




Björn f.
Members
-
Joined
-
Last visited
Everything posted by Björn f.
-
ich habe den support direkt angeschrieben, entnervt habe ich das system nun auf 6.11.5 zurück gesetzt alle docker wieder eingerichtet und alles läuft nun wieder auch meine VM`s wie ich aber die pool datenträger auf XFS uminstalliere ich mir noch ein rätzel ich kann nur btrfs,...
-
heute ist der server wieder hängen geblieben, vm`s waren deaktivert ! ich habe mal den aktuellen log beigefügt. cache platten kann ich nicht anderweitig formatieren da ging nur BTRFS ?! server-diagnostics-20230725-1949.zip syslog
-
habe je beschrieben das ich an der fehlersuche dran bin,... der witz ist wenn ich die VM geschichte nicht Starte, habe ich weder fehler noch bleibt das system hängen. ich häng mal die gewünschten daten an server-diagnostics-20230725-1949.zip syslog hier nun auch wieder der aktuelle Log (copy Paste) nut die errors Jul 25 19:47:01 Server root: Error response from daemon: Pool overlaps with other one on this address space Jul 25 19:47:01 Server root: Error: Nexthop has invalid gateway. Jul 25 19:47:06 Server kernel: CPU: 1 PID: 2217 Comm: kworker/u32:5 Tainted: P O 6.1.38-Unraid #2 Jul 25 19:47:06 Server kernel: Call Trace: Jul 25 19:46:24 Server kernel: BTRFS info (device nvme0n1p1): using crc32c (crc32c-intel) checksum algorithm Jul 25 19:46:58 Server kernel: BTRFS info (device loop2): using crc32c (crc32c-intel) checksum algorithm Jul 25 19:47:01 Server kernel: BTRFS info (device loop3): using crc32c (crc32c-intel) checksum algorithm Jul 25 19:47:01 Server crond[1676]: failed parsing crontab for user root: /usr/local/emhttp/plugins/tips.and.tweaks/scripts/rc.tweaks set_governor powersave &> /dev/null Jul 25 19:47:01 Server crond[1676]: failed parsing crontab for user root: /usr/local/emhttp/plugins/tips.and.tweaks/scripts/rc.tweaks set_governor powersave &> /dev/null Jul 25 19:47:06 Server kernel: WARNING: CPU: 1 PID: 2217 at net/netfilter/nf_conntrack_core.c:1210 __nf_conntrack_confirm+0xa4/0x2b0 [nf_conntrack]
-
es scheint an den VM`s zu liegen ! der server lief den ganzen tag, ich musste einen lüfter noch tauschen jetzt startet es nicht mehrm der usb stick wollte wohl auch nicht mehr und ist über das ufer gegangen. nun hoffe ich das der support mit den key wieder freigibt
-
Update: Ich habe nun die Cache SSDS erneuer, von gestern auf heute dachte ich dann es läuft wieder alles TOP habe auch keine fehler mehr im log, heute noch die VM`s angeworfen, zack 10-20 minuten später server nicht mehr erreichbar. verdacht liegt noch bei einem defekten usb stick, obwohl das system diesen ja nur zum starten benötigt,.. ich werde nun den server mal laufen lassen ohne VM`S die 6.11 Version von unraid hatte damals ja einwandfrei funktioniert ! Hier noch der Aktuelle log

-
ich versucht erstmal zugriff auf die 1 jahr alte hdd zu bekommen frage ist nur warum sich unraid immer wieder aufhängt
-
also langsam ferzweifel ich mit dieser kisten,.. Aktuell war ich dabei die HDD mit dem defekten Filesystem zu reparieren nun ist der server wieder nicht erreichbar (per Webgui) ,.. Nur dieses mal ist er auch per Ping nicht mehr zu erreichen nach einigen Minuten, ich verstehe es nicht mehr !

