





-C-
Members
-
Joined
-
Last visited
Everything posted by -C-
-
Have had NC working on Unraid for the last 10 months without too many issues. Now trying to get v28 working. It was initially stuck in maintenance mode, but when I manually took it out of that via CLI, it would load up OK, but the admin status page would show the error "Your web server is not yet properly set up to allow file synchronisation, because the WebDAV interface seems to be broken." Not turning up anything of use by searching for that error. I've updated my appdata/nextcloud/www/nextcloud/config/config.php based on the latest config.sample.php file and I'm still getting the same error. Here's my config.php - anything wrong/ missing from here, or other ideas of what could be causing the problem? <?php $CONFIG = [ 'instanceid' => '****', 'passwordsalt' => '****', 'secret' => '****', 'trusted_domains' => [ '192.168.3.4:3443', 'server.com' ], 'datadirectory' => '/data', 'version' => '28.0.1.1', 'dbtype' => 'mysql', 'dbhost' => '192.168.3.3:3306', 'dbname' => 'nextcloud', 'dbuser' => 'nextcloud', 'dbpassword' => '****', 'dbtableprefix' => 'oc_', 'installed' => true, 'default_language' => 'en_GB', 'force_language' => 'en_GB', 'default_locale' => 'en_GB', 'default_phone_region' => 'GB', 'force_locale' => 'en_GB', 'default_timezone' => 'Europe/London', 'mail_domain' => 'server.com', 'mail_from_address' => '****', 'mail_smtpmode' => 'smtp', 'mail_smtphost' => 'smtp.server.com', 'mail_smtpport' => 465, 'mail_smtpauth' => true, 'mail_smtpsecure' => 'ssl', 'mail_smtpname' => '[email protected]', 'mail_smtppassword' => '****', 'mail_sendmailmode' => 'smtp', 'overwritehost' => 'server.com', 'overwriteprotocol' => 'https', 'bulkupload.enabled' => false, 'maintenance' => false, 'loglevel' => 0, 'theme' => '', 'filelocking.enabled' => 'true', 'memcache.locking' => '\\OC\\Memcache\\APCu', 'memories.exiftool' => '/config/www/nextcloud/apps/memories/bin-ext/exiftool-amd64-musl', 'memories.vod.path' => '/config/www/nextcloud/apps/memories/bin-ext/go-vod-amd64', 'memories.vod.ffmpeg' => '/usr/bin/ffmpeg', 'memories.vod.ffprobe' => '/usr/bin/ffprobe', 'updater.secret' => '****', 'upgrade.disable-web' => true, ];
-
I'm seeing this for the disk There are no SMART errors. Is it worth trying a different SATA cable, or is there no way it's a cabling issue if it's syncing at 6 Gb/s?

-
As I had hoped/ assumed, which begs the question- what else could be causing this?
-
In July I added a new 18TB Toshiba MG09ACA18TE. I was pleased with its speed- as good as, if not better than the 20TB WD drives I have, which were pretty speedy. Since then, any array operations have felt painfully slow. With 20TB parity drives, the last parity check took over 4 days and the one that's currently running is estimated to take over 5 days. It's fluctuating between 35 & 100 MB/sec. Diskspeed docker is showing that its speed is now less than half of what it was when first installed: The most recent test (Nov 15) was made with all other Docker apps disabled and the VM service off. Speeds of the other disks have remained stable. Only thing I can think that happened between the Jul & Sep tests is that I cleared the drive and formatted it as ZFS- could that have had this affect? If so, is there anything I can do about it?
.thumb.png.d764cb4e3003119463d8caf45ecccce3.png)
-
This looks like it'd be super useful for me, but I've had no luck trying to get it up and running. Before I try the 2.1 version as above, wondering whether there's been any advances on getting the latest versions working in the last 6 months.
-
I have some services that automatically save files into a few Dropbox directories. I'm looking for a way to auto-download just these directories to my Unraid for safe keeping. I see there a number of Dropbox compatible Docker apps, but not sure which would suit my purpose best. Any recommendations/ advice most appreciated.
-
Did someone say bar? Great idea!
