




ramair02
Members
-
Joined
-
Last visited
Everything posted by ramair02
-
Thanks, Jorge. I do have syslog server enabled. Attaching here.syslog-10.0.0.25.log I believe I'm on the latest BIOS, but I will double check.
-
homegrown-diagnostics-20251022-0446.zip Attaching diagnostics. The server is often freezing up overnight requiring a hard reboot. It seems to be happening during or after appdata backup. Not sure if this is caused by a container or if I may have bad memory. I upgraded the server hardware a couple of months ago.
-
Cables are seated properly, but I just ordered another set of cabledeconn mini sas breakout cables to see if that's the issue. I read in another thread that there are some problem firmwares for the LSi HBA cards. How can I check the firmware and does anyone know which firmware versions have issues? I also use an HP SAS expander along with the LSi card. It's odd since the issue happened initially after months of being stable. Then I replaced the SSDs and things have been stable for more than a month -- until now.
-
I am having an issue with my server. My zpool which is dedicated to running containers (has appdata & system shares) is throwing UDMA CRC error counts. I had this issue a little over a month ago and it corrupted two SSDs. I chalked it up to bad drives, so I replaced them. Now, the server has been up for a month and the issues is happening again. In the syslog, I constantly see: Dec 14 17:46:10 homegrown kernel: mpt2sas_cm0: log_info(0x31120303): originator(PL), code(0x12), sub_code(0x0303) Dec 14 17:46:10 homegrown kernel: mpt2sas_cm0: log_info(0x31120303): originator(PL), code(0x12), sub_code(0x0303) Dec 14 17:46:10 homegrown kernel: mpt2sas_cm0: log_info(0x31120303): originator(PL), code(0x12), sub_code(0x0303) Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#716 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=2s Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#716 CDB: opcode=0x2a 2a 00 02 77 04 f0 00 01 00 00 Dec 14 17:46:10 homegrown kernel: I/O error, dev sdd, sector 41354480 op 0x1:(WRITE) flags 0x700 phys_seg 32 prio class 2 Dec 14 17:46:10 homegrown kernel: mpt2sas_cm0: log_info(0x31120303): originator(PL), code(0x12), sub_code(0x0303) Dec 14 17:46:10 homegrown kernel: zio pool=cache-docker vdev=/dev/sdd1 error=5 type=2 offset=21172445184 size=131072 flags=180880 Dec 14 17:46:10 homegrown kernel: mpt2sas_cm0: log_info(0x31120303): originator(PL), code(0x12), sub_code(0x0303) Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#715 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=2s Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#715 CDB: opcode=0x2a 2a 00 02 77 03 f0 00 01 00 00 Dec 14 17:46:10 homegrown kernel: I/O error, dev sdd, sector 41354224 op 0x1:(WRITE) flags 0x700 phys_seg 32 prio class 2 Dec 14 17:46:10 homegrown kernel: zio pool=cache-docker vdev=/dev/sdd1 error=5 type=2 offset=21172314112 size=131072 flags=180880 Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#714 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=2s Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#714 CDB: opcode=0x2a 2a 00 02 77 02 f0 00 01 00 00 Dec 14 17:46:10 homegrown kernel: I/O error, dev sdd, sector 41353968 op 0x1:(WRITE) flags 0x700 phys_seg 32 prio class 2 Dec 14 17:46:10 homegrown kernel: zio pool=cache-docker vdev=/dev/sdd1 error=5 type=2 offset=21172183040 size=131072 flags=180880 Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#713 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=2s Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#713 CDB: opcode=0x2a 2a 00 02 77 01 f0 00 01 00 00 Dec 14 17:46:10 homegrown kernel: I/O error, dev sdd, sector 41353712 op 0x1:(WRITE) flags 0x700 phys_seg 32 prio class 2 Dec 14 17:46:10 homegrown kernel: zio pool=cache-docker vdev=/dev/sdd1 error=5 type=2 offset=21172051968 size=131072 flags=180880 Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#712 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=2s Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#712 CDB: opcode=0x2a 2a 00 02 77 00 f0 00 01 00 00 Dec 14 17:46:10 homegrown kernel: I/O error, dev sdd, sector 41353456 op 0x1:(WRITE) flags 0x700 phys_seg 32 prio class 2 Dec 14 17:46:10 homegrown kernel: zio pool=cache-docker vdev=/dev/sdd1 