lory995
Members
-
Joined
-
Last visited
-
Jorge i'm grateful for your answer but... Is there really no other way? i got 50 docker, even if i got it in the first half, then i have to split it in half again and again, and considering it takes between 1 and 2 weeks on average for the problem to show itself, it becomes a life quest.... And that strange docker log is normal?
-
As per title, suddendly after a variable x amount a time i found my ram full and a reeeeally slow access to webgui and always time-out access to docker app. When i finally access the webgui i found the cpu almost at 100% and ram 97% full ( 64gb ) with >40 gb from docker ( usually i got like half ram free ). Unfortunately the docker page times out so i have no way to see what's causing this - same for "docker stats" command on cli. Note that i found strange: when run btop on ssh-terminal my cpu is at 20-30%, completely different from what the webgui it's showing? It's not the first time these diverge, but not by so much. ( actually they've never been comparable even with similar refresh timing ) So how can i solve this? what's causing it? -->I made a diagnostic log(unraid-diagnostics-20250319-1543.zip) via cli and i added the docker logs that looks incredibly suspicious(docker.log.1.txt). If you need something else let me know. PS: Do you know why the cpus utilization diverge? Always been curious about that. unraid-diagnostics-20250319-1543.zip docker.log.1.txt
-
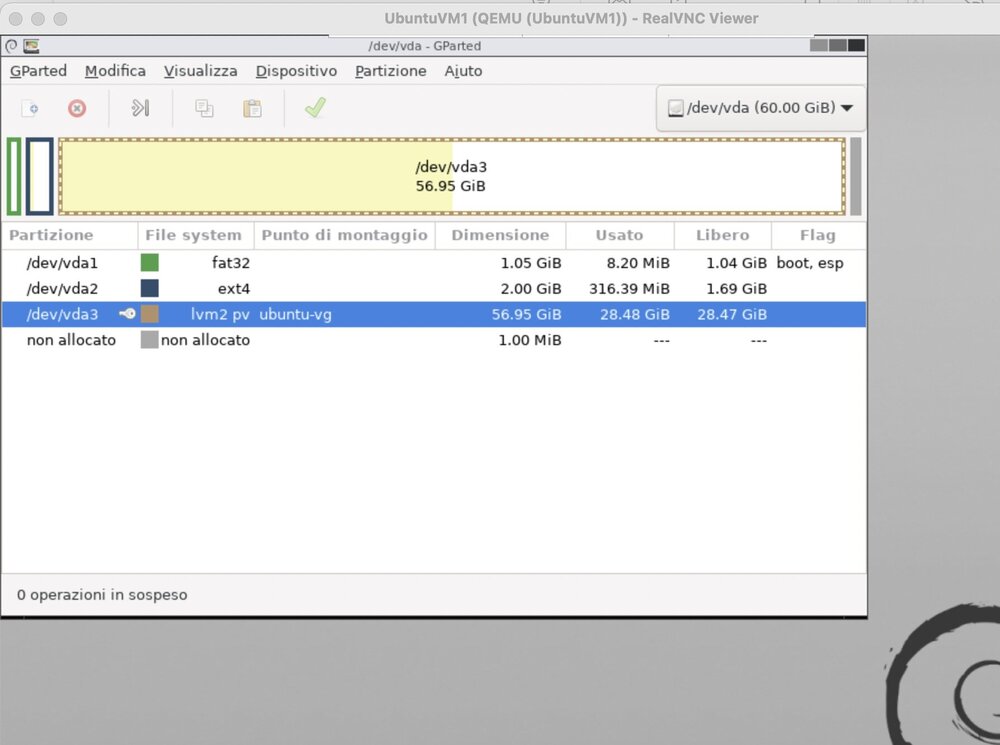
To solve this i first checked the name of my root folder partition on the disk with : lory@ubuntuvm1:~$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 63.7M 1 loop /snap/core20/2434 loop1 7:1 0 55.4M 1 loop /snap/core18/2855 loop2 7:2 0 63.8M 1 loop /snap/core20/2496 loop3 7:3 0 91.9M 1 loop /snap/lxd/24061 loop4 7:4 0 55.4M 1 loop /snap/core18/2846 loop5 7:5 0 91.9M 1 loop /snap/lxd/29619 loop6 