




daninet
Members
-
Joined
-
Last visited
-
Hi, Every 1-2 days the container stops with java error. It runs perfectly fine for a while which is strange. My flag is 11notes/unifi:9.3.43-unraid I see this is log: {"time":"2025-07-29T16:37:12.000Z","type":"INF","msg":"starting unifi v9.3.43"} # # A fatal error has been detected by the Java Runtime Environment: # # [thread 32927 also had an error] SIGBUS (0x7) at pc=0x000014ae728192de, pid=1, tid=111 # # JRE version: OpenJDK Runtime Environment (17.0.15+6) (build 17.0.15+6-Ubuntu-0ubuntu120.04) # Java VM: OpenJDK 64-Bit Server VM (17.0.15+6-Ubuntu-0ubuntu120.04, mixed mode, sharing, tiered, compressed oops, compressed class ptrs, parallel gc, linux-amd64) # Problematic frame: # V [libjvm.so+0xc192de] ObjectMonitor::EnterI(JavaThread*)+0x27e # # No core dump will be written. Core dumps have been disabled. To enable core dumping, try "ulimit -c unlimited" before starting Java again # # An error report file with more information is saved as: # /usr/lib/unifi/hs_err_pid1.log # # If you would like to submit a bug report, please visit: # https://bugs.launchpad.net/ubuntu/+source/openjdk-17 # [error occurred during error reporting (), id 0xb, SIGSEGV (0xb) at pc=0x000014ae7316d941] {"time":"2025-08-02T08:17:44.000Z","type":"INF","msg":"starting unifi v9.3.43"} # # A fatal error has been detected by the Java Runtime Environment: # # SIGBUS (0x7) at pc=0x000015360d47d412, pid=1, tid=30 # # JRE version: OpenJDK Runtime Environment (17.0.15+6) (build 17.0.15+6-Ubuntu-0ubuntu120.04) # Java VM: OpenJDK 64-Bit Server VM (17.0.15+6-Ubuntu-0ubuntu120.04, mixed mode, sharing, tiered, compressed oops, compressed class ptrs, parallel gc, linux-amd64) # Problematic frame: # V [libjvm.so+0xc7d412] PerfLongVariant::sample()+0x22 # # No core dump will be written. Core dumps have been disabled. To enable core dumping, try "ulimit -c unlimited" before starting Java again # # An error report file with more information is saved as: # /usr/lib/unifi/hs_err_pid1.log # # If you would like to submit a bug report, please visit: # https://bugs.launchpad.net/ubuntu/+source/openjdk-17 # [error occurred during error reporting (), id 0xb, SIGSEGV (0xb) at pc=0x000015360dda7941]I have attached the file from the container that the error log refers to. hs_err_pid1.log
-
I feel like it is actually slow not just underreporting. Anyway, what alternative i can use while on phone? MC is very hard to manage on touch screen, total commander SMB plugin does not seem to bypass when copying from share to share. I'm looking for gui option here just to be on the same page but i guess its clear 🙂
-
Im using linux so i dont have that fancy graph windows explorer has but the copy speed is indeed ok. So is this an issue with Dynamix File Manager?
-
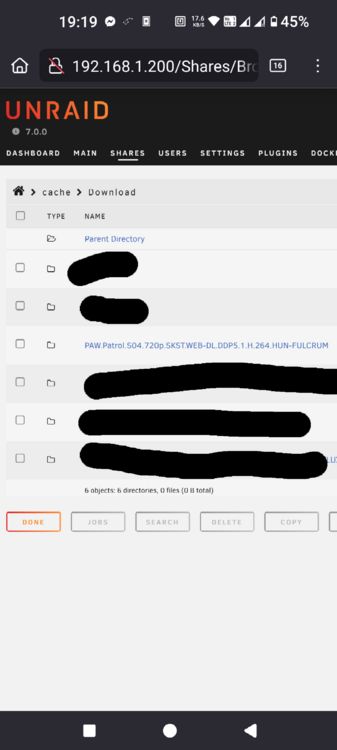
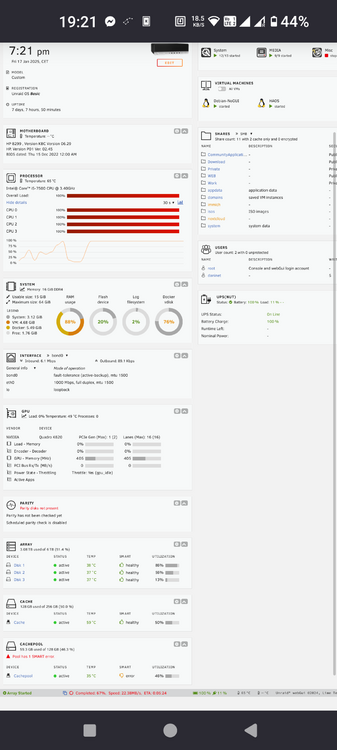
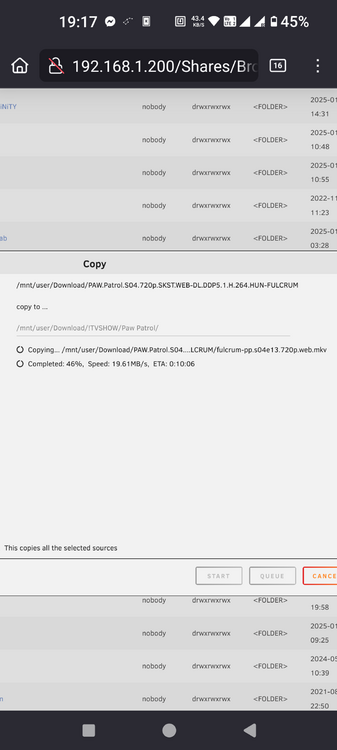
Hello, As title says I have issues with copy speed. It tops out at 20-25Mb/s. I'm initiating the copy over the web interface so it should not be limited by any network speed. Files are around 1Gb so it is sequential writing to the HDD. I have WD Red 2Tb drives and Samsung nvme SSD for cache. File is cached, mover not yet run. While copy is running dashboard shows high CPU usage. Not sure if it includes iowait. Once copy over CPU usage goes back to normal idle. Diagnostics made during copy operation. Any help about what to check appreciated. Thanks tevenas-diagnostics-20250117-1924.zip
