




DrBobke
Members
-
Joined
-
Last visited
-
Thanks a lot for your comment and apologies for the late reply. I have been looking in my nextcloud and under appdata, but I can't seem to find the nextcloud.subdomain.conf file. Is this under appdata --> Nextcloud --> ?? Looking forward to your reply and hoping to solve this issue. 🙂 Best regards, Robert Smits
-
Nobody?
-
Hi everyone, I have been running an own Nextcloud instance for over a year, protected by a reverse proxy SWAG, setup like SpaceInvader one's channel. Everything has been working great (except for last week, when I also had an issue with SWAG, which luckily was sorted thanks to this forum above here!). However, I am sharing a lot of photos and personal videos with family and friends and I often get the feedback that they can't download things from my Nextcloud, which is larger in size (it appears that anything below around 2Gb is fine, but above it times out). I did read some comments on the forum, that it would be SWAG which is the bottleneck, but there doesn't seem to be a solution. So I am using Nextcloud, MariaDB, DuckDNS and Swag. So not sure where the issue lies, but I want to solve this quickly. Anyone else that has this issue and maybe some kind of explanation why this is happening/how to solve it? Thanks in advance, best regards, DrBobke
-
Hi Kilrah, that is awesome, thanks for that! However, it seems that with SWAG, I am getting the time-out errors for folders/files which are bigger than +-2Gb. I read somewhere people reporting it to be swag which is the factor for timing out, I am trying/wanting to get rid of that error, that is why I am looking to fix Nginx or something else. Unless there is a setting in SWAG somewhere I can change to not have the error anymore... 🙂 Thank you for replying!
-
Yeah, I don't think it is that straightforward. Port forwarding etc is easy, but my swag is created with the duckdns which I created, again, easy, so is the setup of nginx I think, but I am struggling with setting up the cloudflare bit. I created an account, but I don't have a website to use for this, nor can I find the DNS settings. The Cname I can't setup via duckdns (or at least, I haven't found that). I even tried making an account with freedns.afraid.org, but that didn't really work either. I obviously have an "nextcloud.duckdns.org" site, but I assume that is not what I have to input there? Also, do I then just stop the SWAG docker container and run the nginx, or is there something more to it?
-
Hi everyone, I have been running an own Nextcloud instance for over a year, protected by a reverse proxy SWAG, setup like SpaceInvader one's channel. Everything has been working great (except for last week, when I also had an issue with SWAG, whihc luckily was sorted thanks to this forum). However, I am sharing a lot of photos and personal videos with family and friends and I often get the feedback that they can't download things from my Nextcloud, which is larger in size (it appears that anything below around 2Gb is fine, but above it times out). I did read some comments on the forum, that it would be SWAG which is the bottleneck, but there doesn't seem to be a solution. So I am using Nextcloud, MariaDB, DuckDNS and Swag. I was just trying to install Nginx to see if this would work, using Ibracorps' video, but when he goes into cloudflare and dns custom domains etc, I am lost. I don't have a setup that intrecate, nor am I able to configure the things he is doing. This has already cost me well over 3 hours to try and figure out, but thought it would be better to ask help here. Since I can't seem to find an alternative explanation from spaceinvaderone on using nginx, or moving over things from swag to nginx and I am not too familiar with unraid, I don't want to screw anything up (I have a lot of folders and files on my cloud). But I do want to try and sort the timeout issues that family and friends are encountering. Anything I can try to sort it out? Thanks in advance, best regards, DrBobke
-
Thanks a lot for posting it here! I did as you suggested, but that didn't work. I then read the thread about the broken reverse proxy and changed the SSL too, which worked like a charm! Thanks a lot! Nextcloud is up and running again!! THANK YOU THANK YOU THANK YOU!!!
-
YEEESSSSS!!!! Thank you soooooo much! Finally have my nextcloud back! Thaaaaannnkkkkk yoouuuuuu!
-
Anyone that can chime in on this? Would like to get it sorted as soon as possible...