7:6 0 44.3M 1 loop /snap/snapd/23258 loop7 7:7 0 44.4M 1 loop /snap/snapd/23545 loop8 7:8 0 71M 1 loop /snap/prometheus/86 sr0 11:0 1 528M 0 rom vda 252:0 0 60G 0 disk ├─vda1 252:1 0 1.1G 0 part /boot/efi ├─vda2 252:2 0 2G 0 part /boot └─vda3 252:3 0 57G 0 part └─ubuntu--vg-ubuntu--lv 253:0 0 28.5G 0 lvm / Then: lory@ubuntuvm1:~$ sudo lvextend -l +100%FREE /dev/mapper/ubuntu--vg-ubuntu--lv Size of logical volume ubuntu-vg/ubuntu-lv changed from 28.47 GiB (7289 extents) to <56.95 GiB (14578 extents). Logical volume ubuntu-vg/ubuntu-lv successfully resized. Then: lory@ubuntuvm1:~$ sudo resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv resize2fs 1.45.5 (07-Jan-2020) Filesystem at /dev/mapper/ubuntu--vg-ubuntu--lv is mounted on /; on-line resizing required old_desc_blocks = 4, new_desc_blocks = 8 The filesystem on /dev/mapper/ubuntu--vg-ubuntu--lv is now 14927872 (4k) blocks long. Mission Accomplished: lory@ubuntuvm1:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 1.9G 0 1.9G 0% /dev tmpfs 392M 41M 352M 11% /run /dev/mapper/ubuntu--vg-ubuntu--lv 56G 28G 26G 52% / Thank you very much for your help @Kilrah
-
Ehm... i spoke too soon, the disk already appears as expanded? see below...
-
can i do it directly inside the vm while it's live? Edit: Stupid question, all my IO and changes are blocked so no way to do it. I'll mount an ISO as a second HDD. Thank you!
-
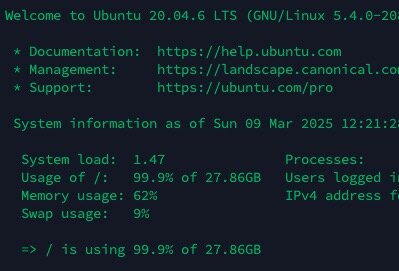
Hi everyone. As per title my problem is quite simple actually : i have a vm which has a 60G qcow2 and yet with just 30G reported by the vm OS, it's reported as full (99.9% root folder used <-- see screenshots ). What can i do to solve the problem?

-
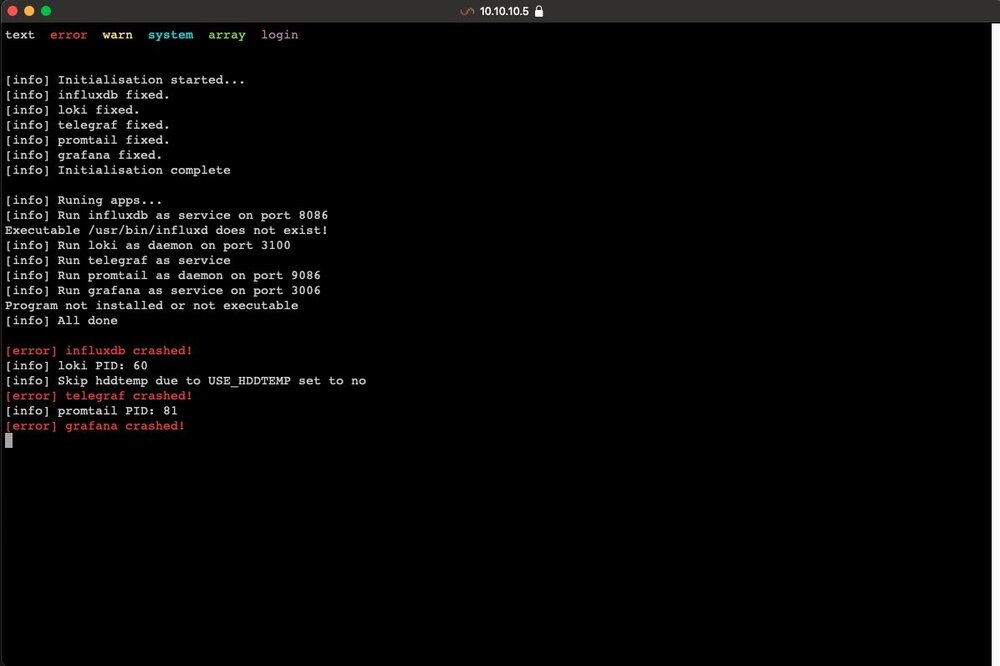
First install today. Not a great start... I didn't modify anything in the config, is someone else having this problem? Having done nothing i don't really know how to solve it...