error=5 type=2 offset=21171920896 size=131072 flags=180880 Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#711 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=3s Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#711 CDB: opcode=0x2a 2a 00 02 76 f6 f0 00 01 00 00 Dec 14 17:46:10 homegrown kernel: I/O error, dev sdd, sector 41350896 op 0x1:(WRITE) flags 0x700 phys_seg 32 prio class 2 Dec 14 17:46:10 homegrown kernel: zio pool=cache-docker vdev=/dev/sdd1 error=5 type=2 offset=21170610176 size=131072 flags=180880 Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#709 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=3s Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#709 CDB: opcode=0x2a 2a 00 02 76 ff f0 00 01 00 00 Dec 14 17:46:10 homegrown kernel: I/O error, dev sdd, sector 41353200 op 0x1:(WRITE) flags 0x700 phys_seg 32 prio class 2 Dec 14 17:46:10 homegrown kernel: zio pool=cache-docker vdev=/dev/sdd1 error=5 type=2 offset=21171789824 size=131072 flags=180880 Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#708 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=3s Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#708 CDB: opcode=0x2a 2a 00 02 76 fe f0 00 01 00 00 Dec 14 17:46:10 homegrown kernel: I/O error, dev sdd, sector 41352944 op 0x1:(WRITE) flags 0x700 phys_seg 32 prio class 2 Dec 14 17:46:10 homegrown kernel: zio pool=cache-docker vdev=/dev/sdd1 error=5 type=2 offset=21171658752 size=131072 flags=180880 Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#707 UNKNOWN(0x2003) Result: hostbyte=0x0b driverbyte=DRIVER_OK cmd_age=3s Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: [sdd] tag#707 CDB: opcode=0x2a 2a 00 02 76 fd f0 00 01 00 00 Dec 14 17:46:10 homegrown kernel: I/O error, dev sdd, sector 41352688 op 0x1:(WRITE) flags 0x700 phys_seg 32 prio class 2 Dec 14 17:46:10 homegrown kernel: zio pool=cache-docker vdev=/dev/sdd1 error=5 type=2 offset=21171527680 size=131072 flags=180880 Dec 14 17:46:10 homegrown kernel: sd 2:0:1:0: Power-on or device reset occurred I did some research on the forums and think the issue is either HBA / SAS expander firmware, cables or perhaps too many drives on a power supply leg. Can someone help me diagnose? Thank you! homegrown-diagnostics-20241214-1741.zip
-
You're having the same issue as me. I'm assuming it is a bug that a future update of FCP or UD will fix? For now, I'm just ignoring the error until I hear from folks here that know more
-
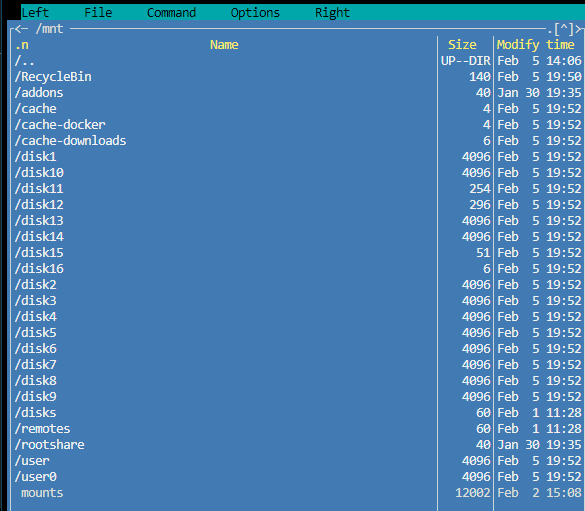
This makes sense. How can I figure out what is creating the 'mounts' file? It contains a bunch of mountpoint information about all of my disks. Here's a snippet of the file contents. Entire file attached. mounts.txt

-
Receiving the following error: Fix Common Problems - homegrown: 03-02-2024 04:40 AM Errors have been found with your server (homegrown). Investigate at Settings / User Utilities / Fix Common Problems FCP states: File mounts present within /mnt Can't figure out what is causing this issue. It may be related to how I have Google Drive mounted with SMB? There is a "mounts" file in /mnt, but I'm not sure if that's expected to be there. Or maybe related to /mounts folder? Other possibility is perhaps I need to exclude /mnt from Recyle Bin plugin? Not sure. Diagnostics attached. Any help is appreciated. Thanks in advance homegrown-diagnostics-20240205-1957.zip
-
I am having an issue with the Tailscale Docker. All of my containers are accessible through IP & magicDNS, however my unraid WebUI does not resolve with neither Tailscale IP nor magicDNS. This issue also extends to SMB -- I am unable to access files on the server through Tailscale.Yes, my cache failed upon boot after upgrading to 6.12. I replaced the drive and rolled back to 6.11.5Thanks for the response @petchav! Unfortunately, typing the VM name within the CLI wrapped in quotes does not work. Here's an example of the script not working with a VM name that has spaces. Here it is working perfectly for a VM name that does not have any spaces. And here it is failing when wrapping the VM name in quotes. The error message is simply `!!! Backup file not found !!!`. I think there is another line or two in the script where the path needs to be wrapped in quotes, but I can't figure out where.