-
also scheinbar hat eine HDD XFS PRobleme bin aktuell schon am reparieren. trotzdem hier mal der SYSlog Jul 18 22:09:05 Server kernel: ACPI: Early table checksum verification disabled Jul 18 22:09:05 Server kernel: floppy0: no floppy controllers found Jul 18 22:09:15 Server mcelog: failed to prefill DIMM database from DMI data Jul 18 22:09:46 Server kernel: BTRFS info (device nvme1n1p1): using crc32c (crc32c-intel) checksum algorithm Jul 18 22:09:56 Server kernel: XFS (sde1): Internal error xfs_efi_item_recover at line 614 of file fs/xfs/xfs_extfree_item.c. Caller xlog_recover_process_intents+0x99/0x25e [xfs] Jul 18 22:09:56 Server kernel: CPU: 9 PID: 12297 Comm: mount Tainted: P O 6.1.38-Unraid #2 Jul 18 22:09:56 Server kernel: Call Trace: Jul 18 22:09:56 Server kernel: XFS (sde1): Failed to recover intents Jul 18 22:09:56 Server kernel: XFS (sde1): Filesystem has been shut down due to log error (0x2). Jul 18 22:09:56 Server kernel: XFS (sde1): log mount finish failed Jul 18 22:09:59 Server unassigned.devices: Mount of 'sde1' failed: 'mount: /mnt/disks/32X0A03RFVGG: mount(2) system call failed: Structure needs cleaning. dmesg(1) may have more information after failed mount system call. ' Jul 18 22:10:10 Server kernel: BTRFS info (device loop2): using crc32c (crc32c-intel) checksum algorithm Jul 18 22:10:50 Server root: Error response from daemon: Pool overlaps with other one on this address space Jul 18 22:10:50 Server kernel: BTRFS info (device loop3): using crc32c (crc32c-intel) checksum algorithm Jul 18 22:12:33 Server rc.docker: StorJ_002_VPS_001: Error response from daemon: invalid mount config for type "bind": bind source path does not exist: /mnt/disks/32X0A03RFVGG/Storj_02/Identity/storagenode/ Jul 18 22:12:33 Server rc.docker: Error: failed to start containers: StorJ_002_VPS_001 Jul 18 22:12:40 Server rc.docker: StorJ_004_VPS_003: Error response from daemon: invalid mount config for type "bind": bind source path does not exist: /mnt/disks/32X0A03RFVGG/Storj_04/Identity/storagenode/ Jul 18 22:12:40 Server rc.docker: Error: failed to start containers: StorJ_004_VPS_003 Jul 18 22:15:03 Server kernel: XFS (sde1): Internal error xfs_efi_item_recover at line 614 of file fs/xfs/xfs_extfree_item.c. Caller xlog_recover_process_intents+0x99/0x25e [xfs] Jul 18 22:15:03 Server kernel: CPU: 4 PID: 16804 