quietwalker
Members
-
Joined
-
Last visited
-
I forgot to also thank you so much @JorgeB for your help
-
oh it looks like that error is reporting a communication problem with the mobo, so if it's stick to 1 could be "ok-ish" if not it could mean there are other things to check like the sata cable
-
The file system was reported as corrupted, so I followed the linked document to repair it and it looks like it went fine: Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata out-of-order bno btree record 20 (45940341 7696533) block 0/1 block (0,49047993-50851830) multiply claimed by bno space tree, state - 1 block (0,22686522-22705196) multiply claimed by cnt space tree, state - 2 invalid length 184083031 in record 24 of cnt btree block 0/2 agf_freeblks 226938157, counted 32162074 in ag 0 agf_longest 201787316, counted 16650810 in ag 0 finobt ir_freecount/free mismatch, inode chunk 0/38792896, freecount 61 nfree 59 agi_freecount 159, counted 137 in ag 0 agi_freecount 159, counted 139 in ag 0 finobt out-of-order bno btree record 11 (5389297 18322) block 5/1 block (5,5389297-5407618) multiply claimed by bno space tree, state - 1 out-of-order cnt btree record 16 (30058396 32726) block 5/2 out-of-order cnt btree record 17 (25705055 32903) block 5/2 out-of-order cnt btree record 18 (15090297 33430) block 5/2 block (5,24753591-24803860) multiply claimed by cnt space tree, state - 2 out-of-order cnt btree record 21 (8855228 50699) block 5/2 block (5,24753591-24836770) multiply claimed by cnt space tree, state - 2 block (5,25705055-25737957) multiply claimed by cnt space tree, state - 2 block (5,30058534-30091121) multiply claimed by cnt space tree, state - 2 agf_freeblks 248189470, counted 248230838 in ag 5 sb_ifree 962, counted 940 sb_fdblocks 2328342685, counted 2154038910 - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 entry contains offset out of order in shortform dir 131 corrected entry offsets in directory 131 imap claims a free inode 133 is in use, correcting imap and clearing inode cleared inode 133 imap claims a free inode 188 is in use, correcting imap and clearing inode cleared inode 188 imap claims a free inode 189 is in use, correcting imap and clearing inode cleared inode 189 imap claims a free inode 190 is in use, correcting imap and clearing inode cleared inode 190 imap claims a free inode 191 is in use, correcting imap and clearing inode cleared inode 191 data fork in ino 38792898 claims free block 22614954 data fork in ino 38792900 claims free block 65892374 data fork in ino 38792901 claims free block 4849111 imap claims in-use inode 38792901 is free, correcting imap data fork in ino 38792902 claims free block 4843771 imap claims in-use inode 38792902 is free, correcting imap data fork in ino 38792903 claims free block 4843772 imap claims in-use inode 38792903 is free, correcting imap imap claims in-use inode 38792904 is free, correcting imap imap claims in-use inode 38792905 is free, correcting imap imap claims in-use inode 38792906 is free, correcting imap imap claims in-use inode 38792907 is free, correcting imap imap claims in-use inode 38792908 is free, correcting imap imap claims in-use inode 38792909 is free, correcting imap imap claims in-use inode 38792910 is free, correcting imap imap claims in-use inode 38792912 is free, correcting imap imap claims in-use inode 38792913 is free, correcting imap imap claims in-use inode 38792914 is free, correcting imap imap claims in-use inode 38792915 is free, correcting imap imap claims in-use inode 38792916 is free, correcting imap imap claims in-use inode 38792917 is free, correcting imap imap claims in-use inode 38792918 is free, correcting imap imap claims in-use inode 38792919 is free, correcting imap imap claims in-use inode 38792920 is free, correcting imap imap claims in-use inode 38792921 is free, correcting imap imap claims in-use inode 38792922 is free, correcting imap imap claims in-use inode 38792923 is free, correcting imap imap claims in-use inode 38792924 is free, correcting imap imap claims in-use inode 38792925 is free, correcting imap imap claims in-use inode 38792926 is