NLS
Members
-
Joined
-
Last visited
-
I can probably go in the shell, as locally the gui doesn't work, but the limited desktop of UNRAID does work, so I can invoke the shell. I need that gui reset command if there is one. If there isn't maybe it should finally be implemented. Also if I fail to reset gui and need to reboot, the logs will be nuked and the issue will not be identified. (assuming gui DOES work after reboot) Which is why also the diagnostic script should be able to run in command line. (anybody?)
-
So I got an email from my server that my plugins/containers would auto-update last night, something that has happened many many many times before - although I usually update things manually before my schedule. In any case I discover now that my GUI is dead (even in own desktop, if I select to see "unraid web interface" I get "unable to connect"). Everything else is working, containers, vms etc. - but I cannot manage the server. So... 1) Is there a way to reset the gui from command line? (btw this should be a ready-made command or script to handle that) 2) If my GUI cannot be (fully) reset, is there a way to safely shutdown (and restart) the server? (I mean I know how to reboot a linux machine - but I wonder if there are any other steps for unraid specifically) Latest UNRAID 7.3.1, (usually) updated plugins/containers, boot/licensing migrated to SSD/mobo.
-
...yeah happened to me again. Seems with every update we need to manually delete that file (can that not be done with some startup script or smth?)... And as I said I remember this years back happening again.
-
Seems you never replied to my mail 2 years ago (!) although you periodically visit the forums... but today I write again because fetchmail stopped working and in the logs I keep seeing: fetchmail: SMTP error: 452 4.3.1 Insufficient system storage ...I have no space issues for my docker folder (it is a folder not a file). What could be the issue?
-
OK this keeps going periodically. Since yesterday for example, I am at dashboard page (I have visited docker page, but have returned from it). I close my Edge, re-open it and I am back to docker page, NOT the dashboard page (that was the last page before I closed Edge). Note that if I see the URL bar, I briefly see /dashboard (before anything renders in the content window) and it changes to /docker! So it doesn't look like something coming from Edge, as Edge is attempting to open the real last page I left there. Something triggers the change. I attach my diags although I don't think they will help in this case. The easiest way I "fix" this is to middle-click dashboard link, so it opens an new tab, close the first tab, so indeed after I restart Edge, it remembers that. But this is a work-around, not a fix. Note that this is the only page this happens and I have several pinned (and unpinned) pages, all the time, kept between reboots - again: without this issue. diagnostics-20260515-1242.zip
-
Confirm too. The "problem" is that it happened twice in two days. (no gui, delete file, fixed, no gui next day, delete file, fixed) I hope the forgotten lockfile eventually IS deleted when updating the container. BTW, I remember the same issue a few years ago (!) in same container.
-
I use this for years. Today although the container "works" (?), I don't have any gui! Any ideas?
-
I found the reason. For some reason "open files 2" and "open files" were mixing somehow - some internal name or repository conflict? I removed "open files" (although it showed as 2 was installed), and re installed from apps and this worked.
-
Now ALSO "open files v2" doesn't show update status. Is the project dead or what?
-
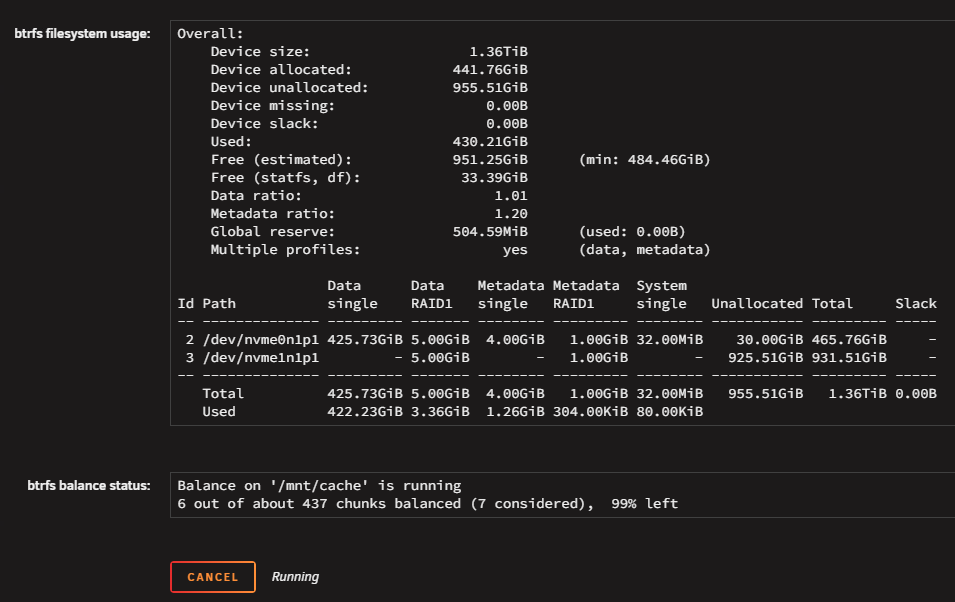
And yes there is another update: Now it shows properly as 1TB the cache and DOES show that it is balancing. It just needed a few minutes to "catch up" with the changes?
