




MagicLegend
Members
-
Joined
-
Hi! I believe that I manually just used mv to move files around, I didn't actually invoke the mover (since it wasn't moving data).
-
I guess that's fair enough, although I'd rather see the privacy policy updated to allow sending important communications like this (and yes, you can have a debate about what's "important" then, it's a slippery slope). Given the price changes of the upgrades of the grandfather tier (kudos for still allowing that though!) it is something that I would've expected to be notified about as a customer of your software. Or at least be present on the current pricing page. Not something that I had to stumble upon under the `more` section of your website.
-
I happened to stumble across this by luck now because I saw it in the "more" section of the header as latest news. I have wondered from time to time when this change would come, since reality is that the current/old model is not sustainable. As I understand there will be a timeframe of one week in which I can decide to upgrade my licence for the old price: Will an email go out to all licence owners to notify us of the new pricing in that week? As a normal human being I don't have the time to follow blogs of all the services I use, and I think an email notification would be appropriate. Honestly I think a note on https://unraid.net/pricing or even within Unraid itself (although I guess some users would complain about that...) would also be appropriate. I'll have to consider picking up a second Basic key in case I ever build a second backup system then 😄 Edit: I see that trial customers will be emailed, I think all customers should be emailed:
-
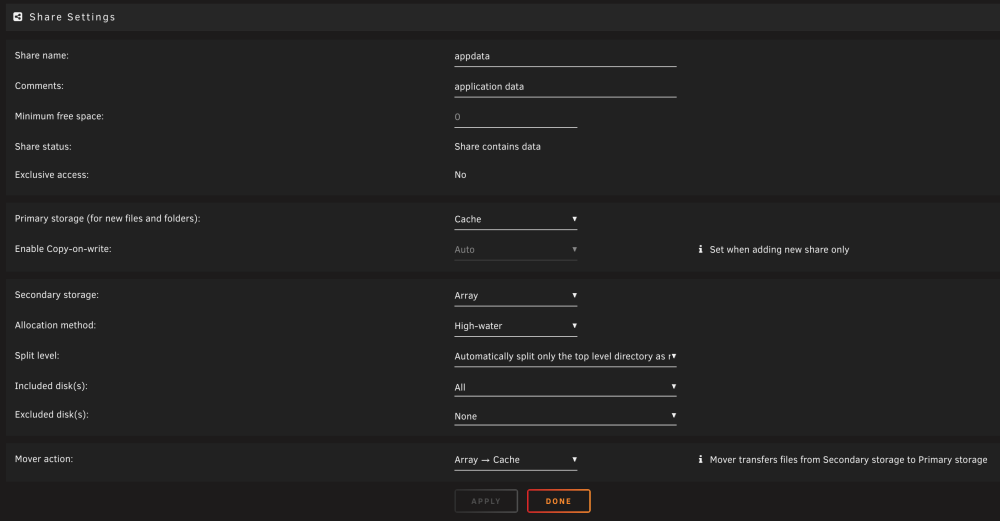
Ah yeah, the manager is enabled but no VM's are actively configured (only one in cold storage that the VM manager doesn't know about). Hmm, you are correct (obviously). I see some Jellyfin data is on disk2, but it's the only appdata that is on disk2. Weird, since the appdata share is configured to move from the array to pool. Could this simply be because I have the array configured as secondary storage? I'm assuming these settings are in the diagnostics somewhere as well, but if not: The jellyfin data: <user>@<machine>:~# ls -lhat /mnt/disk2/appdata total 0 drwxrwxrwx 14 nobody users 268 Jan 19 21:12 ../ drwxr-xr-x 3 nobody users 30 Aug 31 21:34 jellyfin/ drwxrwxrwx 3 nobody users 30 Aug 31 20:29 ./ <user>@<machine>:~# ls -lhat /mnt/disk2/appdata/jellyfin/jellyfin/ total 0 drwxr-xr-x 3 nobody users 30 Aug 31 21:34 ../ drwxr-xr-x 6 nobody users 74 Aug 31 20:32 ./ drwxr-xr-x 7 nobody users 103 Aug 31 20:29 data/ drwxr-xr-x 4 nobody users 44 Aug 31 20:29 dlna/ drwxr-xr-x 2 nobody users 10 Aug 31 20:29 log/ drwxr-xr-x 2 nobody users 10 Aug 31 20:29 cache/
-
Hmm, I don't think so? I don't use VM's to be clear (I only have a quad code in there thanks to Intel, so I'm bound to local VM's for now), so only Docker is of concern for me. New diagnostics are attached! Thanks! tower-diagnostics-20240119-2239.zip
-
Ah yeah, of course. Forgot it was renamed. I've gotten it all back up and running again. Seems like the radarr database was the only thing that ended up corrupted in my appdata backup during all of this. Could be worse! For others; I followed the docs on reformatting the cache drive: https://docs.unraid.net/unraid-os/manual/storage-management/#reformatting-a-cache-drive For me the mover was not moving anything that was left on the cache, so I did it manually over SSH. I had a backup of the appdata already using CABackup. Keep in mind that by default it only saves 7 backups, and if you're short on time to fix this (like me) then keep in mind that it might overwrite your previous backups from when everything was working. Thank you both!