-
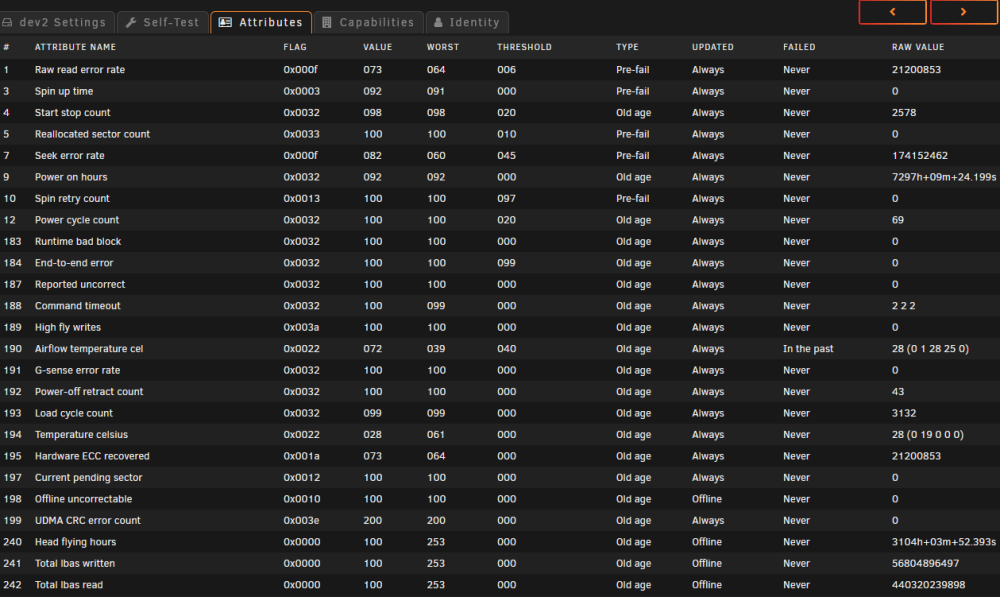
Having read about people having array drives come up as unavailable due to power issues, or other temporary issue, and turn out to be fine, I figured I'd stick the failed drive in a USB caddy, just to see if there were any signs of life. It's come up as fine, passed quick SMART test. So it may well have been a power glitch or something and a reboot would have fixed it. Not sure whether I should try to use this drive any more, in case there is something up with it. Here's its attributes: I can browse it and access files no problem. Is there any way to put this back into the array with its data intact, or am I better off copying the data onto the disk that's now in the array? So a few lessons learned here- triple read and have a good think about anything array related when there's any possibility of data being lost, and always try turning it off and on again!
-
Makes me feel slightly less dumb if someone else has done the same thing! Good luck, I hope you can put that disk in, but I'll leave that to someone more knowledgeable.
-
I took that as a standard "formatting will remove all data on this disk" type warning. I didn't think any of that was relevant to what I was doing- I had an empty disk with no data on it to worry about. To me "...will normally lead to loss of all data on the disk being formatted" is about losing any data on the disk being added, it doesn't mention anything about a different format breaking the rebuild process.
-
Thanks Jorge, I followed the official guide here: https://docs.unraid.net/unraid-os/manual/storage-management/#replacing-faileddisabled-disks I had missed the point in the notes there "The rebuild process can never be used to change the format of a disk - it can only rebuild to the existing format." I wasn't using the process to change the format, it was to replace a failed drive, so I skipped over this point. Then when it came to adding the new disk, I figured that as I was having to format the disk anyway, i might as well switch to ZFS so I can take advantage of some of its benefits over XFS like replication from cache etc. Now that I think about how parity works, I realise that there was no way it could have worked with a different format type. It was my mistake. This was the first time I rebuilt a disk from parity, so it was all new to me. Fortunately, none of the data on that disk was irreplaceable and I have a backup of most of it. I do think that there should be a bigger warning about this in the manual to make it clearer that a change of format will stop the rebuild from being able to work. Especially now that I'd imagine there are others like me who'd like to take advantage of ZFS since 6.12 and may be tempted to do what I did. Even better would be if there's a way for the system to check whether you're trying to rebuild onto a disk with a different format than the one being replaced when attempting to start a rebuild and give a nice clear data loss warning.
-
Thanks Jorge Here they are: syslog-192.168.34.43.log.2.7z The disk died around 7:20 on 1/9 tower-diagnostics-20230918-1104.zip
-
I had some troubles during the rebuild and had to restart the server, but the rebuild appeared to complete successfully: Any idea what could have caused this? This is the first time a disk died without warning and I've needed to use parity. I'm assuming the data from the failed drive's gone. Fortunately, I have most of it backed up. I am using syslog to save the logs, so should have logs of everything if they're of use.

-
What about linking the banner to Tools > Update OS, at least as an interim solution?
-
Certainly possible. The system wasn't happy when I rebooted it (which was the reason for the reboot) and it may have killed hung processes in order to reboot. It certainly took longer than usual. (I used powerdown -r to restart in case that makes any difference.)
