




jeffrey.el
Members
-
Joined
-
Last visited
-
In this case the target is a different physical machine in a different vlan.
-
NPM is on network; Custom: br0.50 if that is what you mean?
-
NPM is 10.0.50.10, the target containers have different IP's from different subnets, but inter vlan routing is enabled for those subnets. I've never had any issues with targets or anything, it always worked, the only issue I'm having is the bind error issue and the IP 10.0.50.10 is not used by anything else, so there is no IP conflict or anything..
-
No, they are listening to those ports as well; But like I said everything has worked fine for months, and now all of a sudden this happens.. Is there anything that might cause the bind issues? Is there maybe a limit on the amount of proxy hosts that NPM can handle?
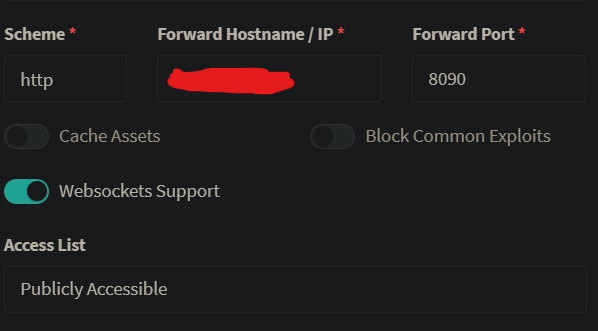
-
I understand your confusion, certificate renewal is done through port 80, and indeed NPM listens to ports 80, 81 and 443. I however have an instance running in my network which listens to port 8090 and 8091, so to make NPM redirect these hosts with the certificate it requested and manages, I had to add those ports to the container and in the Advanced configuration section I added; listen 8090 ssl; listen 8091 ssl; But like I said for this to work, NPM has to be able to listen to those ports as well, so in Unraid I added them to the container; And those ports are port forwarded to the NPM container as well, so all should be good on that part!
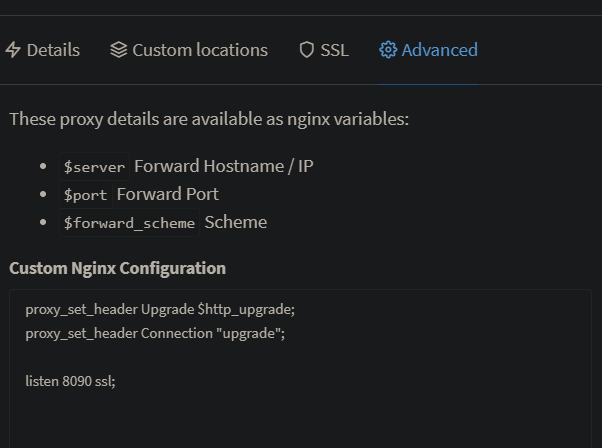

-
Yes I added the ports to the container config as well, because the incoming connections are on these ports as well, this way I can use NPM to take care of the certificate renewals.
-
Yes I added those ports myself for specifc proxy hosts, but that's exactly why I'm so confused. All ports are failing all of a sudden. I have a few specific instances running which use a certificate for a API access, which listens on different ports.
