




BOGLOAD
Members
-
Joined
-
Last visited
Everything posted by BOGLOAD
-
Has anybody here needed to delete their codecs folder every so often, sometimes a few times a month perhaps? The issue seems specific to EAC3, and I'm getting sick of stopping, deleting the Codecs folder, and restarting PMS. Noticed that playback just spins on clients, as if it's waiting to transcode, but nothing comes. Good old codec delete fixes this. I'm finding I'm doing it way too often.
-
My appdata share is set to Use cache pool: Only. Was running prefer, but found the pool @ 512gb was big enough. Disks definitely spin down after 15 minutes for me!
-
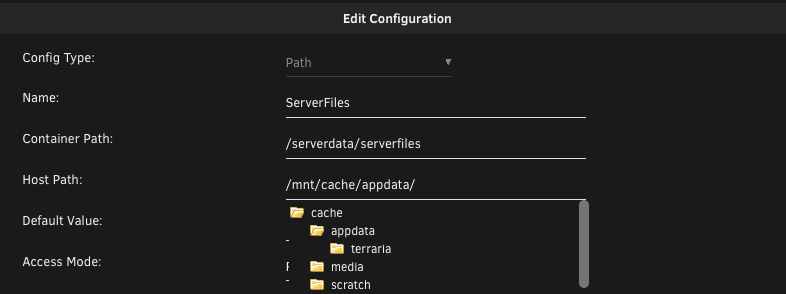
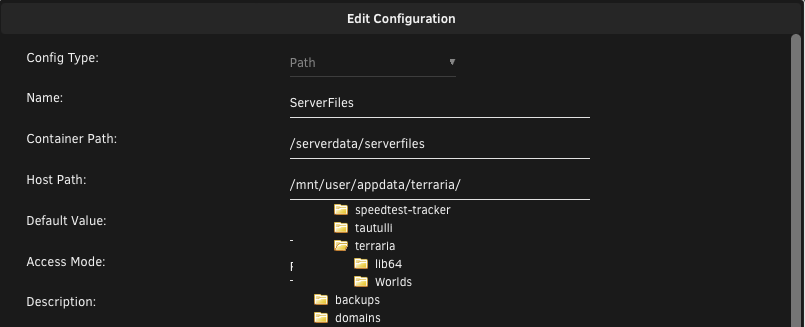
Thanks for testing it @ich777. I think I've managed to figure it out. For whatever reason, the default install was setting the "ServerFiles" path to /mnt/cache/appdata/ - had a look inside this folder, nothing there whatsoever. Changed it to /mnt/user/appdata/terraria/ instead: Everything now works perfectly fine! I have no idea why it wasn't defaulting there automatically. My world loaded up correctly, no issues shutting down/restarting/saving world progress it seems. Thanks again for testing on your side!
-
Hi @ich777 - sure thing, file is attached. Yes, a cache drive is installed (use it mainly as a downloading drive), called it 'CACHE' and it only holds my 'scratch' share. Created a separate cache pool called "Data" for my appdata share (running RAID1). The appdata share is set to Use Cache Pool: Only, and Select cache pool: Data. Nothing else is changed in the container template, just the version number of the server. bogland.wld
-
Hi all, struggling with getting Terraria server to load my existing world. It keeps spawning new worlds. Steps I've taken: 1. Installed docker image 2. Setup TERRARIA_SRV_V as 1.4.4.7 3. Started Docker image, stopped it. Deleted world.wld 4. Copied over my existing world.wld from PC 5. Restarted server. 6. Connected using latest Steam Terraria client, but new world is generated and not my existing seed. Stopping docker container generates world.wld.bak file in addition to my existing world.wld file. I've also tried renaming my world file to bog.wld and editing the name of the world in the serverconfig.txt file to match - no other parameters/paths were touched, just the physical filename.wld file. Upon reloading and connecting, it still generates a new world (and subsequently saves world.wld or world.wld.bak. Have tried a fresh docker reload after blowing away the appdata/terraria folder, and adding bog.wld + updating serverconfig.txt to refer to after stopping the new docker installer. Same problem, world not loading. Tearing my hair out, have I missed something? World was created in 2020, but as been saved multiple times obviously, and under latest 1.4.4.7 PC client.