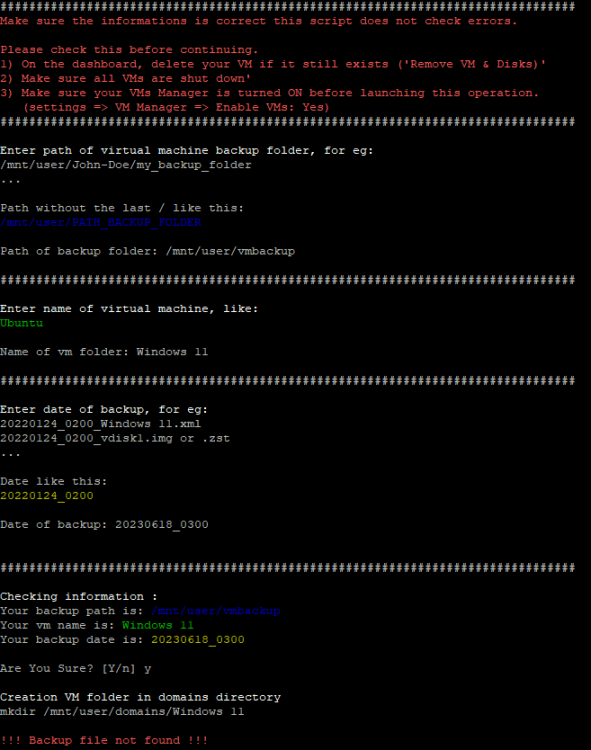
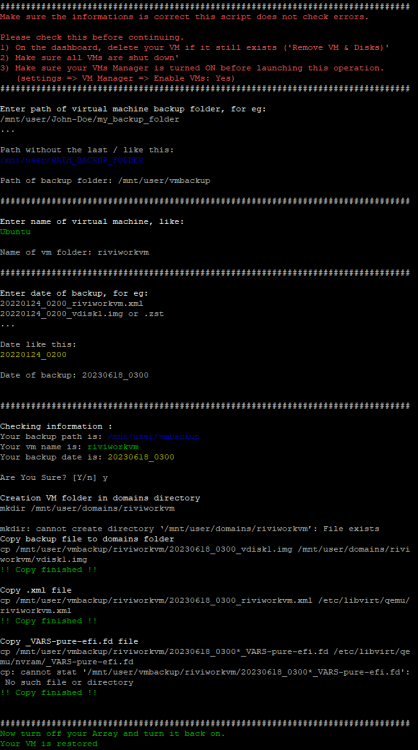
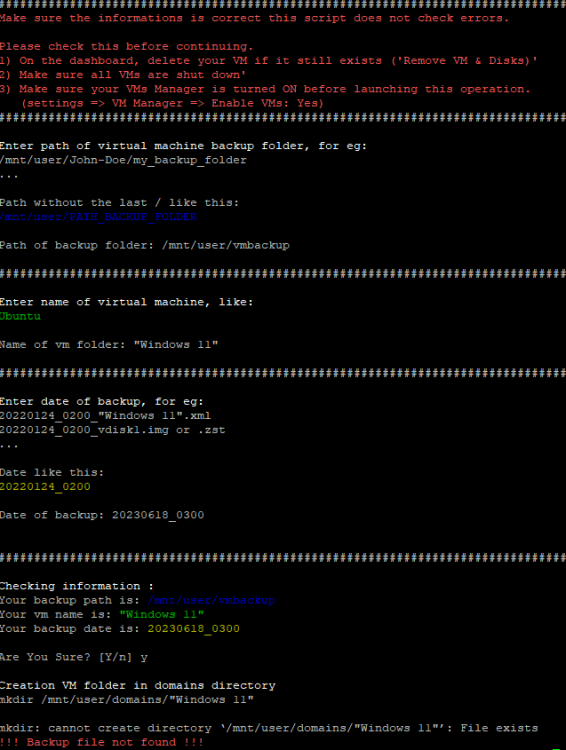 Shoot, I'm sorry Jorge -- I missed this. I was getting pretty frustrated and ultimately downgraded to 6.11.5 for now. Everything is working as intended again. Apologies that I didn't stick it out to test out why nginx was not starting.Yes, sorry for not being more clear! I am talking about the restoration script. It works great for VMs with no spaces in the name and I'm sure it can be fixed to work with VMs that do have spaces in their names, but it's not something I've been able to figure out with my limited knowledge.Can anyone help edit @petchav's script to work with VM names that include spaces? I don't know bash scripting, but have been trying to figure it out for the last hour. The most positive change I made is to line 87, mkdir /mnt/user/domains/$VM_NAME which I edited to mkdir "/mnt/user/domains/$VM_NAME" That got me past creating incorrect directories. Now if my VM name is "Windows 11", then it will create the correct directory in the domains folder. However, it is still failing after that with `!!! Backup file not found !!!` I've tried adding quotes at various places in lines 102, 112 & 120 but still the script fails at the same point. I've also tried adding quotes in various places to lines 89, 95, 110, 116 & 117 which are the lines that define `BACKUP_FILE`, but again, not making any progress. Figured someone that knows scripting and the correct syntax might be able to fix the script easilyPerhaps related, but there is no network.cfg file on my flash drive in the config folder. I only have a network-extra.cfg file. I'm not sure how that would disappear, but maybe it is part of my issue? Edit: Upon further research, I don't believe this is related to the issue. It seems if you don't make changes to Network settings, there is no network.cfg and the system utilizes default settings.This sounds similar to an issue I am facing right now, however, I'm on 6.12.1Diagnostics attached. Not sure what is up. I had a failed cache drive, shutdown the system to replace it, started the system again and got to the WebUI. Assigned the new cache drive and tried to start the array. Nothing was happening -- the start button was unresponsive. So I rebooted. Now, I cannot access the WebUI through localhost on the server itself nor through other devices on my local network. I also tried GUI safe mode, but still no WebGUI. The server seems to boot fine and I do have SSH access. Any help is greatly appreciated. tower-diagnostics-20230624-2100.zipUnderstood and thank you. My new SSD will be here tomorrow and I'll follow this process.Thanks. Is there a guide to follow to rebuild cache after a failed disk? I didn't find this particular situation in the documentation. After replacing the cache drive with a new one, what's next? Reinstall all Docker containers and then copy over the appdata that I pulled off the failing drive?I am on 6.12.1. I didn't realize the CA Backup plugin was deprecated. My cache drive is corrupt / failed (Unmountable: Unsupported or no file system). I only have backups from CA Backup plugin (from 6.11.5), not from your new plugin. I understand from your pinned post that the CA backups