-
Well I hope it solves the issue for you, as for me, I'm not using any post Arguments.. I'm getting the error on all ports which I'm using in different proxy entries; But the output of the command you send is the following; tcp LISTEN 0 4096 0.0.0.0:9443 0.0.0.0:* users:(("docker-proxy",pid=31783,fd=4)) tcp LISTEN 0 4096 [::]:9443 [::]:* users:(("docker-proxy",pid=31790,fd=4))
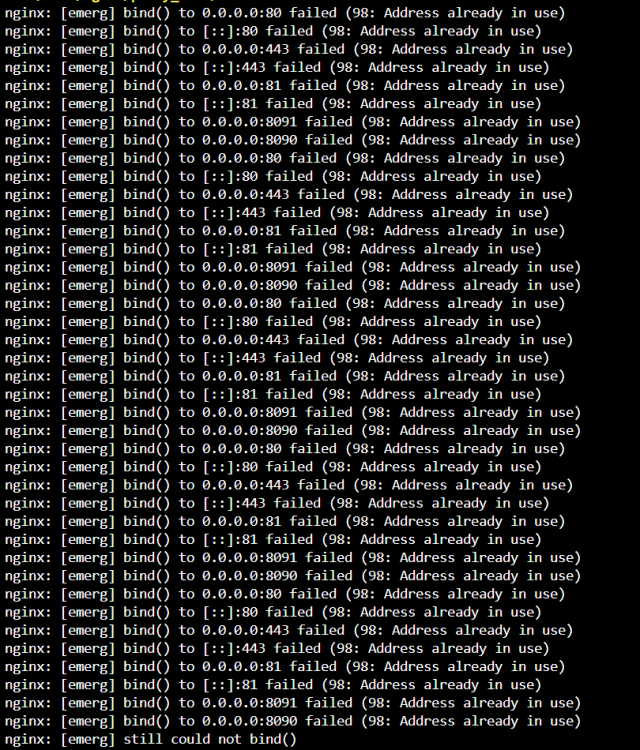
-
I came here looking for a solution to this as well, me and a friend of mine both use this container and both have this issue. Everything ran fine for months and just a few days ago when I tried to edit an proxy entry, I got an internal error in the web interface and this issue started to show up. A restart of the container indeed fixes the issue temporarily, but it's not a solid fix. I've already been looking into this when that friend of mine first started having this issue, I checked everything.. We both have an unique IP configured for the container, no double ports or anything. I checked everything I could possible think of what might cause this, but since this issue started showing up out of nowhere without me making any changes network wise to the Unraid host or to the docker container itself it kind of confuses me.. The container itself sometimes runs fine with the error happening, sometimes it stops working, but as soon as you try to make a change in the web gui it ceases to function.. Where you able to find anything which might point to a possible cause?
-
Hi! I just updated Unraid and switched to this version of docker folders. Everything works great so I'm really grateful for the continuation of this plugin! Thank you for that! However I do have an issue... I can't expand the VM folders.. I tried removing the file so a new one would be generated but it still doesn't work I do see an error in the web console.. Any idea how I can fix this?
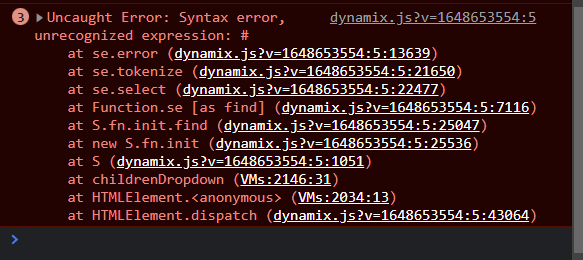
-
Nah it's alright At least I now know they are actually spun down. I just also noticed that when I stop the array all disk LED Indicators turn off except those, so it's probably nothing.
-
Yes the other devices are all SATA. As a case I'm using an Inter-Tech 4U 4424: https://www.inter-tech.de/en/products/ipc/storage-cases/4u-4424 It has a built in SAS backplane.
-
:~# sdparm -C sense /dev/sdr /dev/sdr: WD WDC WD3001FYYG-0 VR02 Additional sense: Standby condition activated by command :~# smartctl -n standby /dev/sdr SAS Assist Plugin: /dev/sdr is in standby mode (spun down), smartctl exits(2) So they are spun down if I understand correctly? Is it then normal for the disk activity LED's to stay lit continuously? For all the other disks they turn off, that was why I was so confused...
-
Hi I'm hoping maybe someone can help me out or maybe explain why I can't seem to get my SAS drives to spin down.. I currently have 3 SAS drives in my Unraid server, all the same model; WDC WD3001FYYG-0 Whenever a disk is idle or when I manually spin down one of these disks, I see a message in the log "SAS Assist v2022.05.25: Spinning down device" So it seems the plugin is working! However, the activity led on the disks remain lit which would indicate that the disks are still spun up.. Is there anyone who might have an idea what is causing this?
-
Hello! I just tried to pre-clear a drive, but it's stuck at starting for hours... does anyone have any idea what might cause this? I've cleared multiple drives in the past with this plugin, all successful.