-
That would probably be it. Thanks @JorgeB. Turns out my motherboard drops from 16x on the PCIE main slot when more devices are added down to 8x/4x/4x (my GPU is sitting in the 8x slot). This post here suggests the behaviour: Shame, might have to replace the actual motherboard to get an improvement.
-
Output here: root@Tower:~# lspci -d 1000: -vv 03:00.0 Serial Attached SCSI controller: Broadcom / LSI SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 02) Subsystem: Broadcom / LSI 9210-8i Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+ Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx- Latency: 0, Cache Line Size: 64 bytes Interrupt: pin A routed to IRQ 38 IOMMU group: 20 Region 0: I/O ports at e000 [size=256] Region 1: Memory at c0440000 (64-bit, non-prefetchable) [size=16K] Region 3: Memory at c0000000 (64-bit, non-prefetchable) [size=256K] Expansion ROM at <ignored> [disabled] Capabilities: [50] Power Management version 3 Flags: PMEClk- DSI- D1+ D2+ AuxCurrent=0mA PME(D0-,D1-,D2-,D3hot-,D3cold-) Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=0 PME- Capabilities: [68] Express (v2) Endpoint, MSI 00 DevCap: MaxPayload 4096 bytes, PhantFunc 0, Latency L0s <64ns, L1 <1us ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 0.000W DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq+ RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+ FLReset- MaxPayload 128 bytes, MaxReadReq 512 bytes DevSta: CorrErr- NonFatalErr- FatalErr- UnsupReq- AuxPwr- TransPend+ LnkCap: Port #0, Speed 5GT/s, Width x8, ASPM L0s, Exit Latency L0s <64ns ClockPM- Surprise- LLActRep- BwNot- ASPMOptComp- LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+ ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt- LnkSta: Speed 5GT/s (ok), Width x4 (downgraded) TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt- DevCap2: Completion Timeout: Range BC, TimeoutDis+ NROPrPrP- LTR- 10BitTagComp- 10BitTagReq- OBFF Not Supported, ExtFmt- EETLPPrefix- EmergencyPowerReduction Not Supported, EmergencyPowerReductionInit- FRS- TPHComp- ExtTPHComp- AtomicOpsCap: 32bit- 64bit- 128bitCAS- DevCtl2: Completion Timeout: 50us to 50ms, TimeoutDis- LTR- OBFF Disabled, AtomicOpsCtl: ReqEn- LnkCtl2: Target Link Speed: 5GT/s, EnterCompliance- SpeedDis- Transmit Margin: Normal Operating Range, EnterModifiedCompliance- ComplianceSOS- Compliance De-emphasis: -6dB LnkSta2: Current De-emphasis Level: -6dB, EqualizationComplete- EqualizationPhase1- EqualizationPhase2- EqualizationPhase3- LinkEqualizationRequest- Retimer- 2Retimers- CrosslinkRes: unsupported Capabilities: [d0] Vital Product Data pcilib: sysfs_read_vpd: read failed: No such device Not readable Capabilities: [a8] MSI: Enable- Count=1/1 Maskable- 64bit+ Address: 0000000000000000 Data: 0000 Capabilities: [c0] MSI-X: Enable+ Count=15 Masked- Vector table: BAR=1 offset=00002000 PBA: BAR=1 offset=00003800 Capabilities: [100 v1] Advanced Error Reporting UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- UnxCmplt- RxOF- MalfTLP- ECRC- UnsupReq- ACSViol- UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- UnxCmplt- RxOF+ MalfTLP+ ECRC- UnsupReq- ACSViol- CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr- CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- AdvNonFatalErr+ AERCap: First Error Pointer: 00, ECRCGenCap+ ECRCGenEn- ECRCChkCap+ ECRCChkEn- MultHdrRecCap- MultHdrRecEn- TLPPfxPres- HdrLogCap- HeaderLog: 00000000 00000000 00000000 00000000 Capabilities: [138 v1] Power Budgeting <?