-
In which case I'm stuck in a loop, for now- I rebooted the first time it happened and everything was stable for a day or so before it happened again, without a reason I can find. What's painful is that the rebuild is happening slowly- when I could last access the GUI I was getting around 10-30 MB/s, so I'll likely be stuck without a GUI for another day at least. I've not had a disk fail without warning before, so not had to rebuild from parity like this and am not sure whether that's normal. It's certainly running a lot slower than a correcting check. That's what happened when I rebooted part way through the rebuild yesterday. Not sure if that's normal though. I've disabled mover as the rebuild was stopping for the daily move and not restarting afterwards.
-
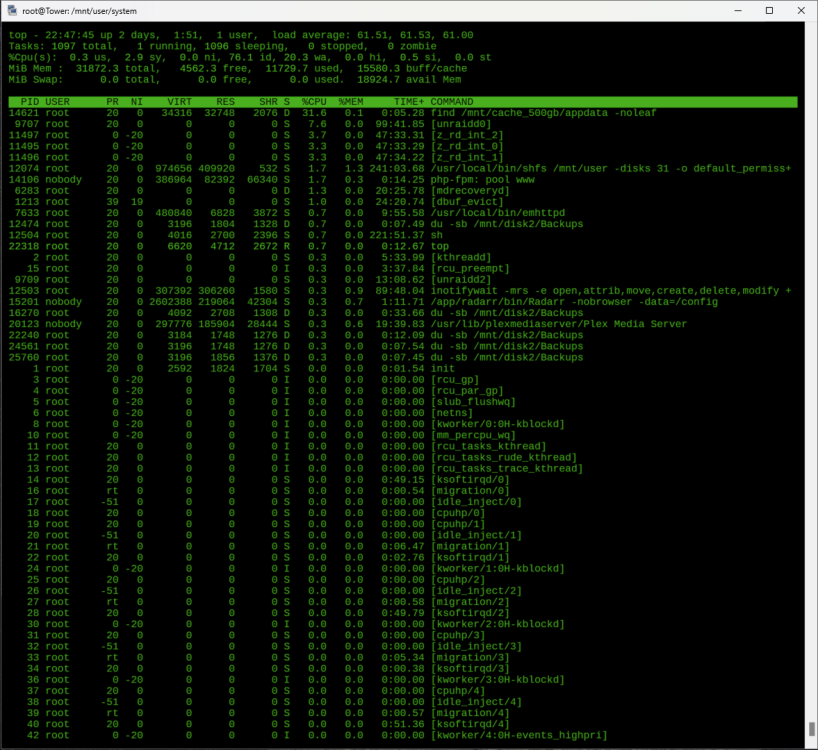
Just tried logging into the Unraid GUI and am now getting a Load is pegged again: top - 12:24:40 up 1 day, 12:32, 1 user, load average: 52.86, 52.47, 52.31 Tasks: 1152 total, 1 running, 1151 sleeping, 0 stopped, 0 zombie %Cpu(s): 2.9 us, 5.2 sy, 0.0 ni, 82.7 id, 9.1 wa, 0.0 hi, 0.1 si, 0.0 st MiB Mem : 31872.3 total, 6157.1 free, 12252.2 used, 13463.0 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 18476.1 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 11805 root 20 0 975184 412108 516 S 93.7 1.3 158:06.42 /usr/local/bin/shfs /mnt/user -disks 31 -o default_permissions,allow_other,noatime -o remember=0 29298 nobody 20 0 226844 109888 32124 S 22.5 0.3 12:33.84 /usr/lib/plexmediaserver/Plex Media Server 12138 nobody 20 0 386324 70936 55404 S 6.0 0.2 0:00.28 php-fpm: pool www 9015 root 20 0 0 0 0 S 4.3 0.0 137:11.80 [unraidd0] 13271 nobody 20 0 386216 65896 50496 S 4.3 0.2 0:00.16 php-fpm: pool www 22798 nobody 20 0 386744 79348 63384 S 4.3 0.2 0:17.22 php-fpm: pool www 7495 root 20 0 0 0 0 D 1.0 0.0 26:23.74 [mdrecoveryd] Here's a list of installed plugins: root@Tower:~# ls /var/log/plugins/ Python3.plg@ dynamix.cache.dirs.plg@ dynamix.system.temp.plg@ open.files.plg@ unRAIDServer.plg@ zfs.master.plg@ appdata.backup.plg@ dynamix.file.integrity.plg@ dynamix.unraid.net.plg@ parity.check.tuning.plg@ unassigned.devices-plus.plg@ community.applications.plg@ dynamix.file.manager.plg@ file.activity.plg@ qnap-ec.plg@ unassigned.devices.plg@ disklocation-master.plg@ dynamix.s3.sleep.plg@ fix.common.problems.plg@ tips.and.tweaks.plg@ unbalance.plg@ dynamix.active.streams.plg@ dynamix.system.autofan.plg@ intel-gpu-top.plg@ unRAID6-Sanoid.plg@ user.scripts.plg@ I can access files on the array OK over the network, rebuild is still running, albeit very slowly: root@Tower:~# parity.check status Status: Parity Sync/Data Rebuild (65.2% completed) Any advice on what I can try to get the load back down?