cannot be restored with your new Appdata Backup plugin. Is there a workaround? I was also able to mount the failing cache drive to /temp and copy off all of the contents. Perhaps that is useful in rebuilding a new cache drive?Ok I will look into it. ddrescue is new to me. Thank you. I found this post from you in the FAQ and was able to mount the drive to /temp and copy off all of the contents. Is that useful in rebuilding a new cache drive?Thanks for the reply, Jorge. I'll replace the Cache-docker (sdd) drive. What is the best process to replace & rebuild the drive since it is unmountable -- I have appdata & vm backups from the CA plugin, but I'm only now realizing that the plugin is deprecated in 6.12. I didn't know that and since I've been on 6.12 / 6.12.1 for about a week, my last appdata & vm backups are from June 15th. If I install the new Appdata Backup plugin, will it be able to restore my backups from the previous plugin? Assuming so, would I just shutdown the array, replace the Cache-docker drive, start the array, assign the new disk as Cache-docker and then restore appdata & vm backups?Diagnostics attached. I had an issue on 6.12 where my Docker containers would not update -- it was throwing an error saying the container name already existed. Then I noticed some of my containers were not working and all of the Database containers were stopped and would not start. I figured it may be a bug in the new stable version, so I upgraded to 6.12.1 Upon starting the array, the Docker would not start. Then I saw on the Main tab that my Cache-docker pool is showing as Unmountable: Unsupported or no file system. Any help is much appreciated! I saw a similar thread here, but couldn't get the btrfs rescue command figured out. homegrown-diagnostics-20230622-2105.zip
Shoot, I'm sorry Jorge -- I missed this. I was getting pretty frustrated and ultimately downgraded to 6.11.5 for now. Everything is working as intended again. Apologies that I didn't stick it out to test out why nginx was not starting.Yes, sorry for not being more clear! I am talking about the restoration script. It works great for VMs with no spaces in the name and I'm sure it can be fixed to work with VMs that do have spaces in their names, but it's not something I've been able to figure out with my limited knowledge.Can anyone help edit @petchav's script to work with VM names that include spaces? I don't know bash scripting, but have been trying to figure it out for the last hour. The most positive change I made is to line 87, mkdir /mnt/user/domains/$VM_NAME which I edited to mkdir "/mnt/user/domains/$VM_NAME" That got me past creating incorrect directories. Now if my VM name is "Windows 11", then it will create the correct directory in the domains folder. However, it is still failing after that with `!!! Backup file not found !!!