




semioniy
Members
-
Joined
-
Last visited
-
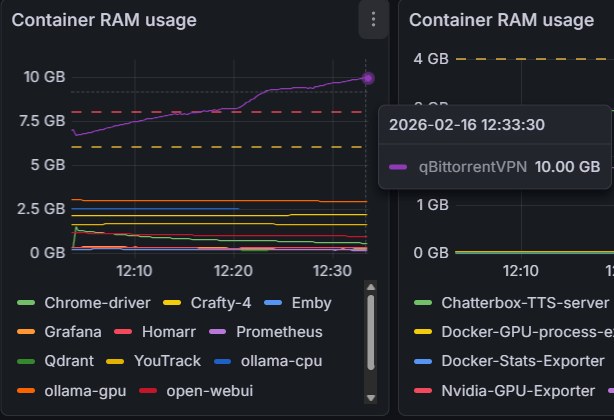
Howdy, partners. Just set up Grafana after a couple rounds of OOM and the whole server locking up (48GB RAM, we balling yes) and noticed the constant rise of RAM usage by qBittorrentVPN Never reported anything like this - what info can I provide to help?
-
This is very cool. Themes are a bit more vibrant than I prefer 😅, but huge thanks for this 🫡
-
Ok, thanx. So to summarize: There's no copying mechanism that'll transfer parity data from old parity drive to the new one. A new parity will have to be calculated from the ground up. And my options are (given that I don't want to run unprotected for the length of parity calculation on the new drive): Taking array offline for a considerable amount of time (in my case probably 2-3 days). Getting stuck with a disk labeled Parity 2 with no way to change this label later on (that will bother me immeasurably). I'm starting to consider running unprotected with the array live while calculating a new parity 😅🫡
-
Does this mean that in my case (no disk has failed) I can't replace the parity drive with a larger one without running a considerable amount of time with array unprotected, while the parity is recalculated?
-
Hi. I have an array of 5 HHDs, 4 data + 1 parity, current parity is 16 TB. I'm trying to carry out a parity swap as described here: https://docs.unraid.net/unraid-os/using-unraid-to/manage-storage/array-configuration/#parity-swap TLDR - I pre-cleared a new larger drive I want to add: #################################################################################################### # Unraid Server Preclear of disk ZR578FYC # # Cycle 1 of 1, partition start on sector 64. # # # # Step 1 of 5 - Pre-read verification: [24:11:38 @ 206 MB/s] SUCCESS # # Step 2 of 5 - Zeroing the disk: [24:14:23 @ 206 MB/s] SUCCESS # # Step 3 of 5 - Writing Unraid's Preclear signature: SUCCESS # # Step 4 of 5 - Verifying Unraid's Preclear signature: SUCCESS # # Step 5 of 5 - Post-Read verification: [24:11:48 @ 206 MB/s] SUCCESS # # # #################################################################################################### # Cycle elapsed time: 72:38:15 | Total elapsed time: 72:38:16 # ####################################################################################################And am trying to do the following: Unassign old 16TB parity drive from parity slot Assign new pre-cleared 18TB drive to parity slot Assign old 16TB parity drive to a data slot Expected behavior: Somewhere in the Array Operation area, around the Start button, a Copy button / checkbox appears, allowing my to carry over the parity information to the new drive without running a 80 hours parity sync with array unprotected. Am I missing a step? Old configuration: New configuration: Array Operation area after swapping the disks:
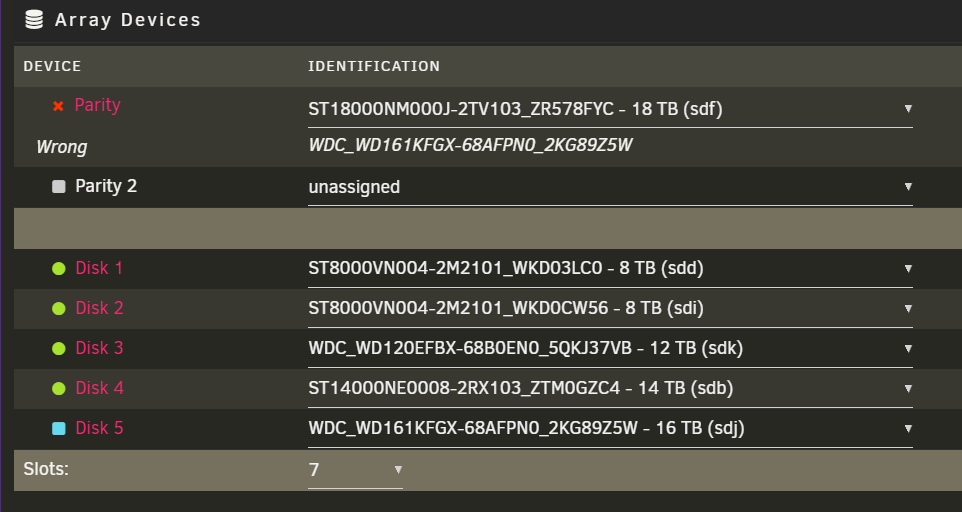

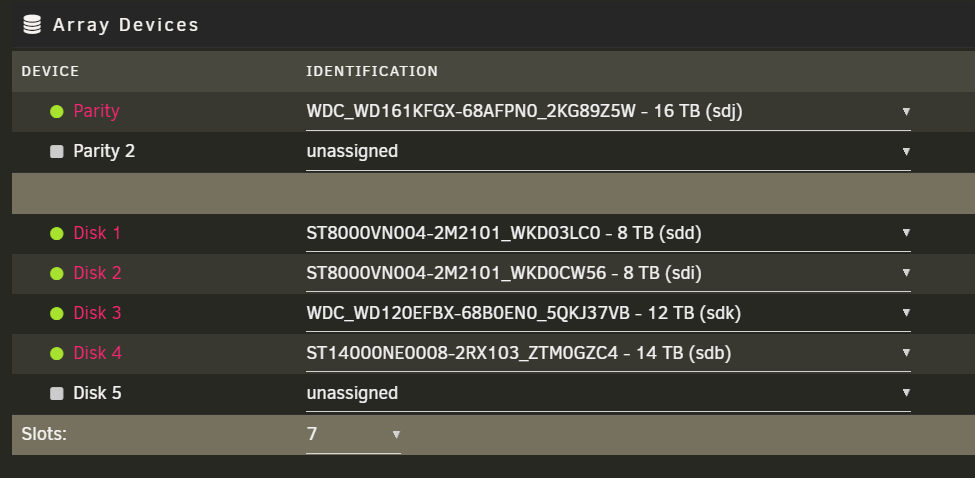
-
Thanx, but my SSDs are SATA, not nvme. I'll add it regardless, maybe I'll install a nvme drive in the future 😁
-
The issue of cache drives dropping offline has returned despite UPS. UPS added some stability for sure, but, apparently, didn't solve the problem altogether.