-
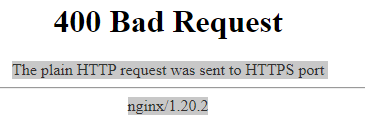
Euhm okay? How do you suggest I do that? Or is there a guide somewhere I can follow? To be honest, if I need to rebuild everything from scratch with all files, shares and people involved, I'll probably ditch the whole unraid server... Is there a way how I can do that? Through support of the docker? As Spaceinvader One is using Linux server repository, I did the same to keep everything the same and not to get errors... Too bad that the official one does everything automagically... Damn, that is bad, is there a way to change that somehow, but still retain all files and stuff I have/had on Nextcloud? I did have some issues with up- and download of files of around 2GB and larger, but I think that is due to swag. I was thinking about switching over to Nginx, but luckily I didn't, as I would "know" that is what was causing the error... If there is any way you could provide some steps I can do to bring my nextcloud back to the living, that would be awesome. Thanks again for your help. Just forgot to add - when I try to locally go into my Nextcloud "unraidIP:444", I get Not sure why I am getting this error, nor why it is nginx, as I am using swag?
-
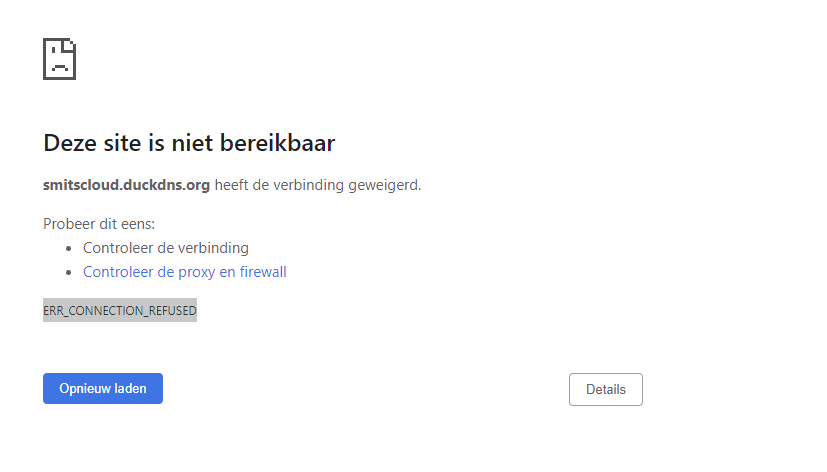
I should have backup on all stuff up and running, but can't seem to find the one with docker info... I do have appdatabackup, flashdrivebackup and libvirt backup. Is it somewhere in there perhaps? Well, if it states that I need to do an update, then I usually do, as it seems it is trying to tell me