free, correcting imap imap claims in-use inode 38792927 is free, correcting imap data fork in ino 38792928 claims free block 4843804 imap claims in-use inode 38792928 is free, correcting imap imap claims a free inode 38792961 is in use, correcting imap and clearing inode cleared inode 38792961 imap claims a free inode 38792962 is in use, correcting imap and clearing inode cleared inode 38792962 imap claims a free inode 38792963 is in use, correcting imap and clearing inode cleared inode 38792963 imap claims a free inode 38792964 is in use, correcting imap and clearing inode cleared inode 38792964 imap claims a free inode 38792965 is in use, correcting imap and clearing inode cleared inode 38792965 imap claims a free inode 38792966 is in use, correcting imap and clearing inode cleared inode 38792966 imap claims a free inode 38792967 is in use, correcting imap and clearing inode cleared inode 38792967 imap claims a free inode 38792968 is in use, correcting imap and clearing inode cleared inode 38792968 imap claims a free inode 38792969 is in use, correcting imap and clearing inode cleared inode 38792969 imap claims a free inode 38792970 is in use, correcting imap and clearing inode cleared inode 38792970 imap claims a free inode 38792971 is in use, correcting imap and clearing inode cleared inode 38792971 imap claims a free inode 38792972 is in use, correcting imap and clearing inode cleared inode 38792972 imap claims a free inode 38792973 is in use, correcting imap and clearing inode cleared inode 38792973 imap claims a free inode 38792974 is in use, correcting imap and clearing inode cleared inode 38792974 imap claims a free inode 38793001 is in use, correcting imap and clearing inode cleared inode 38793001 imap claims a free inode 38793002 is in use, correcting imap and clearing inode cleared inode 38793002 imap claims a free inode 38793005 is in use, correcting imap and clearing inode cleared inode 38793005 imap claims a free inode 38793006 is in use, correcting imap and clearing inode cleared inode 38793006 imap claims a free inode 38793007 is in use, correcting imap and clearing inode cleared inode 38793007 imap claims a free inode 38793008 is in use, correcting imap and clearing inode cleared inode 38793008 imap claims a free inode 38793009 is in use, correcting imap and clearing inode cleared inode 38793009 imap claims a free inode 38793010 is in use, correcting imap and clearing inode cleared inode 38793010 imap claims a free inode 38793011 is in use, correcting imap and clearing inode cleared inode 38793011 imap claims a free inode 38793012 is in use, correcting imap and clearing inode cleared inode 38793012 imap claims a free inode 38793013 is in use, correcting imap and clearing inode cleared inode 38793013 imap claims a free inode 38793014 is in use, correcting imap and clearing inode cleared inode 38793014 imap claims a free inode 38793015 is in use, correcting imap and clearing inode cleared inode 38793015 imap claims a free inode 38793016 is in use, correcting imap and clearing inode cleared inode 38793016 imap claims a free inode 38793017 is in use, correcting imap and clearing inode cleared inode 38793017 imap claims a free inode 38793018 is in use, correcting imap and clearing inode cleared inode 38793018 imap claims a free inode 38793019 is in use, correcting imap and clearing inode cleared inode 38793019 imap claims a free inode 38793020 is in use, correcting imap and clearing inode cleared inode 38793020 imap claims a free inode 38793021 is in use, correcting imap and clearing inode cleared inode 38793021 imap claims a free inode 38793022 is in use, correcting imap and clearing inode cleared inode 38793022 imap claims a free inode 38793023 is in use, correcting imap and clearing inode cleared inode 38793023 data fork in ino 39094790 claims free block 46037061 data fork in ino 39094790 claims free block 46175871 data fork in ino 39094790 claims free block 48272671 data fork in ino 39094790 claims free block 50369312 data fork in ino 39094790 claims free block 50696762 imap claims a free inode 39094815 is in use, correcting imap and clearing