-
indeed when im stopping docker service it looks good. My only new docker in the setup is immich. The rest of my dockers are running for years no issue. I will test the setup now without immich, I already have all my images indexed and the thumbnails generated im not sure why it should be an issue
-
Hello! I recently did some upgrades on my system, I added more ram, added a new disk, added a new ssd (this one only stores immich thumbnails). Now with this combination something happened to my server any I'm getting 100% CPU usage a lot. It is so bad that I need 2-3minutes just to ssh into my server. htop and docker stats show very weird things, processes are fighting for CPU cycles. For example when did you see htop process itself uses 45% CPU last time? Then I see lsof on top a lot, then qemu and docker service as well. Basically anything I invoke on the interface goes up with high CPU usage and very hard to tell what exactly is throttling my cpu. In docker stats every container randomly goes between 0-20% CPU usage even the inactive ones like mysql for my websites that I'm not using. Very weird. Everything still works, I can access my dockers, access my server but it is super slow. Crazy slow. The config is HP Elitedesk PC with i5-7500 and 16Gb RAM. I also have an older nvidia card for plex encoding. I have attached the diagnostics, any help appreciated. tevenas-diagnostics-20250110-0944.zip
-
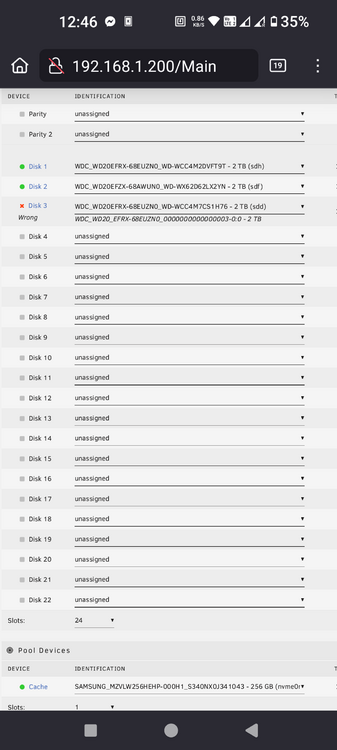
Circling back to my original question from the first post, can i somehow replace the IDs so i dont have to copy all my data somewhere to redo the array? I dont have that much free space.
-
Here you go. The IDs are same as my first screenshot in the post, IDs are not changing. tevenas-diagnostics-hotplug.zip tevenas-diagnostics-normal-boot.zip
-
Hi, I recently acquired an icy box usb jbod. I have a microserver and while i'm aware rebuilding it in a new case with sata card and such would be a better option, at the moment i cannot justify the price. It would mean a brand new server for me. So i'm using it for now and honestly i dont have much complaint with it. Speed is fine for media and downloads. It holds no irreplaceable data. The issue is i didnt know unraid handles is weirdly when i set it up. So right now it has a single drive. My server was running, i have stopped the array, plugged in the usb, added the new disk to the array and was happy. Until i had to restart the server and I noticed that the drive is not mounted, it said missing. Unplug, replug usb and I was able to select the drive and start the array. But the issue is my server is now unable to start automatically I have to babysit it. What I noticed is when I start unraid os with the usb jbod plugged in it gets a very normal looking HDD serial number, however when you hot plug it in while the os is running it gets a very generic 00000003 serial. Obviously i should have done the first option then i would have no trouble but here I am. So..: Now I need to know how I can replace a disk while content is 100% the same but different serial. I know it might be a weird edge case but it happens as you see. I dont have parity drive, its a media server.

