU and five or so more spinner drives.
-
The Seasonic 550W would be my suggestion. Gold would be a more cost effective solution since your only looking at a few $ electricity cost difference per year and paying more for Titanium. Newegg has the Focus 550W (Gold) for $54.99 after rebate vs. $71 for the 550W Focus Plus. Both are excellent choices.
-
I don't disagree there, it is just a platform as I said. Take a step back - the enabling apps and the platform itself are on the same forum and integral to the official LimeTech user forum. Just an opinion based on the obvious given this thread's title, no need to start a holy war.
-
Not to put on the tin foil hat or anything, but a lot of unRAID is closed source and is obviously a platform to enable pirating of a multitude of things given the majority of the Dockers made available and advertised on this forum. Wouldn't be far fetched to think LT has or will be contacted at some point to embed code and the users not know about it. Just saying