inode cleared inode 39094815 imap claims a free inode 39094816 is in use, correcting imap and clearing inode cleared inode 39094816 imap claims a free inode 39094817 is in use, correcting imap and clearing inode cleared inode 39094817 imap claims a free inode 39094818 is in use, correcting imap and clearing inode cleared inode 39094818 imap claims a free inode 39094819 is in use, correcting imap and clearing inode cleared inode 39094819 imap claims a free inode 39094820 is in use, correcting imap and clearing inode cleared inode 39094820 imap claims a free inode 39094821 is in use, correcting imap and clearing inode cleared inode 39094821 imap claims a free inode 39094822 is in use, correcting imap and clearing inode cleared inode 39094822 imap claims a free inode 39094823 is in use, correcting imap and clearing inode cleared inode 39094823 imap claims a free inode 39094824 is in use, correcting imap and clearing inode cleared inode 39094824 imap claims a free inode 39094825 is in use, correcting imap and clearing inode cleared inode 39094825 imap claims a free inode 39094826 is in use, correcting imap and clearing inode cleared inode 39094826 imap claims a free inode 39094827 is in use, correcting imap and clearing inode cleared inode 39094827 imap claims a free inode 39094828 is in use, correcting imap and clearing inode cleared inode 39094828 imap claims a free inode 39094829 is in use, correcting imap and clearing inode cleared inode 39094829 imap claims a free inode 39094830 is in use, correcting imap and clearing inode cleared inode 39094830 imap claims a free inode 39094831 is in use, correcting imap and clearing inode cleared inode 39094831 imap claims a free inode 39094832 is in use, correcting imap and clearing inode cleared inode 39094832 imap claims a free inode 39094833 is in use, correcting imap and clearing inode cleared inode 39094833 imap claims a free inode 39094834 is in use, correcting imap and clearing inode cleared inode 39094834 imap claims a free inode 39094835 is in use, correcting imap and clearing inode cleared inode 39094835 imap claims a free inode 39094836 is in use, correcting imap and clearing inode cleared inode 39094836 imap claims a free inode 39094837 is in use, correcting imap and clearing inode cleared inode 39094837 imap claims a free inode 39094838 is in use, correcting imap and clearing inode cleared inode 39094838 imap claims a free inode 39094839 is in use, correcting imap and clearing inode cleared inode 39094839 imap claims a free inode 39094840 is in use, correcting imap and clearing inode cleared inode 39094840 imap claims a free inode 39094841 is in use, correcting imap and clearing inode cleared inode 39094841 imap claims a free inode 39094842 is in use, correcting imap and clearing inode cleared inode 39094842 imap claims a free inode 39094843 is in use, correcting imap and clearing inode cleared inode 39094843 imap claims a free inode 39094844 is in use, correcting imap and clearing inode cleared inode 39094844 imap claims a free inode 39094845 is in use, correcting imap and clearing inode cleared inode 39094845 imap claims a free inode 39094846 is in use, correcting imap and clearing inode cleared inode 39094846 imap claims a free inode 39094847 is in use, correcting imap and clearing inode cleared inode 39094847 data fork in ino 39249586 claims free block 23412739 data fork in ino 39249587 claims free block 23425889 data fork in ino 39249589 claims free block 23559047 data fork in ino 39249589 claims free block 25655175 data fork in ino 39249589 claims free block 27750279 data fork in ino 39249590 claims free block 28468789 data fork in ino 39249590 claims free block 28530341 data fork in ino 39249591 claims free block 28507205 data fork in ino 39249591 claims free block 28536428 data fork in ino 39249593 claims free block 28560610 data fork in ino 39249593 claims free block 29739663 data fork in ino 39249596 claims free block 29567633 data fork in ino 39249596 claims free block 29619883 data fork in ino 39249598 claims free block 29591617 data fork in ino 39282880 claims free block 29620527 data fork in