



nedpool
Members
-
Joined
-
Last visited
-
Is there another thread for feature requests or do we post those here? There are a bunch of 'passive income' templates being added to the CA store (mainly from one person, using affiliate links for the app support) and while I'm not here to discuss the validity of these apps, they are pretty clearly a cashgrab and most likely a scam to the detriment of those that install them. If these templates are to be allowed in the CA store, then can we get options to block templates or to block publishers from view? A voting system for templates would be great, too, so the community can voice their opinion on the app listings (rather than folks spending hours on the forums).
-
I understand that these templates may not be technically breaking any rules, but they are pretty clearly a cashgrab taking advantage of folks that don't know any better. Any 'passive income' scheme like this is certainly a scam. If the templates are to be allowed on the CA store, then at least let us filter out / block items and vote on templates to somehow let others know the opinion of the community (without having to spend hours on the forums).
-
I'm having the same issue as other users here.. the IP isn't getting bound correctly. The port mapping section in the docker list is blank and the logs clearly show: url: http://localhost:3000 even though I've changed the container IP and the NEXTAUTH_URL address. Due to the mac-vlan issues on Unraid, I only use static IPs on containers, so unless the IP bindings can be fixed, I simply can't use this. Which is a shame.. I'd really like to migrate off Raindrop.
-
For the Huginn template, can we get access to use our own .env file instead of entering all 30+ variables in Unraid? I tried mapping to /app/.env, but it won't start and I can't get logs for it. Thank you for all your work on these apps/templates!
-
Huh... 30+ containers and this is the first one I've wanted to change the port on since assigning IPs to everything. I don't know how I missed that bit on docker networking, but thanks!
-
nedpool changed their profile photo
-
No, I'm assigning an IP to the container on a dedicated interface.
-
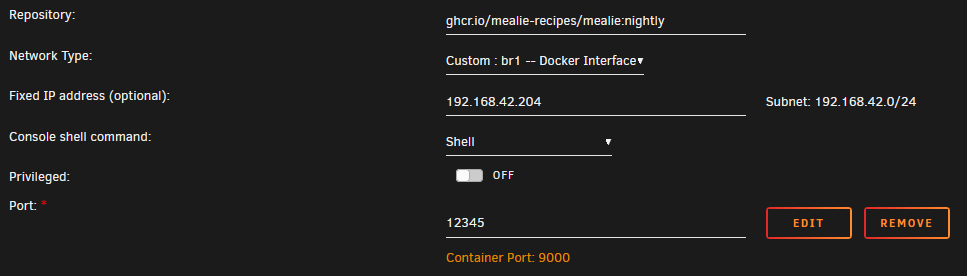
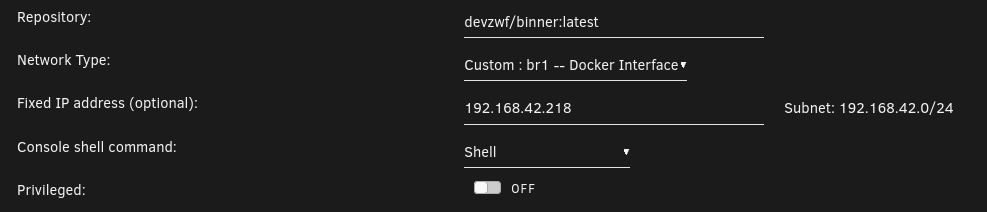
Can this template be updated? Currently, if you specify an IP address for the container, it doesn't apply. Only using the Bridge interface works, but I no longer trust it since the MAC issues with lockups. Thank you!
-
OK, on the current template; now the container port is completely ignored. I cannot change it from 9000.
-
Oh.. my bad.. I had the old repository image (hkotel/mealie), which I guess is no longer updated and no notification that it was no longer supported. Even though I changed repos last year to hit v1 (and lost my db in the process). Having to change repos now 3 times in total... if the repo changes again or a 'new' image pops up on the store, I just give up. This is too much work just to try and stay up to date on the same app.