-
Hi! I have a GreenCell Micropower 1500VA UPS and it was working great with for quite some time with the blaze usb driver. However something happened and the battery charge percentage no longer updates. This results in my system not shutting down gracefully upon power outage. I can see the UPS load and the battery voltage indicator still updating. If someone can look on it please do. Thank you. nut-debug-20241219105328.zip nut-ups.dev
-
Hi, I'm using this container for some time without much issue. Where I live I have internet access with CGNAT only so I dont have my own IP. I'm using cloudflare tunnel to access my nextcloud instance running on my server. CF provides me an SSL so all good. However when I'm trying to access locally through IP I cannot, connection not secure. My localhost and domain is added to the config. 'trusted_domains' => array ( 0 => '192.168.1.200:8666', 1 => 'mydomain.xyz', ), 'trusted_proxies' => array ( 0 => '77.221.43.251', 1 => '172.17.0.6', 2 => '192.168.1.200', ), 'overwriteprotocol' => 'https', 'overwrite.cli.url' => 'http://192.168.1.200:8666', I want to know if there is some easy to understand description on how to attach certificate to the container and config it to be used by the container even locally. Unfortunately most of the help in this topic is to setup reverse proxy like traefik or swag and add certificate there but its not an option for me as far as I can understand or it would just add extra complexity for little to no benefit.
-
Seems like it worked. I'm left with this error now: WARN Unable to load properties from '/usr/lib/unifi/data/system.properties' - /usr/lib/unifi/data/system.properties (No such file or directory) {"time":"2024-12-02T19:53:49.000Z","type":"INF","msg":"starting unifi (8.5.6)"} quick search in this thread told me it might be something related to ports, but i get the same error on br0 and Bridge as well 🤔
-
daninet changed their profile photo
-
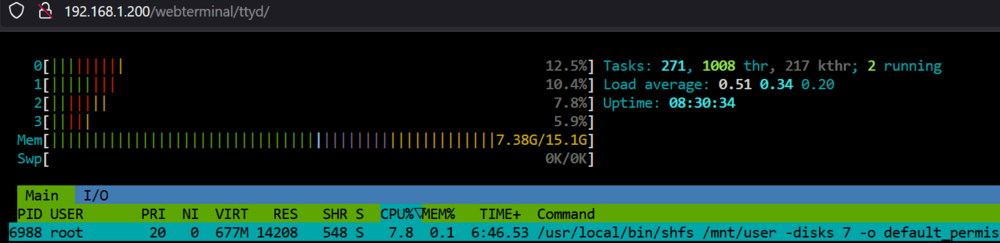
I have the default settings, same as yours: Here is my docker run: docker run -d --name='unifi-controller-reborn' --net='bridge' --pids-limit 2048 --privileged=true -e TZ="Europe/Budapest" -e HOST_OS="Unraid" -e HOST_HOSTNAME="TEVENAS" -e HOST_CONTAINERNAME="unifi-controller-reborn" -e 'MEM_LIMIT'='4096' -e 'MEM_STARTUP'='2048' -e 'UMASK'='002' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='https://[IP]:[PORT:8443]' -l net.unraid.docker.icon='https://user-images.githubusercontent.com/11403137/277435263-1b01facd-1b15-4ba7-9495-e709c291d67f.jpg' -p '8443:8443/tcp' -p '3478:3478/udp' -p '10001:10001/udp' -p '8080:8080/tcp' -p '1900:1900/udp' -p '8843:8843/tcp' -p '8880:8880/tcp' -p '6789:6789/tcp' -p '5514:5514/udp' -v '/mnt/user/appdata/unifi-controller-reborn':'/unifi/var':'rw' --memory=8G '11notes/unifi:8.5.6-unraid' WARNING: Your kernel does not support swap limit capabilities or the cgroup is not mounted. Memory limited without swap. 61e179a0b46c22815a0f4fb9bb7ec9f41d686715348634ca6f838bc01e168dec The command finished successfully! I'm assuming the last warning is default as unraid does not have swap. Memory is limited to user memory, I have 7.4Gb free in this system. htop:
-
I updated to the latest stable 6.12.14 yesterday. I used to have mongoDB coz the linuxserver unifi controller needs mongoDB to work. But I no longer have that container nor the content of the appdata folder. That is past time.
