




hermy65
Members
-
Joined
-
Last visited
Everything posted by hermy65
-
Any chance anyone can help me with some samesite/sameorigin issues im having with swag+organizr? I was able to use the chrome flags when they were available to get things working, then they removed the flags so i resorted to a registry tweak but that no longer works for me either. I would like to get this fixed once and for all so i can continue to use things. Right now i have everything going through swag using a name.domain.com format. If i use local ips for organizr + the organizr tabs use local ips i get the attached image when i inspect the tab. If i go through my reverse proxy with organizr.domain.com and all the tabs using service.domain.com i get the same thing. How do i resolve this once and for all?

-
Either i have done a good job of not getting dupes/samples in my library OR i cannot figure out how to get this working. My UI looks exactly like the post below, ive disabled SSL with the variable of 1 but still get nothing. Logs do not show anything interesting either.
-
@Roxedus it has that functionality built in now? Can you give me some more info on it as i must have missed that?
-
Can anybody point me in the right direction with radarrsync? I have been using it for maybe a year and it has been working without issue and then all of a sudden today i notice that there are things that should have been synced but were not. I opened up the logs and see this: Traceback (most recent call last): File "/RadarrSync.py", line 86, in <module> searchid.append(int(r.json()['id'])) TypeError: list indices must be integers or slices, not str From what i can tell is that its a profile ID issue but for the life of me i cannot figure out how to determine the profile ID. I assumed i just counted the profiles but for some reason in my config i have 5 whereas in radarr(s) my 4k is the 6th one listed, if i change the config to 6 i no longer get an error but nothing syncs over either. Nothing in the radarrsync logs or radarr logs that i can find either. Any insight?
-
dammit...i read those like 11 times before i made any posts because i didnt want to be that guy. My apologies
-
Boom - good to go now. Did i miss something that said that needed to be there? Appreciate the help
-
Nothing under Show More Settings
-
/bin/sh -c 'apk update && apk upgrade && apk add ipmitool && apk add smartmontools && telegraf'Interesting, never saw mention of it working locally. I ran all the commands you gave but never got a result from any of them. Here is what my telegraf config looks like in the [[inputs.diskio]] section # Read metrics about disk IO by device [[inputs.diskio]] ## By default, telegraf will gather stats for all devices including ## disk partitions. ## Setting devices will restrict the stats to the specified devices. # devices = ["sda", "sdb"] ## Uncomment the following line if you need disk serial numbers. # skip_serial_number = false # ## On systems which support it, device metadata can be added in the form of ## tags. ## Currently only Linux is supported via udev properties. You can view ## available properties for a device by running: ## 'udevadm info -q property -n /dev/sda' device_tags = ["ID_SERIAL"] # ## Using the same metadata source as device_tags, you can also customize the ## name of the device via templates. ## The 'name_templates' parameter is a list of templates to try and apply to ## the device. The template may contain variables in the form of '$PROPERTY' or ## '${PROPERTY}'. The first template which does not contain any variables not ## present for the device is used as the device name tag. ## The typical use case is for LVM volumes, to get the VG/LV name instead of ## the near-meaningless DM-0 name. # name_templates = ["$ID_FS_LABEL","$DM_VG_NAME/$DM_LV_NAME"]@GilbN Would rather not expose my db to the internet but if i need to i can to use your link above. I did run the command via console and got the result below which makes me assume its not pulling serial data but that wouldnt explain why the drives arent visible in the top bar of the dashboard (i assume):
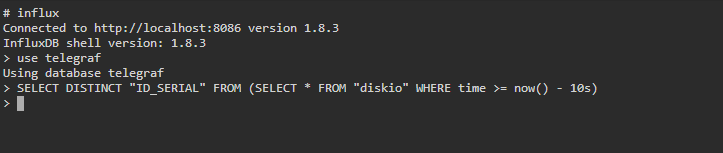 @falconexe @GilbN Well, maybe we found an issue? There is data under diskio but im not seeing any serials
@falconexe @GilbN Well, maybe we found an issue? There is data under diskio but im not seeing any serials
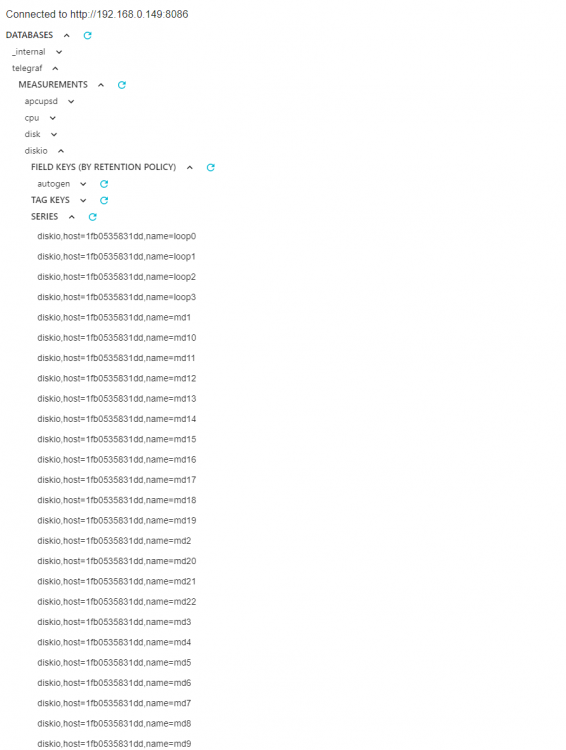 @GilbN which command am i supposed to be running? Didnt see it mentioned unless i missed something.Yeah i changed it back to the variable after posting that image. Still no luck though unfortunately...time to start it all on fire i guessYeah thats how i had it setup originally with my datasource at the top and everything as your last screenshot shows. Attaching the image i put on my first post again, in case i missed something.