-
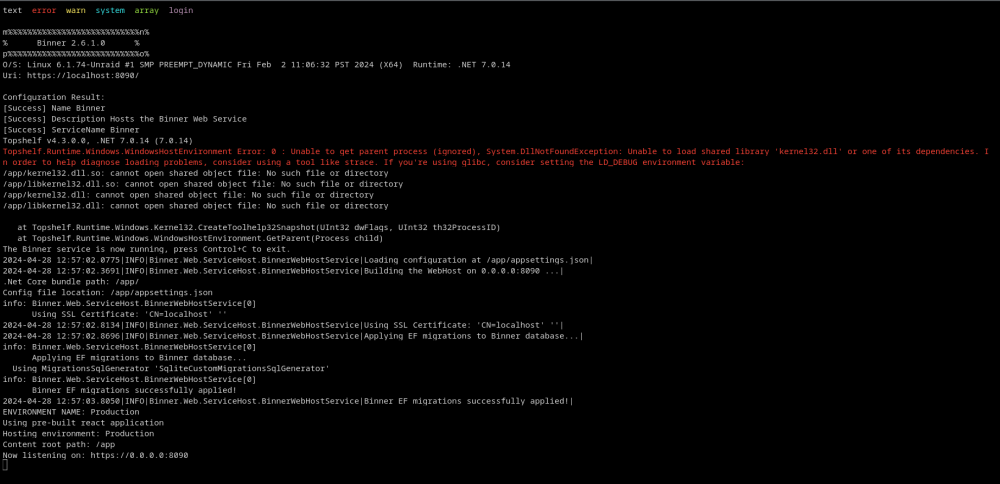
Does this image not adhere or recognize the OIDC configuration variables, as noted in the backend config docs? I'm trying to use my Keycloak backend for auth, but none of the OIDC vars are loading from my Unraid config. Nothing noted in the logs, no OIDC login button on the login page, no redirecting (with OIDC_AUTO_REDIRECT: True).
-
Follow up: The original 6TB must have failed spectacularly; I could only salvage ~50GB of 4.5TB of data that was on the drive and the same junk got sync'd to the new drive. btrfs check (--repair) could not repair the partition on the new drive. Ended up just formatting the new drive and accepting the loss of the media (98% replaceable). I now have a properly configured docker directory on the ssd pool due this ordeal, as well. Some lessons learned and hopefully a better system. Thanks for the help!
-
Gotcha. That definitely explains it. As nice as it would be to automatically repair in such a situation, I completely understand the reasoning for not doing so and I should not have assumed it would.
-
Thanks, I had seen that entry in the FAQ but was hoping it didn't come down to that and thought there would be a root cause for the issue that could be resolved. At least I have the 2nd replacement drive to act as a temp store for this. I'm curious, though, what's the likelihood of this happening on a data rebuild in unRAID? This was only the second rebuild so far (first was upgrading disk 1). Is this just a coin flip of risk with btrfs or with unRAID in general? Or are there additional steps in a disk upgrade/replacement that aren't documented? I didn't see anywhere specifying to create a filesystem on the new disk going in after preclear, so I didn't, assuming that was part of the rebuild process behind the scenes. Could that have contributed to this issue? Is there anything I do to prevent this from happening?
-
Thanks for the quick response trurl! I am quite sure the disk was failing; it is a ~5yr old HGST that has been in multiple server iterations and started throwing read errors in the week leading up to the replacement. The last scheduled scrub failed due to errors. As for the connections, I have also swapped a few older SATA cables with new ones during the replacement and have tried swapping cables/ports for this new 14TB drive, but it is the only one having this unmountable issue. For clarity, here is the drive config for the main array: Parity 1 - WD Gold 14TB Disk 1 - Seagate X14 14TB Disk 2 - Seagate X16 14TB (new, unmountable) Disk 3 - HGST 6TB I also have a second X16 14TB to replace the other HGST 6TB soon as it is the same age and use as the one that just failed. Sorry I forgot to attach diags on the main post; attached here. Thank you! knowhere-diagnostics-20230319-0837.zip
-
Hrm... So I had a disk fail (disk2 - 6TB); physically installed the new disk (14TB) in an open tray, leaving the 6TB attached (array is down), and cleared the new 14TB. I then replaced the 6TB in the disk2 entry for the array with the new 14TB and started the data rebuild. Seems normal. Rebuild finishes, but new 14TB disk2 is now reading "Unmountable: Wrong or no file system", yet shows btrfs as the FS for the entry. I've searched every sequence of terms I can think of, but can't seem to find anything covering this particular sequence of events. What really worries me is that after the data rebuild has finished, my docker img file is still not found (since I didn't configure that correctly to be on my ssd pool for containers at the start). I have NOT done the "Format all unmountable disks" on the array page. Have I lost data in this rebuild or is there something I'm missing to get this disk online correctly?