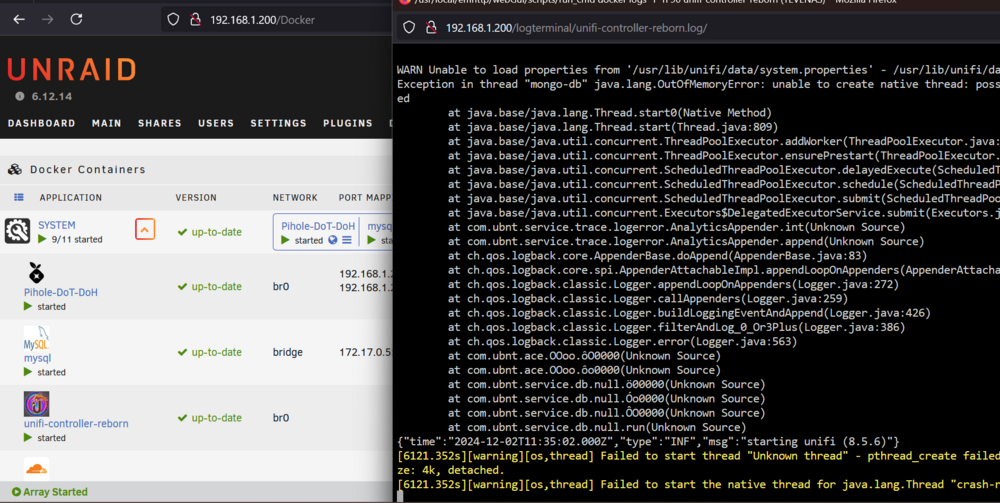
-
Hello, I have issues getting this docker running after updating my unraid OS. I have the unifi backup, I have wiped the appdata so it is considered a new installation. Version: 11notes/unifi:8.5.6-unraid All ports and docker settings are default. I have tried with bridge (i dont have any clashing ports) as well on br0 with dedicated IP. This is the error I'm getting when running it on bridge: WARN Unable to load properties from '/usr/lib/unifi/data/system.properties' - /usr/lib/unifi/data/system.properties (No such file or directory) Exception in thread "mongo-db" java.lang.OutOfMemoryError: unable to create native thread: possibly out of memory or process/resource limits reached at java.base/java.lang.Thread.start0(Native Method) at java.base/java.lang.Thread.start(Thread.java:809) at java.base/java.util.concurrent.ThreadPoolExecutor.addWorker(ThreadPoolExecutor.java:945) at java.base/java.util.concurrent.ThreadPoolExecutor.ensurePrestart(ThreadPoolExecutor.java:1593) at java.base/java.util.concurrent.ScheduledThreadPoolExecutor.delayedExecute(ScheduledThreadPoolExecutor.java:346) at java.base/java.util.concurrent.ScheduledThreadPoolExecutor.schedule(ScheduledThreadPoolExecutor.java:562) at java.base/java.util.concurrent.ScheduledThreadPoolExecutor.submit(ScheduledThreadPoolExecutor.java:715) at java.base/java.util.concurrent.Executors$DelegatedExecutorService.submit(Executors.java:748) at com.ubnt.service.trace.logerror.AnalyticsAppender.int(Unknown Source) at com.ubnt.service.trace.logerror.AnalyticsAppender.append(Unknown Source) at ch.qos.logback.core.AppenderBase.doAppend(AppenderBase.java:83) at ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:51) at ch.qos.logback.classic.Logger.appendLoopOnAppenders(Logger.java:272) at ch.qos.logback.classic.Logger.callAppenders(Logger.java:259) at ch.qos.logback.classic.Logger.buildLoggingEventAndAppend(Logger.java:426) at ch.qos.logback.classic.Logger.filterAndLog_0_Or3Plus(Logger.java:386) at ch.qos.logback.classic.Logger.error(Logger.java:563) at com.ubnt.ace.OOoo.ôO0000(Unknown Source) at com.ubnt.ace.OOoo.ôo0000(Unknown Source) at com.ubnt.service.db.null.ö00000(Unknown Source) at com.ubnt.service.db.null.Óo0000(Unknown Source) at com.ubnt.service.db.null.ÔO0000(Unknown Source) at com.ubnt.service.db.null.run(Unknown Source) WARN Unable to load properties from '/usr/lib/unifi/data/system.properties' - /usr/lib/unifi/data/system.properties (No such file or directory) WARN Unable to load properties from '/usr/lib/unifi/data/system.properties' - /usr/lib/unifi/data/system.properties (No such file or directory) {"time":"2024-12-02T07:44:33.000Z","type":"INF","msg":"starting unifi (8.5.6)"} [6116.156s][warning][os,thread] Failed to start thread "Unknown thread" - pthread_create failed (EAGAIN) for attributes: stacksize: 1024k, guardsize: 4k, detached. [6116.157s][warning][os,thread] Failed to start the native thread for java.lang.Thread "crash-reporter" When running it on br0 I only get the first line of the above warning. Regarding the memory warning I have about 16Gb free RAM and the docker image has space also. Any help appreciated.