Comm: mount Tainted: P O 6.1.38-Unraid #2 Jul 18 22:15:03 Server kernel: Call Trace: Jul 18 22:15:03 Server kernel: XFS (sde1): Failed to recover intents Jul 18 22:15:03 Server kernel: XFS (sde1): Filesystem has been shut down due to log error (0x2). Jul 18 22:15:03 Server kernel: XFS (sde1): log mount finish failed Jul 18 22:15:06 Server unassigned.devices: Mount of 'sde1' failed: 'mount: /mnt/disks/32X0A03RFVGG: mount(2) system call failed: Structure needs cleaning. dmesg(1) may have more information after failed mount system call. ' Jul 18 22:15:23 Server kernel: XFS (sde1): Internal error xfs_efi_item_recover at line 614 of file fs/xfs/xfs_extfree_item.c. Caller xlog_recover_process_intents+0x99/0x25e [xfs] Jul 18 22:15:23 Server kernel: CPU: 3 PID: 21086 Comm: mount Tainted: P O 6.1.38-Unraid #2 Jul 18 22:15:23 Server kernel: Call Trace: Jul 18 22:15:23 Server kernel: XFS (sde1): Failed to recover intents Jul 18 22:15:23 Server kernel: XFS (sde1): Filesystem has been shut down due to log error (0x2). Jul 18 22:15:23 Server kernel: XFS (sde1): log mount finish failed Jul 18 22:15:25 Server unassigned.devices: Mount of 'sde1' failed: 'mount: /mnt/disks/32X0A03RFVGG: mount(2) system call failed: Structure needs cleaning. dmesg(1) may have more information after failed mount system call. ' Jul 18 22:18:13 Server kernel: sd 5:0:1:0: [sde] Synchronize Cache(10) failed: Result: hostbyte=0x01 driverbyte=DRIVER_OK Jul 18 22:18:41 Server kernel: XFS (sde1): Internal error xfs_efi_item_recover at line 614 of file fs/xfs/xfs_extfree_item.c. Caller xlog_recover_process_intents+0x99/0x25e [xfs] Jul 18 22:18:41 Server kernel: CPU: 8 PID: 1677 Comm: mount Tainted: P O 6.1.38-Unraid #2 Jul 18 22:18:41 Server kernel: Call Trace: Jul 18 22:18:41 Server kernel: XFS (sde1): Failed to recover intents Jul 18 22:18:41 Server kernel: XFS (sde1): Filesystem has been shut down due to log error (0x2). Jul 18 22:18:41 Server kernel: XFS (sde1): log mount finish failed Jul 18 22:18:43 Server unassigned.devices: Mount of 'sde1' failed: 'mount: /mnt/disks/32X0A03RFVGG: mount(2) system call failed: Structure needs cleaning. dmesg(1) may have more information after failed mount system call. ' Jul 18 22:18:51 Server kernel: XFS (sde1): Internal error xfs_efi_item_recover at line 614 of file fs/xfs/xfs_extfree_item.c. Caller