-
Edit: In the end i solved it: When adding automatically via "load shares" on UD it adds it as /exports/Cold_backups while actually can only be mounted as /Cold_backups without the /export part. I don't know if it's usual or if It may be a misconfiguration on my part from OMV that lets UD see all the folder tree. I'll fiddle with it in the future, for now at least i can make my backups again. Thank you A bit late because i don't have time but i just tried and it says the same thing. Now i'll use SMB and maybe by Christmas when i'll have more time i'll look into it.

-
Thanks for the fast answer, here i report that: The remote share is correct For testing purposes i removed all restrictions to the nfs share. I tested and mounted correctly the share with another debian distro without problems. . Nothing appears on system logs but i couldn't find nfs-specific ones ( at least i'm not aware of them ) Tested with this too. Same results which i attach with another diagnostics. I tested both the troubleshooting section in settings and the normal mounting with the direct ip too and yet same error. * bonus : i deleted all the UD plugins, rm -rf'd them from boot plugin-removed folder and reinstalled everything. Nothing changed. As i've told in the beginning it's reasonable to believe that the problems isn't mine. 1 hour before the hw swapping and softw upgrading everything was working. Then everything was broken and i didn't touch anything. Anyway now i think i really uploaded everything i could to diagnose it. I don't know if it's a Unraid 7 or a UD problem but it's a bug. ud_diagnostics-20241121-164117.zip unraid-diagnostics-20241121-1644.zip

-
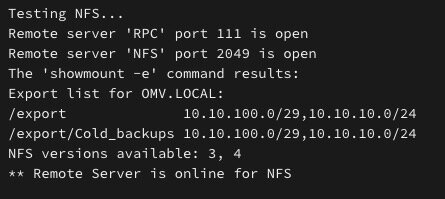
Hi @dlandon, first time i post here but i'll try to be brief I have a problem with NFS - I have an OpenMediaVault server with a single disk for "Cold_backups" ( warm actually but doesn't matter now ) shared trough NFS with the unraidip/32 as only allowed client. It worked (after lots of tries) with unraid 6.x.x but last week i upgraded to the latest intel core ultra 245 so new cpu,mobo, ram from ddr4 to 5 etc. To make it work with my config i had to upgrade to unraid 7 and since i've upgraded the same exact NFS share that i was using for backups automatically (restic via backrest) now doesn't work anymore. I know a lot has changed in my server, but technically the hardware shouldn't make a difference and that's why i believe it's a bug with UD and unraid 7. The disk "connects" ok, and the little dot is green ( so it sees OMV as online and can communicate with it) but as i click "mount" comes the error of "no file or directory". I tried messing around with options like subtree_check ( shouldn't matter ) or "nohide" yet nothing changed. After all it was already working before.. Anyway here are the diagnostics hope it's an easy to solve problem or simply a mess up from my part. P.S: Thank you for your incredible work! ud_diagnostics-20241120-111222.zip
-
No, from what i remember nothing is necessary except for what it's written in this guide ( and in the iker one ). I'd suggest you to start with the method used by Iker first since it should work ( as i've written above i've replicated the exact same steps but sort of manually ). As for the second question, unfortunately no. As i've written in my previous posts my server now has expanded in functionalities, it's central to lots of services i regularly use and, most importantly, i have not time to tinker with it like i had before so i'm much more conservative. I turned back to acpi because i had a problem with updating the unraidOS and since i didn't have much time at my disposal then i simply decided to reverse most of my previous tinkering and experiments trying to solve the issue ( i didn't in the end and i had to use a workaround, but it means that it wasn't amd-pstate fault ). Since then i never ended up setting it up again for the reason above. Anyway when i used it i had no problems at all and was actually using like 10% less power than before. ( i don't remember the exact figure, could be 15% ). Other factors to consider are that i have a 3900X which it's quite old and i remember that while was looking for answers at the time i discovered that -not surprisingly- the 5xxx and even more the 7xxx are much better both in idle and in power saving function unlocked by the pstate ( 'cause infinity fabric optimization which is the main culprit for high idle consumption ). Moreover the pstate module itself received quite a lot of updates in the kernel so it'll surely be better than when i tried it. To sum this up: i advice you to try it, it's quite easy after all and you may be in for some nice surprises. If you do please find some time to report back in this post, if you have nice results maybe i'll set it up again!