-
Load is still climbing: load average: 57.57, 57.49, 57.00 Looks like it could be related Docker: root@Tower:/mnt/user/system# umount /var/lib/docker umount: /var/lib/docker: target is busy. Parity rebuild seems to be going much slower than it should be, guess it's due to the high load. So I ran parity.check stop after doing so the GUI's now loading fine, but I'm getting a "Retry unmounting user share(s)" in the GUI footer. I tried a reboot but it's hung. Via SSH I tried stopping Docker service, but it doesn't seem to be that: root@Tower:/mnt/disks# umount /var/lib/docker umount: /var/lib/docker: not mounted. I left it (wasn't sure what else to try) and eventually it restarted and things seem to be back to normal. I've now discovered that the Parity Tuning plugin doesn't/ can't continue a Parity Sync/Data Rebuild in the same way that it can a correcting parity check, so it's back to the beginning with that. I'm going to avoid touching anything until the rebuild's finished.
-
I checked the logs and found the crash happened around here: Sep 3 17:00:54 Tower webGUI: Successful login user root from 192.168.34.42 Sep 3 17:01:25 Tower php-fpm[7836]: [WARNING] [pool www] server reached max_children setting (50), consider raising it Doing some further digging on that error, I found this post: In which the poster found the issue was due to the GPU Statistics plugin. I had just installed that a couple of days ago, so it would seem that this is likely the cause of my problem too. I successfully removed the plugin via CLI with plugin remove gpustat.plg ...but after a few minutes the sys load remains high and still no GUI. Looking like a reboot's my only option, but Status: Parity Sync/Data Rebuild (65.3% completed)
-
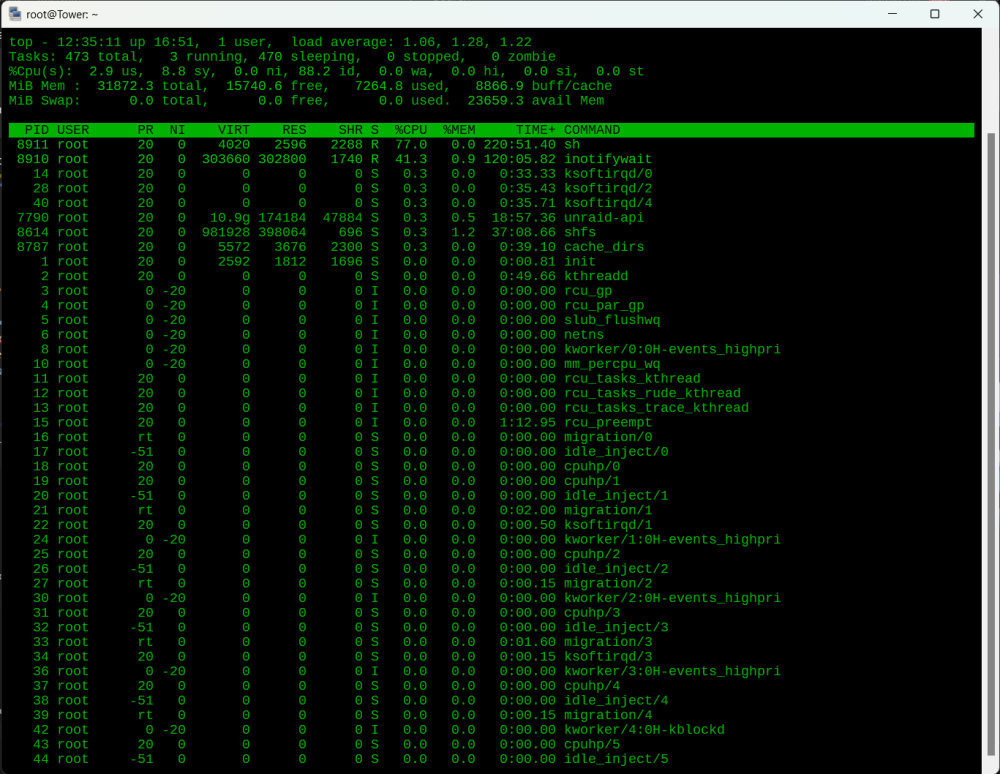
I was updating some docker containers through the Docker GUI page when the page froze. Checked top via SSH and got this: top - 17:58:46 up 1 day, 21:02, 1 user, load average: 53.92, 53.54, 53.07 Tasks: 1107 total, 3 running, 1104 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.9 us, 2.6 sy, 0.0 ni, 54.9 id, 41.4 wa, 0.0 hi, 0.2 si, 0.0 st MiB Mem : 31872.3 total, 5800.0 free, 11092.2 used, 14980.1 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 19566.8 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24398 root 20 0 34316 32632 1960 R 21.5 0.1 0:05.21 find 12074 root 20 0 974656 409920 532 S 10.9 1.3 215:55.56 shfs 18749 nobody 20 0 455592 102776 80756 S 5.3 0.3 0:02.04 php-fpm82 21905 nobody 20 0 386252 77244 61756 R 4.6 0.2 0:00.31 php-fpm82 18604 nobody 20 0 455788 105656 83604 S 4.0 0.3 0:02.86 php-fpm82 11495 root 0 -20 0 0 0 S 3.3 0.0 41:37.86 z_rd_int_0 11496 root 0 -20 0 0 0 S 3.3 0.0 41:39.55 z_rd_int_1 11497 root 0 -20 0 0 0 S 3.3 0.0 41:38.24 z_rd_int_2 7491 nobody 20 0 2711124 259320 24452 S 1.7 0.8 0:11.99 mariadbd Thing is, I'm part way through an array rebuild having replaced a failed HDD. Usually I would restart the server if the GUI becomes snafu, but in this case, is it safe to do so? (I have the Parity Check Tuning plugin installed) or is there a CLI command I can try to bring things back?
-