xlog_recover_process_intents+0x99/0x25e [xfs] Jul 18 22:18:51 Server kernel: CPU: 8 PID: 7630 Comm: mount Tainted: P O 6.1.38-Unraid #2 Jul 18 22:18:51 Server kernel: Call Trace: Jul 18 22:18:51 Server kernel: XFS (sde1): Failed to recover intents Jul 18 22:18:51 Server kernel: XFS (sde1): Filesystem has been shut down due to log error (0x2). Jul 18 22:18:51 Server kernel: XFS (sde1): log mount finish failed Jul 18 22:18:54 Server unassigned.devices: Mount of 'sde1' failed: 'mount: /mnt/disks/32X0A03RFVGG: mount(2) system call failed: Structure needs cleaning. dmesg(1) may have more information after failed mount system call. ' Jul 18 22:33:33 Server kernel: WARNING: CPU: 8 PID: 27773 at net/netfilter/nf_conntrack_core.c:1210 __nf_conntrack_confirm+0xa4/0x2b0 [nf_conntrack] Jul 18 22:33:33 Server kernel: CPU: 8 PID: 27773 Comm: kworker/u32:0 Tainted: P O 6.1.38-Unraid #2
-
Nun nach einem Tag das gleiche Problem Die Weboberfläche wird angezeigt, der Login ist nicht möglich, ein Teil der Docker läuft, Heimdall und Grafana, die restlichen Docker sind inaktiv (vermutlich) der zugriff auf den Server war nur über Terminal möglich und habe diese somit neustarten müssen
-
hat sich erledigt, schein wohl ein problem mit der unraid version 6.12.2 zu tun zu haben,.. habe das downgrade versucht leider liefen dann keine docker mehr, habe dan aktualisiert auf 6.12.3 und nun läuft aktuell alles einwandfrei
-
Hallo zusammen, erst hatte ich das problem das meine Docker zuviel speicher gebraucht haben und ich zwei docker neu einrichten musste. und nun seit ca 7 Woche hängt sich alles auf. erst sind die docker offline, obwohl die als onlien angezeigt werden. Der Server Reagiert träger (von handy und Tablet erreiche ich diesen kaum mehr), ausser vom localen pc. und dann nach einer gewissen zeit geht garnichts mehr... Memory cgroup out of memory ich konnte nur ein teil meines LOgs auslesen. Jul 16 08:02:59 Server kernel: oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=/,mems_allowed=0,oom_memcg=/docker/8bd5147b1c777e33cb737cc7a66c6d4c4e7ac668c1efcd792b595793c89ca2c0,task_memcg=/docker/8bd5147b1c777e33cb737cc7a66c6d4c4e7ac668c1efcd792b595793c89ca2c0,task=nginx,pid=24267,uid=0 Jul 16 08:02:59 Server kernel: Memory cgroup out of memory: Killed process 24267 (nginx) total-vm:106964kB, anon-rss:8944kB, file-rss:0kB, shmem-rss:76kB, UID:0 