something? Since it was installed, but I couldn't see it in the log, and I noticed a section that I could force the update, then yes, I forced the update. If it doesn't work like it should and it is telling me to do so, I thought it would be a good idea, yes! If that isn't good, then maybe the creator shouldn't put those kinds of messages in? I did not do a manual backup of that no (I hadn't even thought about it, I was just trying to fix no one getting on Nextcloud). Well, strange that I get a message that I need to update. Moreover, I have always kept all my dockers up to date, only to find out a couple of months ago that I then also had to update nextcloud from in my settings in nextcloud itself. I wrongfully assumed that everything would be updated. So I went from version 21. something I think, to 25.something. It is all very confusing for users that have a pretty strong computer background, but defenitly not an expert in this kind of stuff... When I go on my personal Nextcloud (https://smitscloud.duckdns.org/), I get the ERR_CONNECTION_REFUSED Inside the MariaDB, there is no logs about login tries, nor for the faulty login tries I did before I figured out which password I had used for that... I don't have the Adminer-thing, I setup everything using Spaceinvader one's youtube tutorial. My networks were working fine for years, sharing with a lot of people different kind of files, but mostly photo and video files... Webpage : MariaDB Log MariaDB settings: Nextcloud Log: Nextcloud Settings: duckdns Log : Duckdns settings : And