Thanks for the super useful plugin. There's a typo on its settings page: Datasets Datasets Exclussion Patterns (Just One!): should be Datasets Datasets Exclusion Patterns (Just One!):
-
I ran a large unBALANCE transfer and, typically, it all went without a hitch. Not sure why it took so long, but it completed successfully and when finished the Unraid GUI was still running fine. Will continue to monitor the situation and will post if things go awry again.

-
Thanks for checking the diags- I have some more moving to do and will be sure to post the logs. Interesting. I've not been able to find another example of someone having the same issue, so somewhat reassuring to know I'm (possibly) not the only one. Then again, this was happening when I first started using Unraid last year (6.11.3). I didn't upgrade until the 6.12 releases came out and have kept up to date since then. Unfortunately the problem has persisted across all of the versions I've been on.
-
I'm moving files around so I can start making use of ZFS. This issue has been going on for most of this year, but I've rarely needed to move large amounts of data around so haven't spent much time on troubleshooting. I started doing large moves using rsync via CLI and had problems, so moved to unBALANCE as it gives better visibility of what's going on. The crashing appears to be the same when I use either method. I find that the move completes correctly, but the main Unraid GUI becomes unreachable after a while. So for example, the whole move may take 5 hours, but the GUI becomes unreachable after 2 hours. If I try to connect with the "Array - Unraid Monitor" Android app while the GUI's borked, it displays a "Sever error" message. When the Unraid GUI is down, the unBALANCE GUI is not affected and still runs fine. I created the attached diagnostics while unBALANCE was running. It was a 172GB move, took nearly 50 mins and completed successfully. This is what top looked like while the GUI was crashed after an earlier, larger move. This was many hours after the move had finished. No dockers or VMs running: tower-diagnostics-20230820-1400.zip
-
Thanks to whoever's responsible for the Nicotine+ container. I tried a few times over the years to get it running on Windows and never had any joy. It fired straight up on my Unraid 6.12.2 and all looks good. Couple of things I noticed:- Main thing is with the download folders specified in the template. I have them both set to reference subfolders within my /mnt/user/Audio/ share, but the files weren't being saved to those dirs. I eventually found that they were being saved, but in the container's config/.local/share/nicotine/downloads directory. I fixed this by going into the Nicotine+ prefs/ downloads and changing the Incomplete and completed to the container's dirs as specified by default in the template. I also had to go to prefs/ Shares and manually add the container's shares folder that was specified by default. On the template- both descriptions for the complete and incomplete downloads are the same. In Prefs, in User Interface the "Prefer dark mode" selection is being ignored.


.png.496cbb436595faa6c86e46fd71a395d5.png)