-
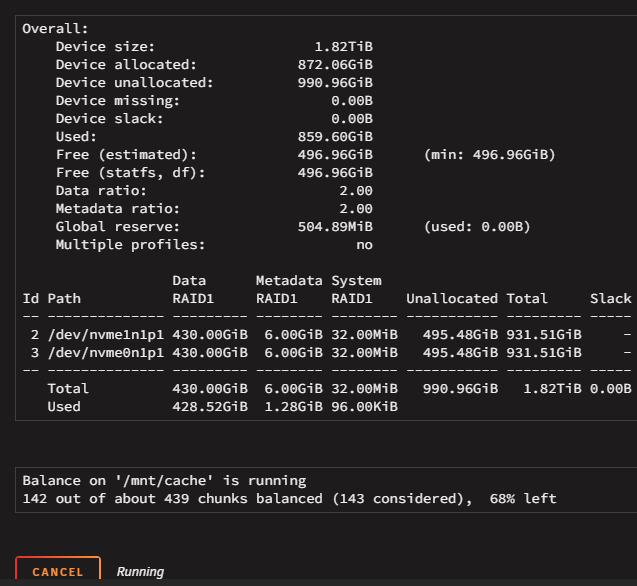
One more screenshot, while it rebuilds... ...it shows the 500GB as missing, It doesn't show here that balancing IS taking place. I am waiting to see what will happen after it finishes the balancing.
-
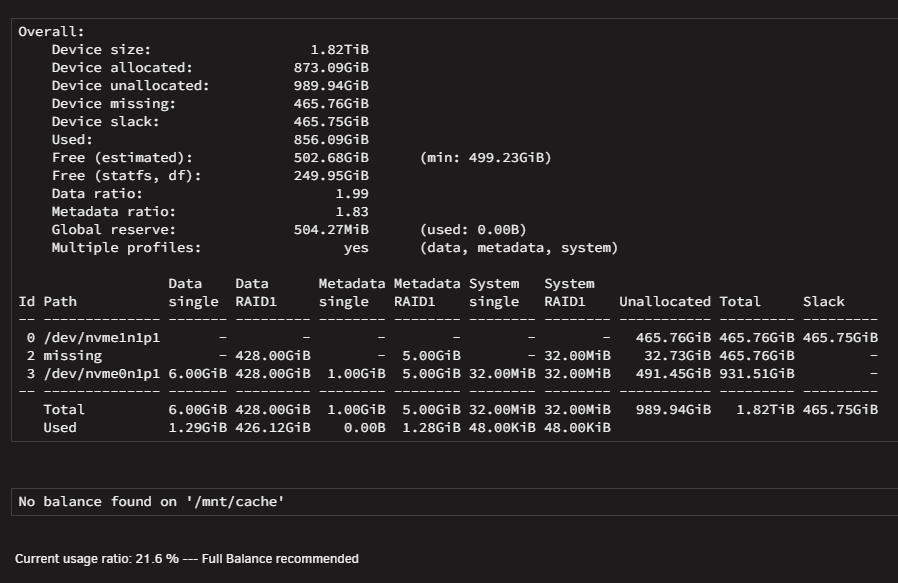
Final (?) update. After rebooting (with new second 1TB) and assigning the new disk, it started rebuilding the raid1 as it seems (see screen shots). Remember this DID NOT happen when I did the first switch (and why I started this thread). So I think we are good now, except one thing: For some reason when I had 500GB with data and 1TB empty but system confused, it showed me a total of 750GB size??? Now that I am with 2 x 1TB cache, rebuilding the second 1TB, it still shows 750GB... Not 500GB, not 1TB. I want to believe that after the syncing, it will raise to 1TB. after-reboot.zip
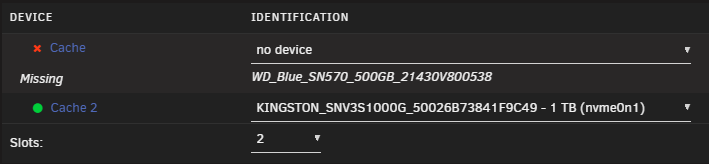



-
It finished, I think it looks ok and I see writes at the same time to both disks. I attach new diagnostics for the sole purpose of keeping log in case something goes wrong with second swap.spezierixl-diagnostics-20260502-1609.zip
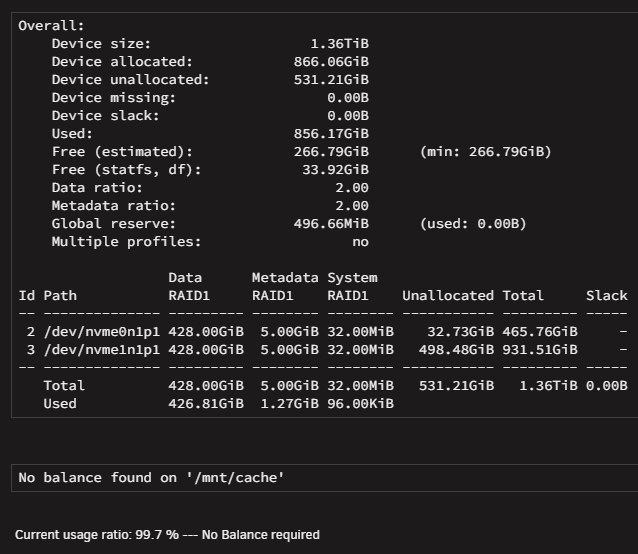
-
...btw why ID is 2 and 3? Is this correct? It finishes in 20-30 min. If you can quickly like above give me the correct process to then swap the 500GB with the second 1TB, it would be great. (worst case scenario, I will follow official docs, in other words, stop, remove disk, add disk, start, without any bringing online of array in the middle steps - unlike when replacing array disk) (and if it does again the same problem with the second disk, I will do the same recovery steps that you say above, using the first 1TB as the "mother")
-
I did and it seems to go ok. This time it doesn't show anything missing and DOES write things to 1TB disk while the contents are actually active (VMs are running and containers). This will probably take around 1-1:30 h. Can you follow up (regardless of instructions in documentation) and tell me exactly how to properly remove the (remaining, active) 500G and replace it with the (second, empty) 1TB and re-sync the raid1? Thank you. ...attached progress.