ino 39282880 claims free block 29804982 imap claims a free inode 39282903 is in use, correcting imap and clearing inode cleared inode 39282903 imap claims a free inode 39282904 is in use, correcting imap and clearing inode cleared inode 39282904 imap claims a free inode 39282905 is in use, correcting imap and clearing inode cleared inode 39282905 imap claims a free inode 39282906 is in use, correcting imap and clearing inode cleared inode 39282906 imap claims a free inode 39282907 is in use, correcting imap and clearing inode cleared inode 39282907 imap claims a free inode 39282908 is in use, correcting imap and clearing inode cleared inode 39282908 imap claims a free inode 39282909 is in use, correcting imap and clearing inode cleared inode 39282909 imap claims a free inode 39282910 is in use, correcting imap and clearing inode cleared inode 39282910 imap claims a free inode 39282911 is in use, correcting imap and clearing inode cleared inode 39282911 imap claims a free inode 39282912 is in use, correcting imap and clearing inode cleared inode 39282912 imap claims a free inode 39282913 is in use, correcting imap and clearing inode cleared inode 39282913 imap claims a free inode 39282914 is in use, correcting imap and clearing inode cleared inode 39282914 imap claims a free inode 39282915 is in use, correcting imap and clearing inode cleared inode 39282915 imap claims a free inode 39282916 is in use, correcting imap and clearing inode cleared inode 39282916 imap claims a free inode 39282917 is in use, correcting imap and clearing inode cleared inode 39282917 data fork in ino 39282922 claims free block 22647642 data fork in ino 39297245 claims free block 15330322 data fork in ino 39297246 claims free block 15121346 data fork in ino 39297246 claims free block 15925064 data fork in ino 39297247 claims free block 15651096 data fork in ino 39297247 claims free block 16470410 data fork in ino 39297248 claims free block 15866968 data fork in ino 39297248 claims free block 16212170 data fork in ino 39297248 claims free block 16831344 data fork in ino 39297270 claims free block 22705197 - agno = 1 - agno = 2 - agno = 3 data fork in ino 6442451074 claims free block 820740484 correcting nblocks for inode 6442451074, was 33102 - counted 34126 correcting nblocks for inode 6442451078, was 33101 - counted 38221 - agno = 4 - agno = 5 data fork in ino 10741592240 claims free block 1347552263 imap claims in-use inode 10741592240 is free, correcting imap imap claims a free inode 10741592248 is in use, correcting imap and clearing inode cleared inode 10741592248 data fork in ino 10741592250 claims free block 1347584899 data fork in ino 10764926978 claims free block 1347594398 data fork in ino 10764926987 claims free block 1357267577 data fork in ino 10764927021 claims free block 1387508331 data fork in ino 10764927023 claims free block 1387530279 data fork in ino 10765080509 claims free block 1372235676 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 3 - agno = 2 entry "ab_20250622_010002" in shortform directory 131 references free inode 38792896 junking entry "ab_20250622_010002" in directory inode 131 entry "ab_20250622_010002" in shortform directory 131 references free inode 38792896 junking entry "ab_20250622_010002" in directory inode 131 - agno = 5 - agno = 1 - agno = 7 - agno = 4 - agno = 6 - agno = 8 - agno = 9 - agno = 10 setting reflink flag on inode 6442451074 Missing reference count record for (3/15434346) len 794 count 2 Missing reference count record for (3/17143542) len 5120 count 2 setting reflink flag on inode 6442451078 setting reflink flag on inode 6442451079 setting reflink flag on inode 6442710243 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... disconnected inode 38792901, moving to lost+found disconnected inode 38792902, moving to lost+found disconnected inode 38792903, moving to lost+found disconnected inode 38792904, moving to lost+found disconnected inode 38792905, moving to lost+found disconnected inode 38792906, moving to lost+found disconnected inode 38792907, moving to lost+found disconnected inode 38792908, moving to lost+found