-
Thank you for your answer jorge, but as i've written above that's not the time when i had the problem and strangely enough when i have it nothing shows up in syslog. To confirm i've kept using the server until the problem showed up again and again and, in fact, nothing showed up in syslog ever. I've installed the drivers anyway and it seems to work better now? i don't know may be placebo. Anyway since the problem seems so large and no one can give me any direction i'll tinker on my own and i'll post if i'll have updates.
-
TL:DR: 1st issue= didn't have the time 2nd issue=attachments as requested. It happened 8 february 2024 at 4:47~4:48 pm. (in italian format: 08/02/2024 at 16:47 ~ 16:48 ) Hi Jorge, taking the server back online was low priority and it took me a long time but here i am now. 1st issue: In regards of the first problem i described i simply did as usual without any long-term solution; in these first months of the year i don't have much time so if it was a relatively algorithmic solution process, meaning someone had a list of intructions for me to follow, i could have found the time but not an exploratory phase with the server offline. 2nd issue: As described in TLDR, but i'm gonna add that looking at the syslog i've noted something regarding the connection at ~16:23 but i don't know what happened at that time. Other information are: - It happens almost always at least a couple of times when i try to stream content from plex/jellyfin. Nowadays i've found other way to consume content because it's unbearable. - It happens on his own too. while i'm not using the server. - My server is not local, but i connect trough tailscale over internet as stated in the first post. - For this reason i didn't yet try to update the realtek drivers. my NIC as per system devices: Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller (rev 15) - when the problem arises, if i try to connect to the dashboard via browser it doesn't say "can't connect" or something but it seems like the server "answers" but does not load the webpage. ( it's the same for all the other addresses on the subnet ). Thanks you again for your time, hope to hear good news soon. unraid-syslog-20240208-1615.zip unraid-diagnostics-20240208-1653.zip
-
No one knows how to help me?