pgtables:92kB oom_score_adj:0 Jul 16 08:03:01 Server kernel: oom_reaper: reaped process 24267 (nginx), now anon-rss:0kB, file-rss:0kB, shmem-rss:76kB Jul 16 08:05:34 Server kernel: rcu: INFO: rcu_preempt self-detected stall on CPU Jul 16 08:05:34 Server kernel: rcu: 8-....: (24900539 ticks this GP) idle=4574/1/0x4000000000000000 softirq=3514003/3514003 fqs=10947486 Jul 16 08:05:34 Server kernel: (t=24900540 jiffies g=5827493 q=117024973 ncpus=16) Jul 16 08:05:34 Server kernel: CPU: 8 PID: 8902 Comm: storagenode Tainted: P D W O 6.1.36-Unraid #1 hat jemand hierzu vielleicht eine idee ?
-
habe es verstanden, danke
-
okay danke euch erstmal ! dann werde ich vom server mit der Pro Version alles kopieren auf den USB Stick mit der Pro Version, ausser die .key datei ? Damit meine Config mit übernommen wird, oder muss ich weitere dateien beachten ?
-
Hallo zusammen, ich möchte aus meinen zwei server einen machen. Der Server 1 hat die Pro Version Der Server 2 hat die Plus Version Der Server 1 wird komplett entfernt und ich möchte den Lizensschlüssel des ersten Servers auf den Server 2 übertragen (da nun mehr HDD`s eingebaut werden) wie mache ich das ? Des weiteren wäre die Fragen, mein kollege würde meine Plus Version gerne übernehmen, wie kann ich Ihm diese übertragen ? Ich freue mich auf Positives Feedback und wünsche ein schönes Wochenende
-
Problem gelöst! Es liegt an der ip v6 scheinbar bekanntes Problem
-
Hi die ddns wird über die fritzbox aktualisiert wobei ich ipv4 und ipv6 nutze dank meines providers Nach dem Neustart meines Rechners, sieht es dann immer so aus Chrome und unten sieht man den IE. Internet Explorer (immer)
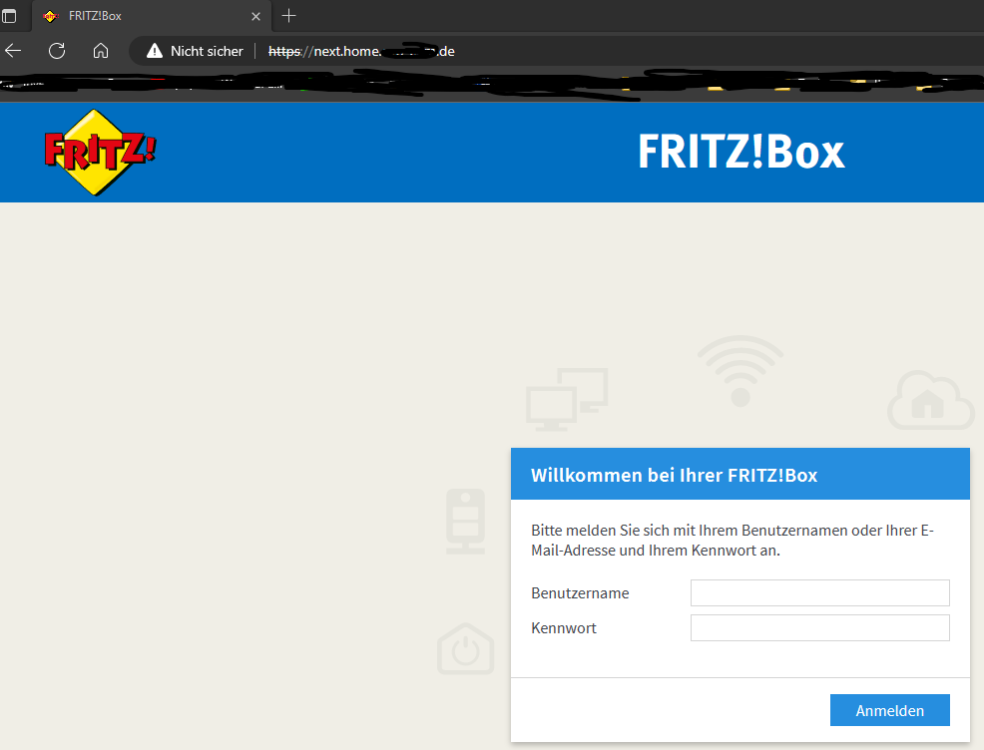
-
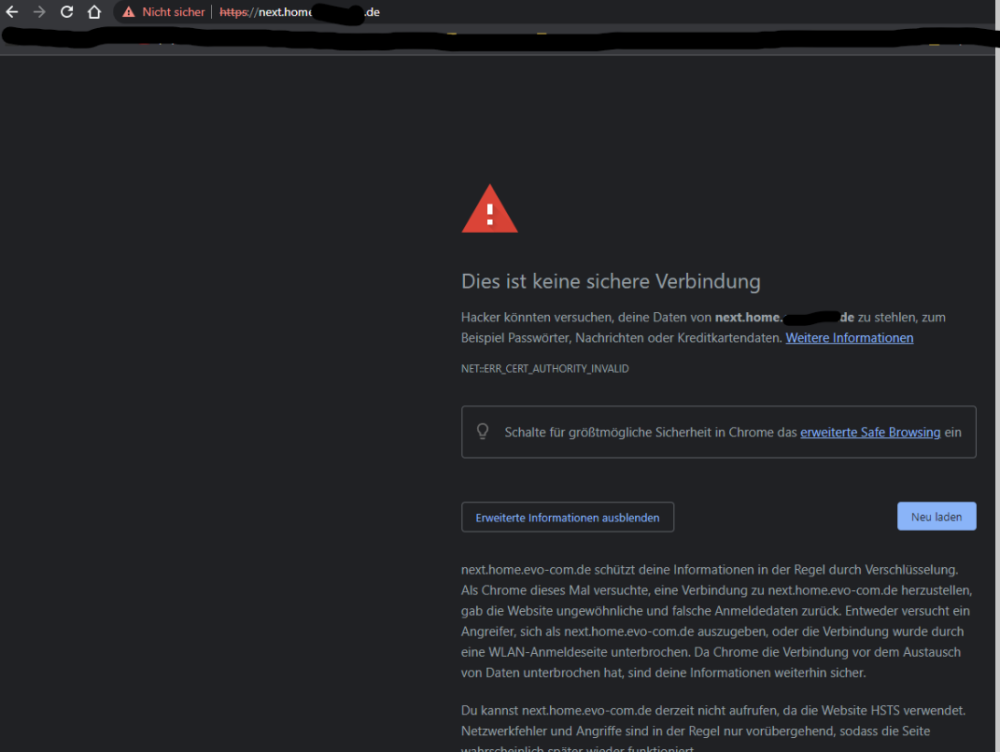
Hallo @mgutt ich gebe dir recht ich komme vom tablet nun auch auf die cloud. Vom Handy aus aber keine chance auch wenn ich mit beiden Geräten über die nextcloud arbeite lokal funktioniert es nicht. Sobald ich den Internet Explorer bei allen Geräten öffne und die Domain eingebe lande ich dann auf der fritzbox. Ich habe ich auch getestet im wartungsmodus dies ergibt aber leider auch kein Erfolg. Kann es sein das es doch an der ipv6 liegt? Habe ich hier noch Möglichkeiten dies zu testen ? Alternativ kommt kommende Woche ne neue fritzbox da die alte 7490 doch ein paar Jahre auf dem Buckel hat.
