




hermy65
Members
-
Joined
-
Last visited
Everything posted by hermy65
-
Ah, that may be my issue. My telegraf does not run as host so maybe thats why its not working?
-
@falconexe finally getting this setup and the main issue im running into so far is getting my UPS data to pull in. This is what my telegraf config looks like # # Monitor APC UPSes connected to apcupsd [[inputs.apcupsd]] # # A list of running apcupsd server to connect to. # # If not provided will default to tcp://127.0.0.1:3551 # servers = ["tcp://127.0.0.1:3551"] # # ## Timeout for dialing server. # timeout = "5s" Im guessing i need to fill out the ip of my unraid server here since im using the built in APC UPS daemon under Settings -> UPS but when i try that it says no route to hose. Im guessing i need to configure something but im not sure what. Perhaps i cannot use the built in APC UPS daemon in unraid?
-
@falconexe yeah man im still here, just trying to take in what you have done here so far. Probably going to start playing with what you have here tomorrow and see what we can accomplish here. Great work again!
-
@falconexe Looking good! are you planning on releasing your dashboards once you are satisfied with them?
-
@falconexe Nice find - let us know if it works for you!
-
@falconexe / @KoNeko Perhaps we can push this idea towards one of the plugin devs here and they can make something like it or integrate it into an existing plugin they offer?
-
Not necessarily a support question but not sure where else to put this. Is there a plugin/app of some sort that we can install in unRAID that will allow us to visualize our storage usage over time? Perhaps it would show how much additional storage we are using per month, etc? Per month storage burn might be helpful in determining when you need to get additional drives ,etc. Also, it could show you if there was a deletion of data or something of that sort as your usage would drop, etc?
-
@johnnie.black I guess im not following. Are you saying what i did earlier caused the issue?
-
@johnnie.black I followed your steps but when i re-add the drives and start the array i get an error that says: Cache drive unmountable, no pool uuid. I tried the btrfs restore steps listed here and was able to recover data from the two drives in my original screenshot that were in unassigned devices but when i try it on the two disks that were listed in the pool in my original picture i get the error in the attached image.
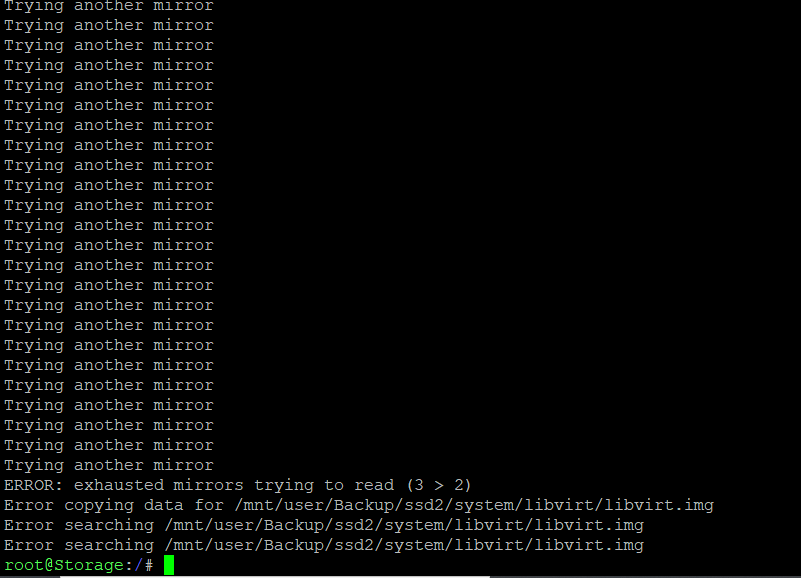
-
@John_M It was RAID 1. I checked the cables and they all seem solid. I added the two drives back into the pool and started the array but now im getting this.
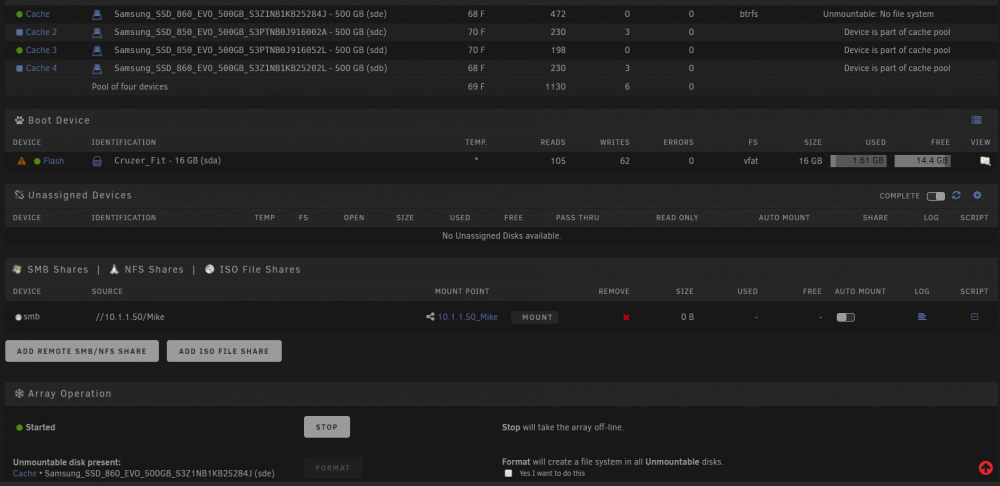
-
@John_M so do I just add them back into the cache pool then? Will I lose any data?
-
I moved my server to a new location, fired it up and for some reason 2 of my cache drives are now showing up in unassigned devices. If i add them i assume it rebuilds them but do i lose any data? Whats the best way to handle this so i dont lose anything on my cache drive? Also, why would this happen?