-
Thank you so much! Wanted to add that this also works while using ZeroTier by simply adding your ZeroTier network to it. In case anyone reading ZeroTier is reading this; you might also be running into what is described here if you're on Unraid >6.12.x and you can't access any service in Docker through ZeroTier.
-
Ah yeah, you are totally right. Didn't know that was an option in Unraid Thanks for the pointer, will definitely configure that once I get it back up and running!
-
Hi Jorge, Thanks for taking a look. What would make it that the entire array would be corrupt, and not just the cache disk here? Formatting just the cache disk would be a lot simpler than having to find a temporary location for those terrabytes Thanks again!
-
MagicLegend changed their profile photo
-
Hi! I have been dealing with a cache disk that is misbehaving. I have already taken the following diagnostic steps: - Extended SMART report: passed - Memtest86+: passed - Investigated log files myself with a lot of googeling: no definitive result I guess I have a similar issue to this post: I know I've had issues with the cache filling up completely, due to the Arr stack trying to download faster than the mover could keep up with. However, in those scenarios the docker containers would simply freeze, I'd kick the mover and it would all come back to life after a few minutes. In this scenario, the cache disk is not full at all. Somehow after running memtest the cache was writable, and I was able to recreate the docker image slightly larger than before (30GB instead of the old 25GB, it was time again). However, right after this operation the cache locked itself again to read only. I do have a backup of the old docker image on the array. I have attached diagnostics of both today, right after doing a reboot (so everything is fresh, apologies for the cleared syslog), and from a while ago when I was last investigating the issue. If any additional diagnostics are needed, please let me know. I would also love to know how I could've found the exact issue myself, would be great if some pointers could be given to what I missed in my searches 🙂 Thanks for ya'lls time! tower-diagnostics-20240116-1909.zip tower-diagnostics-20240103-1224.zip
-
Hi Dmitry, I noticed that your repository the Unraid template is based on is now a public archive; are you continuing to maintain the template? --- I have some issues using Time Machine through ZeroTier. I have your container running, and next to it I have mbentley/timemachine to arrange my time machine needs. It has been set up nearly identically to the post you can find here. Now, when I'm in the same network as my Unraid server, TIme Machine works fine. But when I try to do it externally via ZeroTier, my Mac can't find `timemachine.local`. I'm assuming this has something to do with that the time machine container is set to the `br0` network and ZeroTier is set to the `host` network. I can't put the Time Machine container on the `host` network, since there already is an SMB server there that's screaming out the local domain name with mDNS, and putting the ZeroTier container on `br0` makes it so ZeroTier doesn't function properly. Any tips or tricks on what magic I have to pull to get it to behave? Thanks for your effort!