-
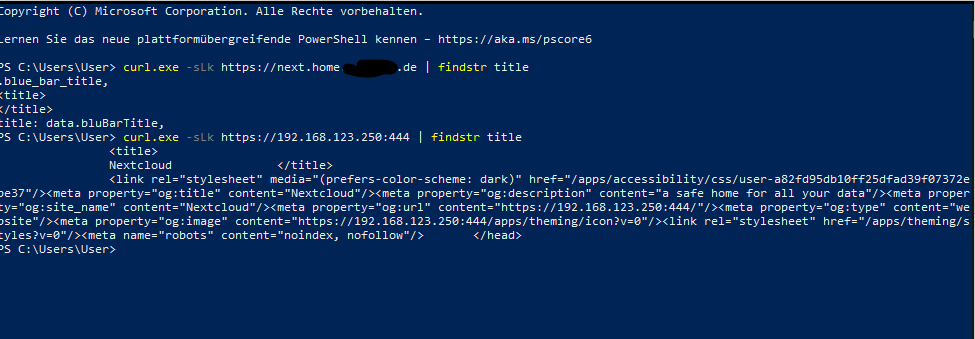
curl.exe -sLk https://deine.domain.de | findstr title es erscheint bei allen drein das gleiche und zwar dieses:

-
hi @mgutt also die Domain und die Subdomain nutzen die IPv4
-
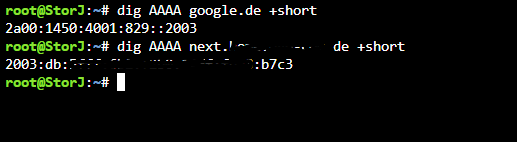
also hier bekomme ich meine ipv6 angezeigt. Ich habe hier bei meiner dyndns auch mal den abgleich für ipv4 abgeschaltet, habe trotzdem von außen zugriff auf meine cloud über ipv6 mein anbieter hat ipv4 und ipv6 wobei beides mit meinem dyndns anbieter auch abgeglichen wird, somit passt das ganze,.. also ein lokales problem ?
-
ja das ist die öffentliche ich, ist doch richtig so, ich ping ja meine subdomain vom NPM an, die Domain zeit ja dann auf meine fritzbox und von dort geht es weiter an Ngnix und von dort an die Nextcloud.
-
ups scheinbar hat es gestern meinen screenshort nicht übernommen!

-
Die VM bekomme ich Sporadisch nun zum Starten, aber die hängt sich auf,.. log spuckt mir aber nichts aus
-
naja spielt das eine rolle aus dem lan oder extern, wenn ich von lokal auf der fritzbox lande dann bekomme ich ja auch hier einen ping wert zurück aber wie du sehen kannst funktioniert dies ,..
-
so läuft die vm habe ich jetzt zum laufen bekommen warum auch immer ging es nicht, habe dann einen bios reset gemacht und dann die werte nochmals geprüft siehe da es funktioniert wieder, wobei beim starten eine art altes bios,.. Bei der Auswahl habe ich die SSD angewahlt nun steht seit 30 minuten Geräte werden betriebsbereit gemacht (nachricht von Windows)