` I've tried adding quotes at various places in lines 102, 112 & 120 but still the script fails at the same point. I've also tried adding quotes in various places to lines 89, 95, 110, 116 & 117 which are the lines that define `BACKUP_FILE`, but again, not making any progress. Figured someone that knows scripting and the correct syntax might be able to fix the script easilyPerhaps related, but there is no network.cfg file on my flash drive in the config folder. I only have a network-extra.cfg file. I'm not sure how that would disappear, but maybe it is part of my issue? Edit: Upon further research, I don't believe this is related to the issue. It seems if you don't make changes to Network settings, there is no network.cfg and the system utilizes default settings.This sounds similar to an issue I am facing right now, however, I'm on 6.12.1Diagnostics attached. Not sure what is up. I had a failed cache drive, shutdown the system to replace it, started the system again and got to the WebUI. Assigned the new cache drive and tried to start the array. Nothing was happening -- the start button was unresponsive. So I rebooted. Now, I cannot access the WebUI through localhost on the server itself nor through other devices on my local network. I also tried GUI safe mode, but still no WebGUI. The server seems to boot fine and I do have SSH access. Any help is greatly appreciated. tower-diagnostics-20230624-2100.zipUnderstood and thank you. My new SSD will be here tomorrow and I'll follow this process.Thanks. Is there a guide to follow to rebuild cache after a failed disk? I didn't find this particular situation in the documentation. After replacing the cache drive with a new one, what's next? Reinstall all Docker containers and then copy over the appdata that I pulled off the failing drive?I am on 6.12.1. I didn't realize the CA Backup plugin was deprecated. My cache drive is corrupt / failed (Unmountable: Unsupported or no file system). I only have backups from CA Backup plugin (from 6.11.5), not from your new plugin. I understand from your pinned post that the CA backups cannot be restored with your new Appdata Backup plugin. Is there a workaround? I was also able to mount the failing cache drive to /temp and copy off all of the contents. Perhaps that is useful in rebuilding a new cache drive?Ok I will look into it. ddrescue is new to me. Thank you. I found this post from you in the FAQ and was able to mount the drive to /temp and copy off all of the contents. Is that useful in rebuilding a new cache drive?Thanks for the reply, Jorge. I'll replace the Cache-docker (sdd) drive. What is the best process to replace & rebuild the drive since it is unmountable -- I have appdata & vm backups from the CA plugin, but I'm only now realizing that the plugin is deprecated in 6.12. I didn't know that and since I've been on 6.12 / 6.12.1 for about a week, my last appdata & vm backups are from June 15th. If I install the new Appdata Backup plugin, will it be able to restore my backups from the previous plugin? Assuming so, would I just shutdown the array, replace the Cache-docker drive, start the array, assign the new disk as Cache-docker and then restore appdata & vm backups?Diagnostics attached. I had an issue on 6.12 where my Docker containers would not update -- it was throwing an error saying the container name already existed. Then I noticed some of my containers were not working and all of the Database containers were stopped and would not start. I figured it may be a bug in the new stable version, so I upgraded to 6.12.1 Upon starting the array, the Docker would not start. Then I saw on the Main tab that my Cache-docker pool is showing as Unmountable: Unsupported or no file system. Any help is much appreciated! I saw a similar thread here, but couldn't get the btrfs rescue command figured out. homegrown-diagnostics-20230622-2105.zip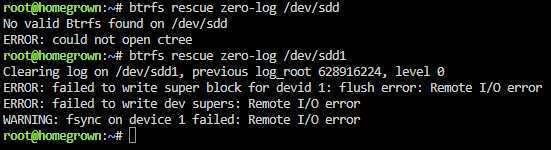 Thanks for the reply, EDACerton. I also saw your PM. I'm not sure what's going on -- everything I Google essentially says it is a bug with NetworkManager / ConnectivityCheck and doesn't affect the operation of Tailscale. However, it is annoying and I don't remember having this issue when I was using the Tailscale Docker Container. I'm not sure if the research I've done is related to the syslog being spammed with the above, but it's all I could find searching around. https://github.com/tailscale/tailscale/issues/5175 https://forum.tailscale.com/t/ratelimit-format-open-conn-track-timeout-opening-v-no-associated-peer-node/1456/2 https://forum.tailscale.com/t/open-conn-track-timeout/2231 FWIW, unraid is setup as an exit node in Tailscale. I've also tested with Accept Routes on & off as well as Accept DNS on & off. Logs still get spammed with the same.My logs are littered with... Jun 14 15:54:24 homegrown tailscaled: 2023/06/14 15:54:24 open-conn-track: timeout opening (TCP 100.71.223.5:51675 => 172.64.96.12:443); no associated peer node Jun 14 15:54:27 homegrown tailscaled: 2023/06/14 15:54:27 open-conn-track: timeout opening (TCP 100.71.223.5:51675 => 172.64.96.12:443); no associated peer node Jun 14 15:54:37 homegrown tailscaled: 2023/06/14 15:54:37 open-conn-track: timeout opening (TCP 100.71.223.5:47567 => 45.154.253.8:80); no associated peer node Jun 14 15:54:39 homegrown tailscaled: 2023/06/14 15:54:39 open-conn-track: timeout opening (TCP 100.71.223.5:51675 => 172.64.96.12:443); no associated peer node Jun 14 15:54:40 homegrown tailscaled: 2023/06/14 15:54:40 open-conn-track: timeout opening (TCP 100.71.223.5:47567 => 45.154.253.8:80); no associated peer node Jun 14 15:54:47 homegrown tailscaled: 2023/06/14 15:54:47 open-conn-track: timeout opening (TCP 100.71.223.5:42959 => 45.154.253.8:80); no associated peer node Jun 14 15:54:47 homegrown tailscaled: 2023/06/14 15:54:47 open-conn-track: timeout opening (TCP 100.71.223.5:54857 => 172.64.163.13:443); no associated peer node Jun 14 15:54:50 homegrown tailscaled: 2023/06/14 15:54:50 open-conn-track: timeout opening (TCP 100.71.223.5:54857 => 172.64.163.13:443); no associated peer node Jun 14 15:54:50 homegrown tailscaled: 2023/06/14 15:54:50 open-conn-track: timeout opening (TCP 100.71.223.5:42959 => 45.154.253.8:80); no associated peer node Jun 14 15:54:50 homegrown tailscaled: 2023/06/14 15:54:50 [RATELIMIT] format("open-conn-track: timeout opening %v; no associated peer node") Jun 14 15:55:02 homegrown tailscaled: 2023/06/14 15:55:02 [RATELIMIT] format("open-conn-track: timeout opening %v; no associated peer node") (1 dropped) Jun 14 15:55:02 homegrown tailscaled: 2023/06/14 15:55:02 open-conn-track: timeout opening (TCP 100.71.223.5:54857 => 172.64.163.13:443); no associated peer node Jun 14 15:55:02 homegrown tailscaled: 2023/06/14 15:55:02 open-conn-track: timeout opening (TCP 100.71.223.5:42959 => 45.154.253.8:80); no associated peer node Everything seems to be working fine, but these lines are constantly repeating in the logs. Any insight?
