




jcamer
Members
-
Joined
-
Last visited
-
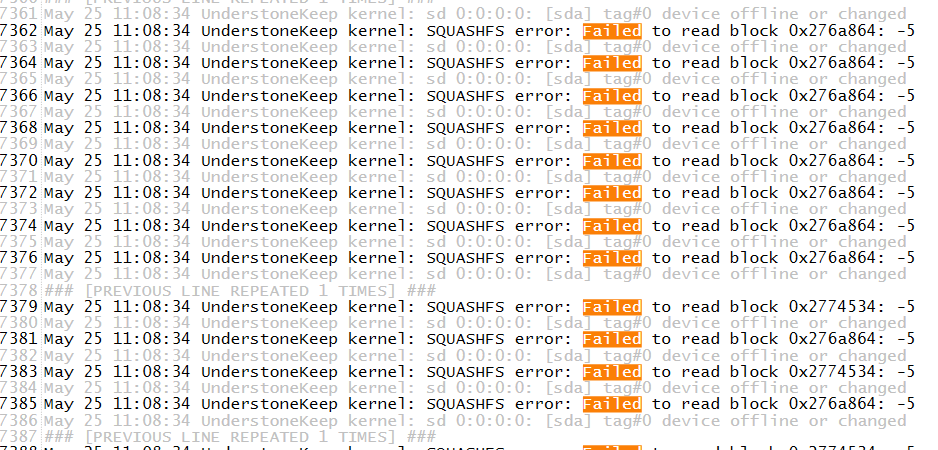
Ok, thanks for the reply. I ran the diagnostics and it appears I'm looking for a new drive as well. Thanks again!
-
How has it been since you replaced the reader? I have very similar issues although I don't have an adapter, just a regular USB drive. Exact same symptoms.
-
I see on that link it was fixed in version 6.2.4, and that there is a 6.2.9 out now as well as 6.3 RC's. Did you try to move to 6.2.4 or newer? I just ran into this on 6.2. Not sure what to do as the docker website shows the official image as only being released as 6.2 so far.
-
So glad I found this. I've been having issues with my dockers and then noticed this, although unrelated. I thought there was something bigger going on. Same thing for me, closed Brave and reopened and my drives/array now show again.
-
I am having the exact same issue. I haven't touched it, except maybe for updating it when there is an update. I don't really use it all that much so I am not sure when it happened, but like you, it is unreachable. I am using OpenVPN with NordVPN. If I set VPN to no, it works just fine. Downloads, opens the web ui, etc. Of course, no VNP. Here's a snippet from the console.. Well I downloaded a new cert from NordVPN and replaced the old one, fixed everything for me. I went back a few pages and saw someone else had that same issue. All good now.
-
What commands do you use to get them up and running?
-
This solution has so far worked for me as well, with just the serial entry. I feel like going from 10.1 to 10.2 broke it again and I had to redo it and I was nervous going to 10.3, but it went smoothly. I do wish just adding the usb device would work as expected (or as I expect it to), but I guess if the serial way works for now, I'll go with it.
-
Same here.. I did the 6.10rc's and am now on the final. I didn't put it together that it was the cause but I am also thinking it must be. Same as others, Home Assistant VM with ConbeeII. I also tried to update the firmware on mine with a Windows machine and while it did update to the latest successfully, it has made no difference.