@GilbN which command am i supposed to be running? Didnt see it mentioned unless i missed something.Yeah i changed it back to the variable after posting that image. Still no luck though unfortunately...time to start it all on fire i guessYeah thats how i had it setup originally with my datasource at the top and everything as your last screenshot shows. Attaching the image i put on my first post again, in case i missed something. I already had that enabled, and my disks do show up in the bottom panel in the smart health section but im guessing that doesnt tell us if diskio is working.
I already had that enabled, and my disks do show up in the bottom panel in the smart health section but im guessing that doesnt tell us if diskio is working.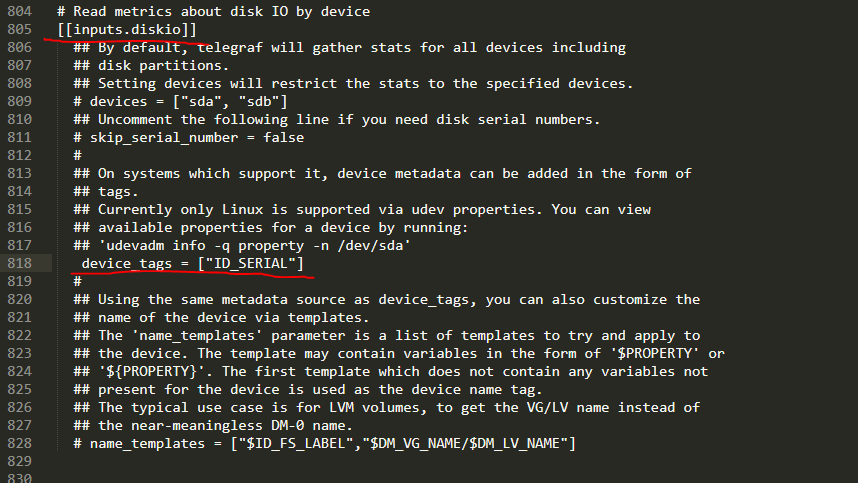 So i went through and i *assume* i updated it correctly but still no go after clearing cache, etc.
So i went through and i *assume* i updated it correctly but still no go after clearing cache, etc.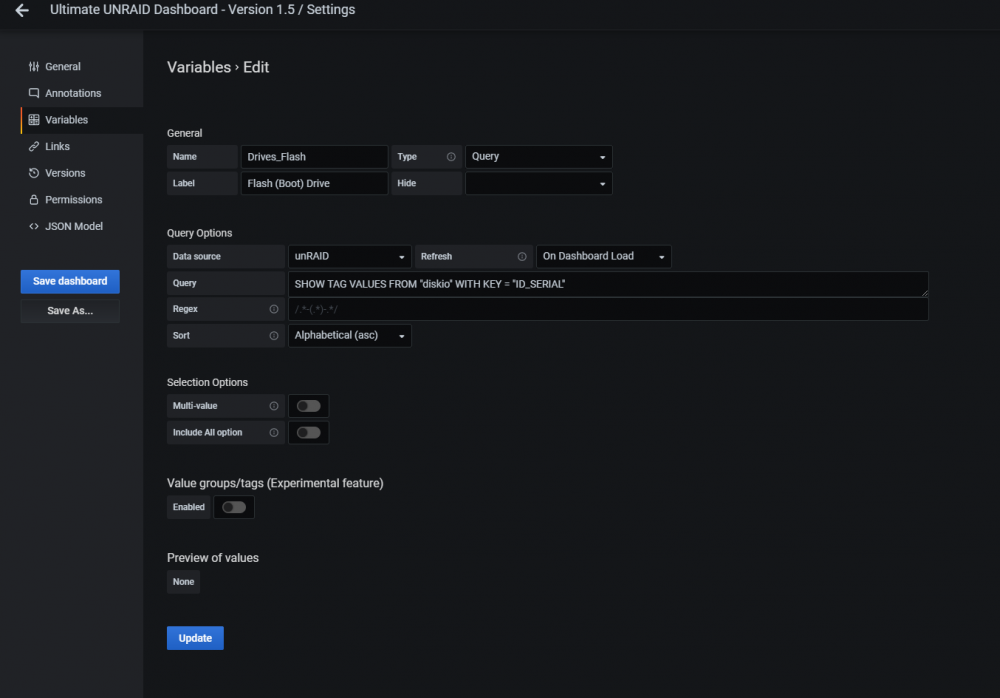 @falconexe Looking good my man! I just bumped from 1.2 to 1.5 and am running into an issue that im hoping you can point me in the correct direction on. In 1.5 im not able to select any drives at the top of the dashboard (Flash (Boot) Drives, Cache Drive(s), etc). On 1.2 and 1.5 all of my disks, serials, etc pull through towards the bottom of the dashboard but im not able to select anything at the top. Anything i should be looking for to try to figure this one out?