Thanks for the reply, EDACerton. I also saw your PM. I'm not sure what's going on -- everything I Google essentially says it is a bug with NetworkManager / ConnectivityCheck and doesn't affect the operation of Tailscale. However, it is annoying and I don't remember having this issue when I was using the Tailscale Docker Container. I'm not sure if the research I've done is related to the syslog being spammed with the above, but it's all I could find searching around. https://github.com/tailscale/tailscale/issues/5175 https://forum.tailscale.com/t/ratelimit-format-open-conn-track-timeout-opening-v-no-associated-peer-node/1456/2 https://forum.tailscale.com/t/open-conn-track-timeout/2231 FWIW, unraid is setup as an exit node in Tailscale. I've also tested with Accept Routes on & off as well as Accept DNS on & off. Logs still get spammed with the same.My logs are littered with... Jun 14 15:54:24 homegrown tailscaled: 2023/06/14 15:54:24 open-conn-track: timeout opening (TCP 100.71.223.5:51675 => 172.64.96.12:443); no associated peer node Jun 14 15:54:27 homegrown tailscaled: 2023/06/14 15:54:27 open-conn-track: timeout opening (TCP 100.71.223.5:51675 => 172.64.96.12:443); no associated peer node Jun 14 15:54:37 homegrown tailscaled: 2023/06/14 15:54:37 open-conn-track: timeout opening (TCP 100.71.223.5:47567 => 45.154.253.8:80); no associated peer node Jun 14 15:54:39 homegrown tailscaled: 2023/06/14 15:54:39 open-conn-track: timeout opening (TCP 100.71.223.5:51675 => 172.64.96.12:443); no associated peer node Jun 14 15:54:40 homegrown tailscaled: 2023/06/14 15:54:40 open-conn-track: timeout opening (TCP 100.71.223.5:47567 => 45.154.253.8:80); no associated peer node Jun 14 15:54:47 homegrown tailscaled: 2023/06/14 15:54:47 open-conn-track: timeout opening (TCP 100.71.223.5:42959 => 45.154.253.8:80); no associated peer node Jun 14 15:54:47 homegrown tailscaled: 2023/06/14 15:54:47 open-conn-track: timeout opening (TCP 100.71.223.5:54857 => 172.64.163.13:443); no associated peer node Jun 14 15:54:50 homegrown tailscaled: 2023/06/14 15:54:50 open-conn-track: timeout opening (TCP 100.71.223.5:54857 => 172.64.163.13:443); no associated peer node Jun 14 15:54:50 homegrown tailscaled: 2023/06/14 15:54:50 open-conn-track: timeout opening (TCP 100.71.223.5:42959 => 45.154.253.8:80); no associated peer node Jun 14 15:54:50 homegrown tailscaled: 2023/06/14 15:54:50 [RATELIMIT] format("open-conn-track: timeout opening %v; no associated peer node") Jun 14 15:55:02 homegrown tailscaled: 2023/06/14 15:55:02 [RATELIMIT] format("open-conn-track: timeout opening %v; no associated peer node") (1 dropped) Jun 14 15:55:02 homegrown tailscaled: 2023/06/14 15:55:02 open-conn-track: timeout opening (TCP 100.71.223.5:54857 => 172.64.163.13:443); no associated peer node Jun 14 15:55:02 homegrown tailscaled: 2023/06/14 15:55:02 open-conn-track: timeout opening (TCP 100.71.223.5:42959 => 45.154.253.8:80); no associated peer node Everything seems to be working fine, but these lines are constantly repeating in the logs. Any insight?