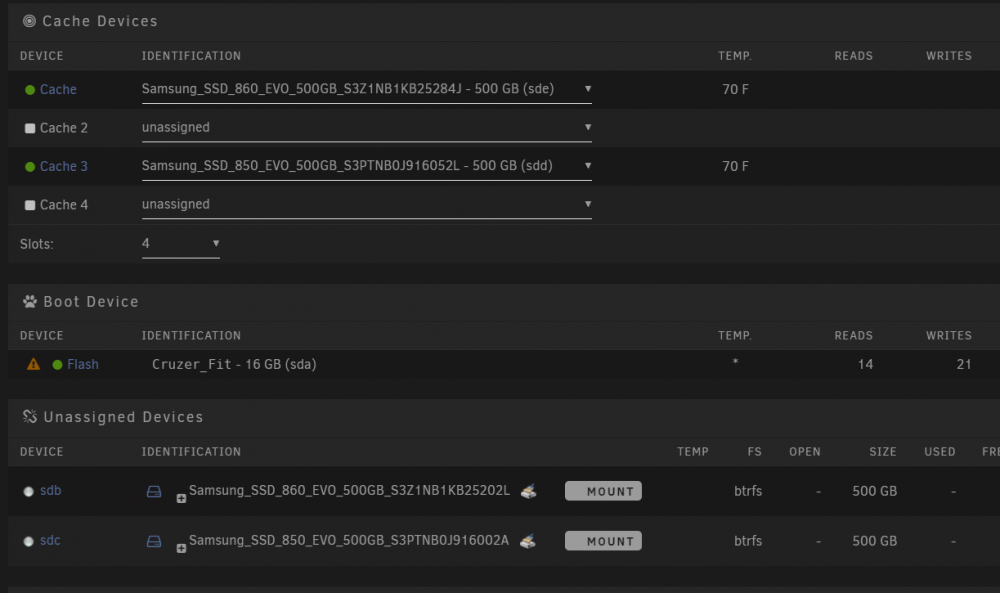
-
Having issues with mylar as of recently so i posted an issue on their github and this is what the dev said: Cannot find /usr/lib/python2.7/site-packages/requests/__init__.py:91: RequestsDependencyWarning: urllib3 (1.25) or chardet (3.0.4) doesn't match a supported version!
-
Ive got an issue that i cant resolve, hopefully you guys can tell me what dumb thing i did/did not do. I have a handful of kodi boxes up and running pointing at a SQL database. I decided to setup this headless container to handle library updates but im running into an issue. All i did was setup the advancedsettings to point at the database then point sonarr at it but it doesnt update the library. In the kodi log file it says: 17:58:37.621 T:22745948530432 WARNING: Process directory 'smb://ip/folder/name of show' does not exist - skipping scan. These folders all exist but kodi headless doesnt appear to be able to see them. What can i do to get this up and running?
-
I have not restarted in a while, will do that and see what happens.
-
Im getting emails from letsencrypt about my certs expiring soon, do i need to do anything or does it take care of it on its own?
-
Question for everyone. I have been using this plugin for a while but completely missed the setting that allows you to ignore specific file extensions and now when it runs the verification task my .nfo's are almost always flagged as having been modified. Whats my best course of action to prevent getting that every time it runs? Is there a way to remove the hash from a specific file type in batches?
-
I ran into an interesting issue that hopefully i can get some insight on. I added a smb share in unassigned devices and mounted it, then i installed duplicati and had the destination folder be the newly mapped smb share. I started the backup procedure but after ~5 minutes of it running duplicati itself goes unresponsive. I cannot access the webgui, i cannot stop/restart the container and docker in general appears to only be partially functional afterwards. If i try to stop the array it never actually stops because the duplicati container wont stop. If i end up getting it rebooted and the array back online then as soon as duplicati runs again the same situation happens. Any ideas?
-
Ok, will try that and see what happens.
-
Im getting a weird issue here an am running out of ideas. I ran my first backup last week and the backup completed successfully however my linuxserver/mariadb container refused to function and nothing that used that container would work either. I ended up having to remove the databases and then move the backed up files back to the appdata folder and then mariadb started functioning normally again. I assumed it was something to do with the backup so i excluded it at that point. Last night the backup ran again and mariadb was not backed up as intended, however the same issue persists where the container wont function and nothing can connect to it. I assume it has something to do with the way this plugin is stopping containers or updating them or something. Any ideas?
-
Is there any way to leverage this plugin or maybe some other solution to notify you if files that already have checksums are missing? Use case: Im 99% positive i moved all of our baby pictures to the server weeks ago and yet today i cannot find them anywhere. Maybe i accidentally deleted them somehow or some other magic happened. Basically im looking for something that can tell me if something that was there is no longer there anymore.
-
I was doing a large restore yesterday and at some point my server locked up completely so i had to power it off. Today when i went tried to connect back to Crashplan to continue the restore i get this message when i go to the link in the log - http://Storage:4280/vnc.html?host=Storage&port=4280 noVNC ready: native WebSockets, canvas rendering Is that how we are supposed to be accessing Crashplan or are there better ways?
-
Maybe i missed this while searching this thread so apologies in advance. I was using CrashPlan while on unRAID v5 and just updated to the newest beta. I installed the CrashPlan container and pointed the config folder to the folder i had been using on 5 and it doesnt pick up where it left off, it makes me sign in again and start over. Is there anyway to just switch from plugin to container and keep everything going as it was without having to set everything back up?