then I have swag too, but not sure if that is neccessary to share here? Swag log seems interesting though? Please let me know if I need to delete any 'sensitive' information in case this could be used to gain access by others...? If you need any other screenshots, please let me know! Thank you in advance for your help, it is very much appreciated! DrBobke
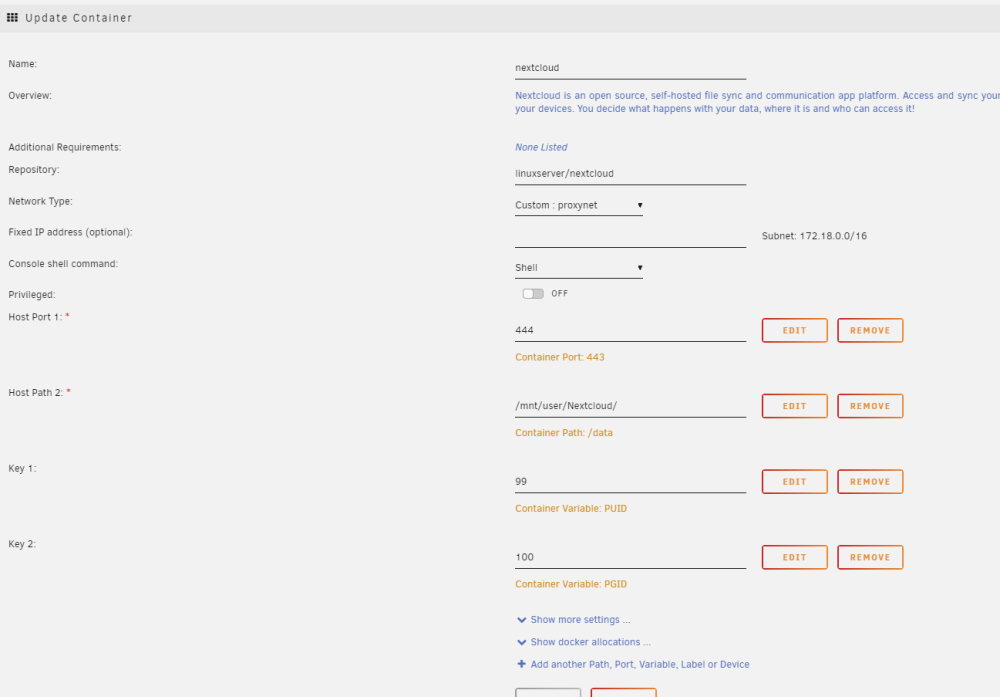
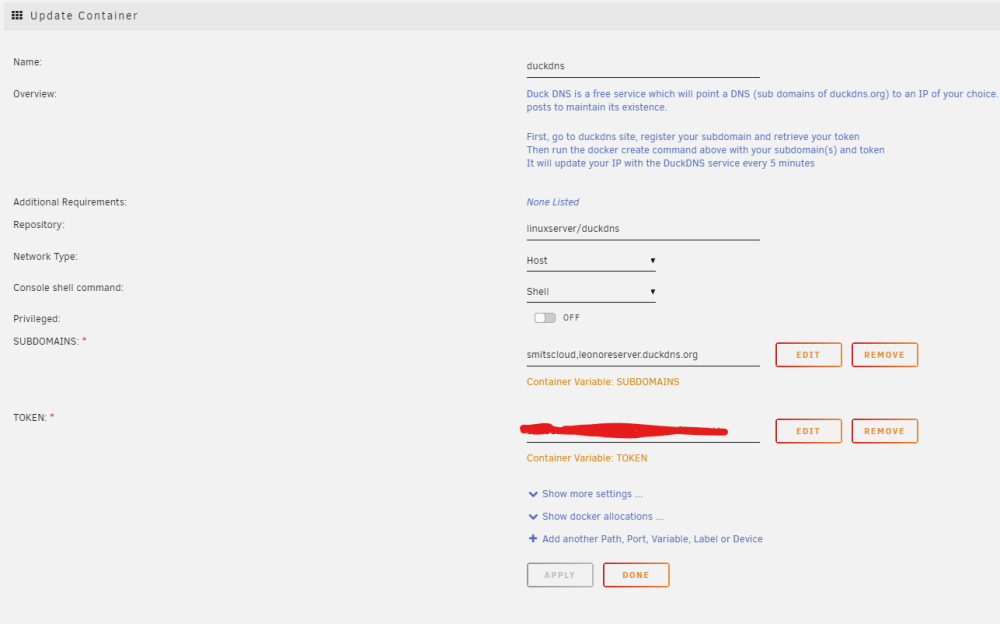
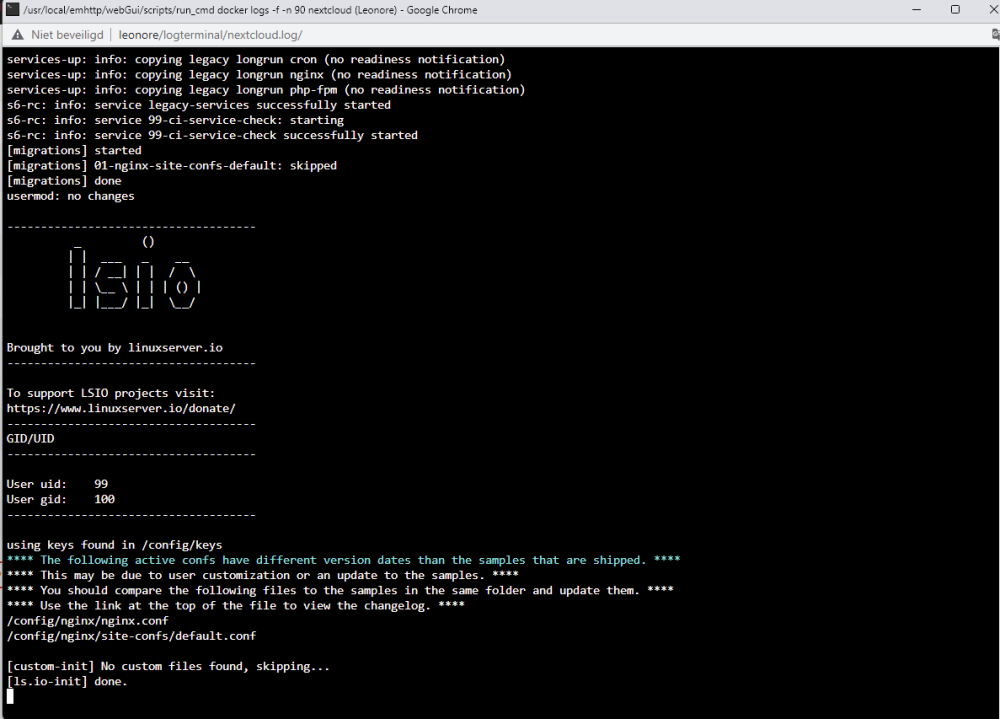
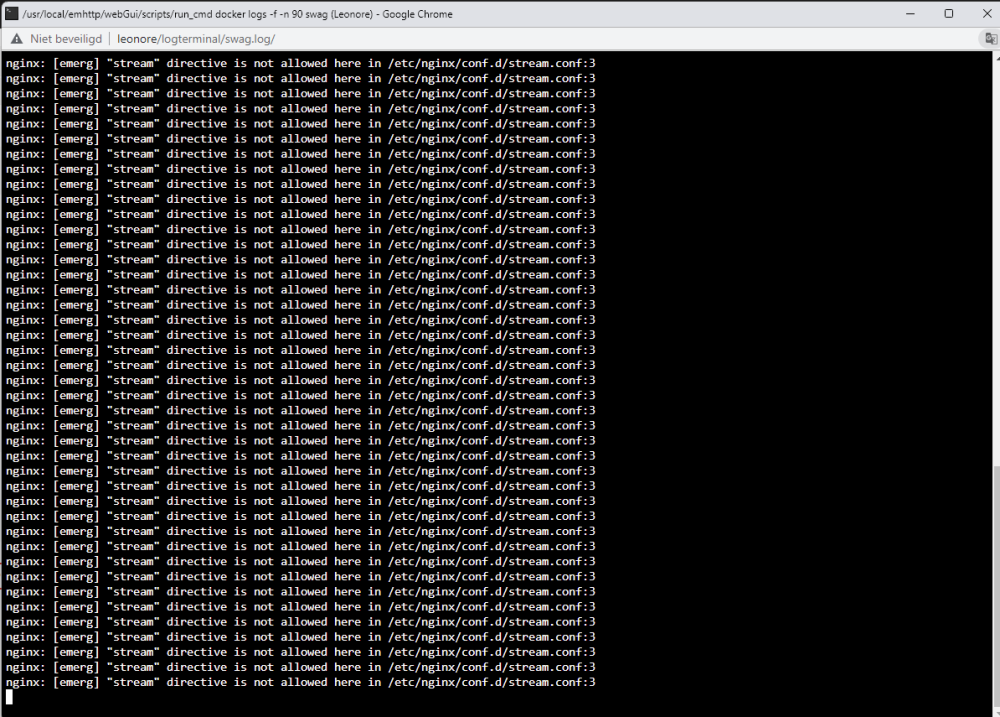
-
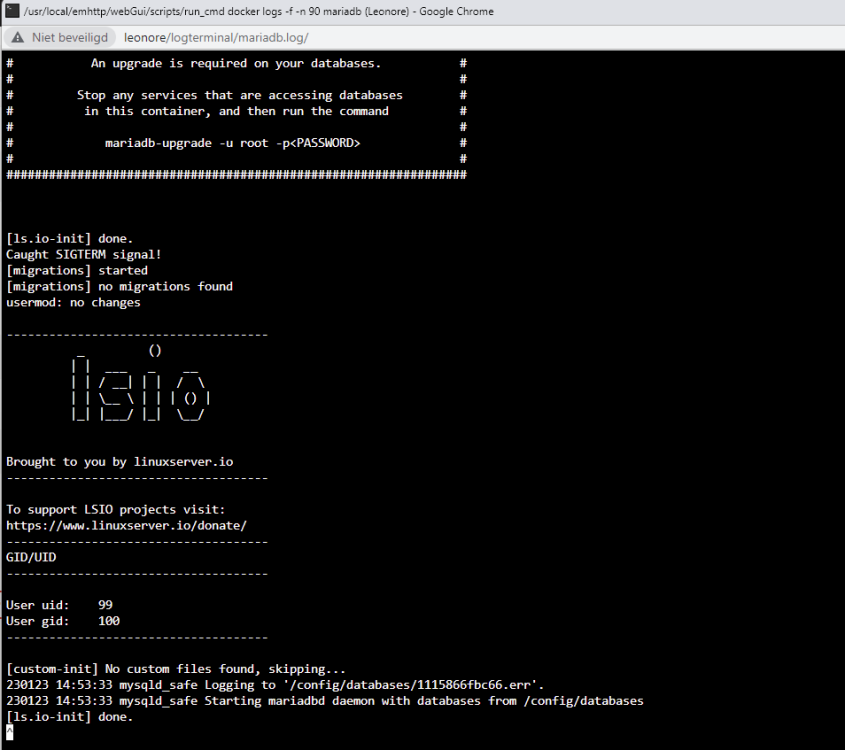
Hi guys, I have been using Mariadb for two years for my nextcloud. Everything has been working fine and stable all that time since setup. I know Nextcloud was updated (or was at least over a week ago when I last checked). However, I have just noticed today, that all of the sudden, my Nextcloud stopped working. Except for updating the various dockers, I haven't done anything to my unraid. My setup is mariadb with duckdns and nextcloud which is rooted through a reverse proxy swag. I do think I am having some issues with swag when people want to upload/download files over 2Gb in size. When I was troubleshooting this, I went into the logs of mariadb and found a notice "An upgrade is required on your databases. Stop any services that are accessing databases # # in this container, and then run the command # # # # mariadb-upgrade -u root -p<PASSWORD> So I stopped the services listed above and went into the console and typed the command, logged in with my password and I saw