> Capabilities: [150 v1] Single Root I/O Virtualization (SR-IOV) IOVCap: Migration-, Interrupt Message Number: 000 IOVCtl: Enable- Migration- Interrupt- MSE- ARIHierarchy- IOVSta: Migration- Initial VFs: 16, Total VFs: 16, Number of VFs: 0, Function Dependency Link: 00 VF offset: 1, stride: 1, Device ID: 0072 Supported Page Size: 00000553, System Page Size: 00000001 Region 0: Memory at 00000000c0444000 (64-bit, non-prefetchable) Region 2: Memory at 00000000c0040000 (64-bit, non-prefetchable) VF Migration: offset: 00000000, BIR: 0 Capabilities: [190 v1] Alternative Routing-ID Interpretation (ARI) ARICap: MFVC- ACS-, Next Function: 0 ARICtl: MFVC- ACS-, Function Group: 0 Kernel driver in use: mpt3sas Kernel modules: mpt3sas root@Tower:~#
-
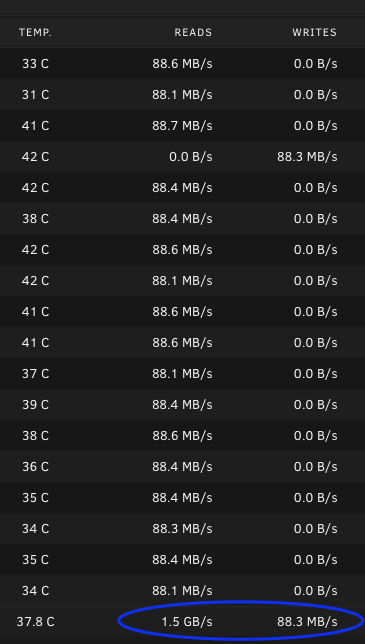
Hi all. I've recently decided to replace some ageing HDDs (some with many reallocated sectors, and some just smaller/slower drives). I've noticed that each time I replace a disk (or two max at a time), the parity rebuild read speed tops out at a collective 1.5GB/s. My current setup includes an LSI 9211-8i HBA connected to and a HP SAS Expander using both channels. Build is inside a Norco 4224 case, 5600x CPU, 32gb RAM, Gigabyte X570 UD board with 750W PSU. Research shows that SATA 6.0GB/s capable drives operate @ 3Gbps as a result of the HP SAS Expander's limitations, and this is consistent with what I'm seeing in the Disk Identity tab for all drives (i.e.: SATA 3.3, 6.0 Gb/s (current: 3.0 Gb/s)). All drives currently are 8tb <-> 12tb IronWolf flavour. I previously had 2x 8tb WD REDs that could only sync @ 1.5Gb/s, so I replaced them as I suspected it was a firmware issue of sorts and just couldn't be bothered diagnosing why. During a rebuild, these are the speeds I'm seeing: My question is, is this collective read speed normal and/or expected? Every time I've done this, read has collectively topped out @ 1.5GB/s. A rebuild of a 10tb drive is currently estimated to take 1 day, 7 hours (initial estimate). Similarly, write speeds are about 85-90MB/s for each drive I replace (160-180MB/s for 2 drives, still 1.5GB/s read speed). I've just got this nagging feeling that the current hardware setup may be limiting the read speeds somehow, possibly the write a little bit also (I've seen some say parity rebuild as fast as ~120 MB/s). FYI: I was considering replacing the HBA+SAS card with a single, 24 port HBA (something with 6x backplane support) to reduce cable clutter and improve speeds a little, but they're rather expensive right now. Any insight/commentary would be greatly appreciated, cheers
-
Absolutely. Rebuilt the array, and things have been fine since then. Double and triple checked all the 8TB drives - ran the commands again to ensure I did do just that. Haven't had any drop-offs in a few days, and I've tried rebooting/power cycling a few times to see if it happens again -- nothing for now. Hopefully this doesn't happen again! Got a 750w PSU here, not overly worried about using too much juice
-
I have experienced this on two drives this week running 6.10.3. Ran the tools/commands, even on my other 8tb drives that were 'fine'. Parity rebuilt, working fine. As of today, two more drives have been disabled (drives that I ran the commands on too). Not sure if I should move the 8tb drives on and replace with 10tb, or jump ship back to WD!