-
Sure, as I wrote — I accept it as a part of hobby, and use a btrfs dev stats script that runs on schedule myself. What I don't understand is the following: since UnRaid's primary purpose is to make NAS storage simple and abstract from different storage devices, Why does it not do something when one of these storage devices gets disconnected on a live array? Like, at least detect that a /dev/sdx device can't be communicated with anymore and notify user about it.
-
Well, I ran the script from SpaceInvader1, and it didn't find any problems, and could free respectable 175KB of space 😁 So, I guess I'll assume it's all good. BTW, doing simple math - 14GB would be 70% of default 20GB, and crossing this threshold would give you a utilization warning. Having 13GB with 20 containers installed, 1 or 2 additional containers (or even a container updating) could already give you a warning, forcing you to either increase the utilization level warning threshold, or enlarge your docker image. So, I think I'll chill and won't worry too much about not following the "20 GB should be enough" rule, given how much I love to play around with docker 😁
-
TLDR: When a disk from cache pool disconnects, UnRaid keeps the pool online, slowly letting btrfs errors accumulate, but doesn't notify the user about the drive being offline, and I don't quite understand, why. I have 3 SSDs on my server, forming a btrfs cache pool. From time to time, be the reason a vibration in the room, a problem with a SATA controller / cable, or whatever else, an SSD drops offline, and the cache pool starts accumulating btrfs errors. Knowing about this problem, and having encountered it previously, I run a `dev stats` script every hour that checks btrfs for errors and notifies me if it finds any. I assume, it's just a part of the hobby, me being my own sysadmin and running a virtualization server at home. What I don't quite understand is the following — why doesn't UnRaid detect this and notify user in some way? If I wouldn't run the script myself, I wouldn't know about the problem, until the pool would accumulate enough errors that even shutting the machine down, re-plugging all the cables, turning it on and running a correcting scrub operation wouldn't help anymore, forcing me to reformat the drives and recreate the pool. Been there, done that. So, my question: why doesn't UnRaid probe the drives to notice when they drop offline? As far as I could see, even when I stopped the array, the drive in question seemed to be present, even though UnRaid clearly couldn't communicate with it, and only after a reboot the system could tell that a drive actually WAS missing. Is it a hardware limitation? SATA does support hot-pluggability to some extent, so there probably is a way to know when a drive disconnects. P.S. also, facing this problem last time I noticed, that running `btrfs scrub start /mnt/cache` from the console shows me errors, but running a scrub operation from the UI returned no errors whatsoever, so without using the command directly / running a scheduled script I wouldn't even know that something happened even if I was looking for an issue.