that it was working. But I am still getting the same error in the logs, that I have to upgrade (docker is up-to-date for all dockers I am using). In the console, I get the following message : This installation of MariaDB is already upgraded to 10.6.10-MariaDB. There is no need to run mysql_upgrade again for 10.6.10-MariaDB. You can use --force if you still want to run mysql_upgrade So I went in again and used --force at the end, but that doesn't lead me further and I keep getting the same log error that I have to upgrade. Not sure if it has anything to do with Nextcloud not working, but it's somewhere to start at least. The error I am getting is "ERR_CONNECTION_REFUSED" Any help will be greatly appreciated for sure as this is a bit of a nightmare. I really don't want to loose the Nextcloud that I have painstakingly built up over the years.
-
In the meantime, I have bought an Nvidia Shield Tv Pro, which seems to do the job. Only at the very end of a 4k movie (@77.9Mbps), the buffering issues began. Still not sure why I am having these issues, but happy it is not on every movie right now (although I haven't had much time to test lately).
-
Anyone to chime in on this please?
-
Thanks, but the exact command obviously didn't work... Thanks to Selmak's comment, it did... I will have to check out Nginx then, instead of swag. Is there any good reference you can point me to in making the change please? Yes, you are absolutely right, it used to be letsencrypt! I just followed the video from SpaceInvader One to get it set up...