disconnected inode 38792909, moving to lost+found disconnected inode 38792910, moving to lost+found disconnected inode 38792912, moving to lost+found disconnected inode 38792913, moving to lost+found disconnected inode 38792914, moving to lost+found disconnected inode 38792915, moving to lost+found disconnected inode 38792916, moving to lost+found disconnected inode 38792917, moving to lost+found disconnected inode 38792918, moving to lost+found disconnected inode 38792919, moving to lost+found disconnected inode 38792920, moving to lost+found disconnected inode 38792921, moving to lost+found disconnected inode 38792922, moving to lost+found disconnected inode 38792923, moving to lost+found disconnected inode 38792924, moving to lost+found disconnected inode 38792925, moving to lost+found disconnected inode 38792926, moving to lost+found disconnected inode 38792927, moving to lost+found disconnected inode 38792928, moving to lost+found disconnected inode 39094790, moving to lost+found disconnected inode 6442451074, moving to lost+found disconnected inode 6442451078, moving to lost+found disconnected inode 6442451079, moving to lost+found disconnected inode 6442451096, moving to lost+found disconnected inode 10741592240, moving to lost+found Phase 7 - verify and correct link counts... resetting inode 131 nlinks from 10 to 8 resetting inode 6442451075 nlinks from 1 to 2 Maximum metadata LSN (1:257765) is ahead of log (1:2). Format log to cycle 4. done Now I got a notification warning which reports this: is this meaning that also the parity disks is near to experience a fault?
-
oh sorry, I forgot to add it. homeserver-diagnostics-20250701-0942.zip
-
Hello people! I'm having a problem with my unraid server. One of the disks in my array was faulty: the bad part is that it failed with almost no error or warning before (I just receaved an error 1 day before the failure, but it was already too late). Now I removed that disk and waiting to replace it tomorrow or in two days (I'm waiting for the shipping of the replacement hard drive) and started the array. The array looks fine, I also performed the extend SMART test and all finished without errors, but most of my docker containers are not able to start because of I/O errors. I can manually write into the cache, so the cache disk is not the problem here, so I guess the problem may be that for some reason some files of the cache were stored in the faulted drive. Could you confirm that? I'm not sure how can I check that on my own. The real question here is: how can I recover from this situation, while I'm waiting for the drive replacement? Could I just restore the containers and their files from the last backup (I use AppData Backup plugin)? If this is not enough, I have another hard drive where I store another copy of all my backups: also that drive failed yesterday...I guess I'm not lucky! Luckily I have other backup copies in other places, for occasions like this. But I think I was really very unlucky this time :D After this experience, I think I will start storing my encrypted backups also in cloud ahahhah Thanks for those who can help me figure this out.
-
yeah that totally makes sense. Thanks so much for your feedback guys!
-
thanks Jonathan! I guess the other alternative could looks like: - set all shares to put data in the Array - stop docker and VM services - run the mover - check from logs that everything moved into the array (may be worth a doublecheck from terminal too) - destroy the cache pool - remove 1 nvme disk - recreate the cache pool with only 1 disk - rollback share setting to put data in cache again (for those who need cached data) - execute mover again (should move back in cache all the necessary stuff, like appdata) - start docker and VM services again does it sounds correct too? Anyway I think I will run unraid in single disk cache for a month or two and then I will create a new cache using SSDs instead of nvme. In that way I could potentially buy another m2 to sata adapter and mount something like 14 sata disks. EDIT: I added above the missing steps @JonathanM mentioned in the next comment. Thanks!