-
For those who stumble upon this topic in the future, here's the video.
-
Hi. @Hoopster, does this rule of thumb apply to everyone, or only to those who doesn't use UnRaid as a virtualization server with 25 containers running? 😁
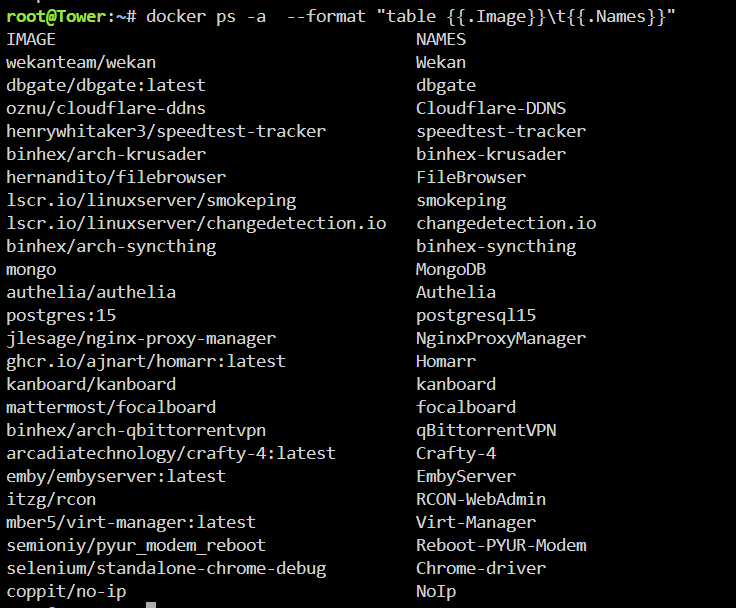
-
So, I have been troubleshooting for a week after my last post, but couldn't find anything. I checked cloudflare settings, ngingx and whatnot. It did look as if a WebUI page would load, but wouldn't open up web sockets for updating all the live information, but I couldn't figure out why, then impatience took over and I gave up on it. Well, would you know, 2 months later it works perfectly, and all I did is a whole lot of nothing! I didn't touch anything, didn't update anything on the UnRaid side, but it suddenly started working properly again. So, attempting to isolate the issue: since I didn't touch UnRaid, there are 2 variables in the chain that might have changed: Cloudflare - they constantly update their services and silently change things in the background, as far as my understanding goes, so they might have repaired what they previously have broken. I kinda doubt it though, because a half of the internet runs through the cloudflare, and if they had a faulty support for web sockets, there'd be a fire under their butt. Browser (chrome in my case) - a couple of versions since my last post, but I didn't pay too close attention. If it is a browser update breaking things though, I'll watch it closelier from now on, and will check before and after updates.
-
Hi. I wanted to give a heads-up to anyone experiencing this problem from time to time. Problem: My cache pool consists of 3 SSDs, 2 of which are fairly old (lived through 2 laptops), and I had a problem of one of the SSDs being disconnected mid pool operation, and errors starting to accumulate, until I reboot the system and run scrub. Suggested solution / investigation: Some forum posts suggested that the issue lies in the SSDs themselves, cables, or even the backplane of the motherboard. I swapped cables, tried 2 different PCIe - SATA adapters, nothing helped. Actual solution (in my specific case): TLDR - I bought and installed a UPS for the server. All the errors stopped appearing. Longer version - I noticed that my 3d printer sometimes had a horizontal shift in the prints in one of the directions. That's apparently a sign of a short power outage (possibly due to voltage fluctuations) - not so long that the printer would stop and force me to restart the print, but long enough for it to lose its position. I decided that losing my data because of a voltage spike would defeat the purpose of a NAS, so I bought a UPS (first one that I found that satisfied my wattage needs - APC Back UPS BX - BX950MI-GR - 950 VA). Errors didn't appear ever since, and as an added benefit - it has a battery, and UnRaid can safely shutdown in the event of power outage if you connect UPS to the server via USB.
-
Having this problem as well, 1.5 years later. What's weird, others started having this problem much earlier, and me only a month ago despite being up-to-date with latest UnRaid version, as well as nginx reverse proxy. Running through Cloudflare.