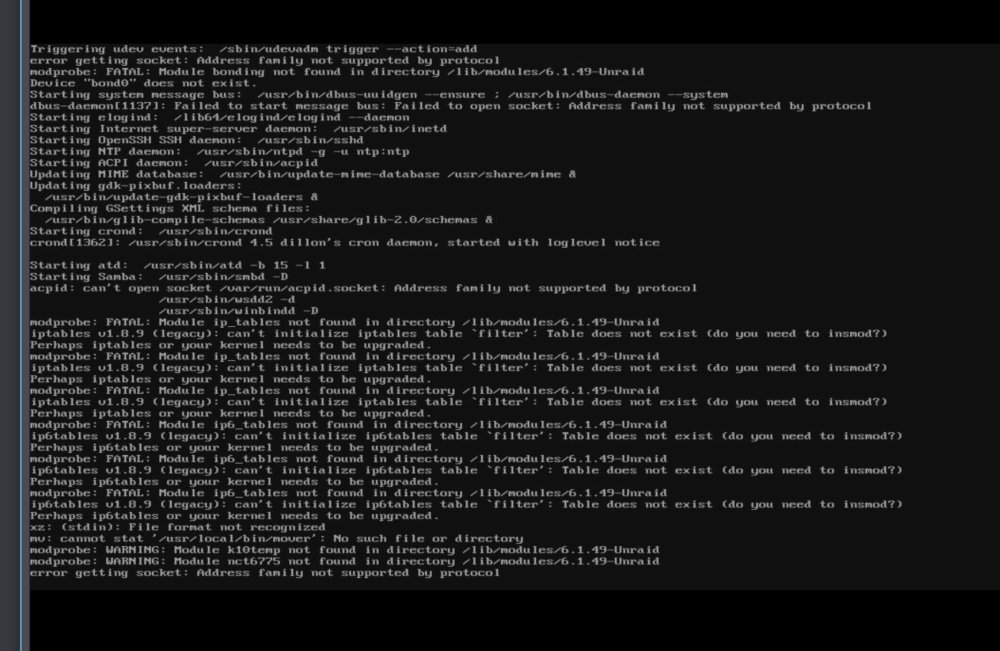
-
Hi everybody, As per Title i've got 2 problems that i'm gonna ask you help me for. TL;DR 1️⃣ Server is offline. Can't update without reinstalling from backup, it happened more than 1 time already, screen down below. Can you help me? 2️⃣ random disconnections, realtek interface but the problem didn't appear before (and i can't install the drivers now without the server online). Could be widespread on LAN. Could be connected with problem 1. I have no clue. Excluded tailscale and vpns from causes & MACVLAN not configured, docker is set IPVLAN. Help? 1) Repeating update problem: Every time i update my server i can't access it afterwards no matter how much time i wait. The only way is to format the usb and copy all the contents from a previous backup back in, then it always -strangely- seems to be upgraded: version number is updated in the dashboard and everything works as expected ( the second problem may or may not be connected with this, read point 2 ). But of course it's a pain to know that everytime it's the same story, and moreover my piKVM shows this, which seems... not fine: The screen you see it's 20 minutes after the last -failed- update 6.12.4 to 6.12.6 and it's very similar -if not the same- to what i've always seen after an always unsuccessful update. This happened since forever since my first unraid install ( 6.12.5 or .4) - First and foremost: Correct way to get the server back up? Do i reinstall from backup as i always did or now it's the time to intervene? - Is there a way -like in windows recovery- to tell the system to check for errors and autocorrect them OR a way to reinstall fresh without losing my 300+ hours spent last year in optimizations, configurations and automations? i'd prefer to kill myself than have to configure recyclarr,radarr,tdarr and the two sonarr instances, + vpns and all dockers back. no way in hell i'm gonna do that. Please PLEASE save my mental health guys, i know you can do that. 2) Recently i very often suffered from random disconnections, which seemed to disrupt other devices on the same network too ( it's on my grandparents network, they got the juicy FTTH ). They have a technicolor router and zyxel gpon interface which are buggy and shitty, but i verified that they worked no problems before my unraid server installation there. I got a realtek interface and i've seen that in the changelog says that it may be the problem but: in the past worked without problems ( i can't pinpoint when exactly the problem arose ) in the past the problem solved itself ( well, i tinkered with the server a bit and seemed to have solved it then ) but then it arose again. It may be a router configuration problem since seems to be widespread on the LAN but i still kinda doubt it. There may be a lot of explanations on why the internet wasn't working, one of which was my misconfiguration of qbittorrent, one of course is because grandparents aren't trustworthy in the figuring-problem-regard and another one was that all the fiber apparatus may have gone nuts. A lot of reasons for a very generic problem with no easy way to diagnose it ( nor time, honestly ). In the past i thought about vpn/tailscale problem but i excluded it having tested all the possibile configuration of those on/off in both my unraid server and pivkm subnet tailscale router. It can't be the macvlan problem too since i recently moved back to ipvlan with no success. If you read all of it thanks you, truly, i know the second problem may be hard to diagnose but it really made the server unusable. Still the first problem is more urgent so i'll eagerly wait for your answers. I'm not an english native speaker so forgive my errors or strange phrases and thanks you again for your time.