@falconexe Looking good my man! I just bumped from 1.2 to 1.5 and am running into an issue that im hoping you can point me in the correct direction on. In 1.5 im not able to select any drives at the top of the dashboard (Flash (Boot) Drives, Cache Drive(s), etc). On 1.2 and 1.5 all of my disks, serials, etc pull through towards the bottom of the dashboard but im not able to select anything at the top. Anything i should be looking for to try to figure this one out? If there is, im unable to find it.Perhaps mine does not have modbus support, cant seem to find it in any menu.@GilbN https://www.apc.com/shop/us/en/products/APC-Smart-UPS-C-1500VA-LCD-120V-Not-for-sale-in-Vermont-/P-SMC1500@GilbN here is what mine shows
If there is, im unable to find it.Perhaps mine does not have modbus support, cant seem to find it in any menu.@GilbN https://www.apc.com/shop/us/en/products/APC-Smart-UPS-C-1500VA-LCD-120V-Not-for-sale-in-Vermont-/P-SMC1500@GilbN here is what mine shows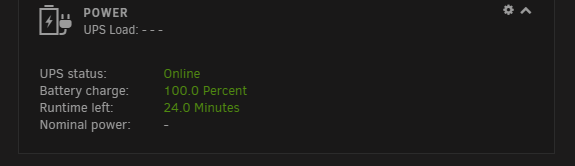 @GilbN I get nothing when i run that
@GilbN I get nothing when i run that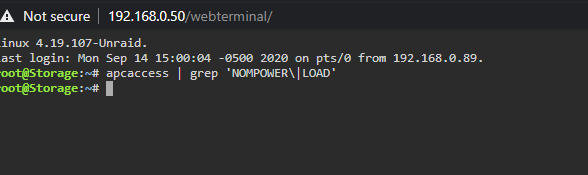 @falconexe i have my server ip configured in the apcupsd section of the telgraf config as shown # # Monitor APC UPSes connected to apcupsd [[inputs.apcupsd]] # # A list of running apcupsd server to connect to. # # If not provided will default to tcp://127.0.0.1:3551 servers = ["tcp://192.168.0.50:3551"] # # ## Timeout for dialing server. # timeout = "5s" Maybe @GilbN has a little insight since he mentioned he is using the built in apc ups daemon as well.@GilbN @falconexe - OK i moved my telegraf to host and its pulling in *some* UPS data but not all of it, also noticing some strange things with the array growth and the TX/RX numbers on my eth0 interface. in #1 - my UPS stats are not all populating. Im using the APC UPS Daemon thats built into unraid if that matters. in #2 - my annual array growth is less than my weekly/monthly in #3 -randomly i will get massive numbers on this panel, i assume its just something weird on my end but thought i would bring it to your attention. Also, random question, is there a way to convert the CPU temps to Farenheit?
@falconexe i have my server ip configured in the apcupsd section of the telgraf config as shown # # Monitor APC UPSes connected to apcupsd [[inputs.apcupsd]] # # A list of running apcupsd server to connect to. # # If not provided will default to tcp://127.0.0.1:3551 servers = ["tcp://192.168.0.50:3551"] # # ## Timeout for dialing server. # timeout = "5s" Maybe @GilbN has a little insight since he mentioned he is using the built in apc ups daemon as well.@GilbN @falconexe - OK i moved my telegraf to host and its pulling in *some* UPS data but not all of it, also noticing some strange things with the array growth and the TX/RX numbers on my eth0 interface. in #1 - my UPS stats are not all populating. Im using the APC UPS Daemon thats built into unraid if that matters. in #2 - my annual array growth is less than my weekly/monthly in #3 -randomly i will get massive numbers on this panel, i assume its just something weird on my end but thought i would bring it to your attention. Also, random question, is there a way to convert the CPU temps to Farenheit?
