-
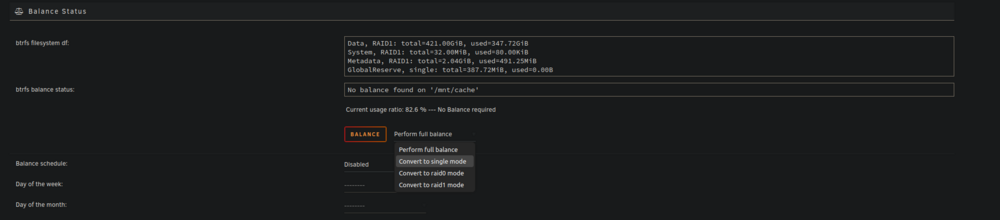
Thanks! I bought it, so next week I should be able to test it. So now the next question is: shoud I rebalance my nvme cache pool to "single mode", using the btrfs function to be able to remove one of my 2 nvme drives? Is that correct?
-
Hey people! I'm the owner of an AsRock H670M-ITX/ax which has 4 SATA ports, 2 NVME slots and one x16 PCIE slot (link to the Asrock site if you want to know more: https://www.asrock.com/mb/Intel/H670M-ITXax/index.asp). Actually my server has: - 2x12TB IronWolf NAS disks (1 parity + 1 storage) - 2x2TB SSD disks configured as btrfs mirror pool - 2x500GB NVME disks configured as mirrored cache so, as you can see, all my SATA slots are used but I need to add more disks. I actually have one disk I need to add to the array so I'm searching for suggestions on how I should proceed. I'm thinking about an NVME adapter with 6 SATA ports on it, like this one: https://www.amazon.it/Mengtech-Adattatore-SATA-NVME-espansione/dp/B0CZ3QR5HH/ but there will be a "problem": I will need to destroy the cache mirror and use only 1 NVME disk as cache device, which will mean no replication (aka data loss when the NVME drive will fails), and I don't even see any how to in the online manual site regarding this operation. In addition I think I should mention that each of the 6 SATA ports on the adapter, if they will be active at the same time under certain conditions, it could generate a bottleneck (I know it's unlikely to happen, at least in my env, but I should consider it anyway). so my questions are: is this approach doable? using these type of adapters, will it still be possible to spun down the drives? Is there any better alternative to this solution, keeping in mind that I would like to be able to expand my array even more in future? Thanks for any feedback
-
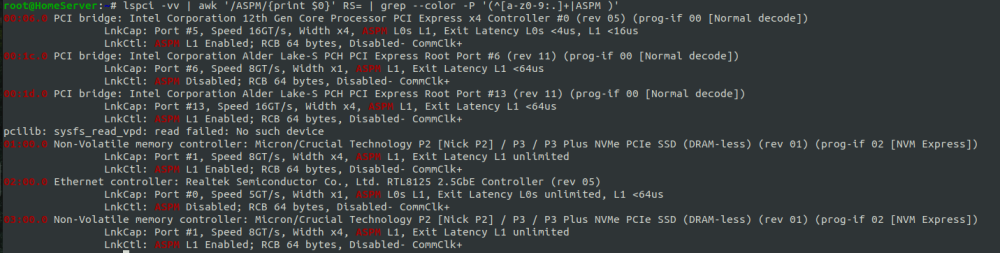
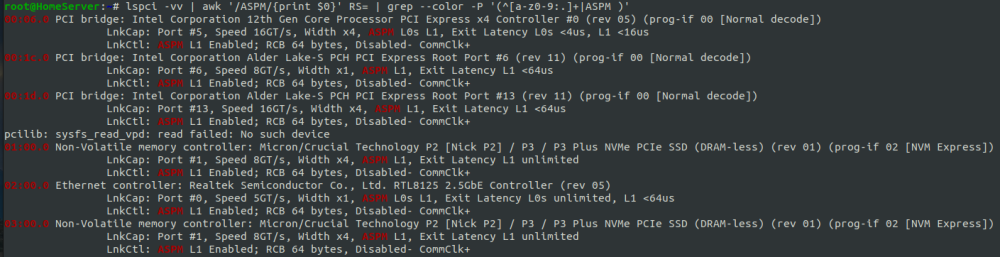
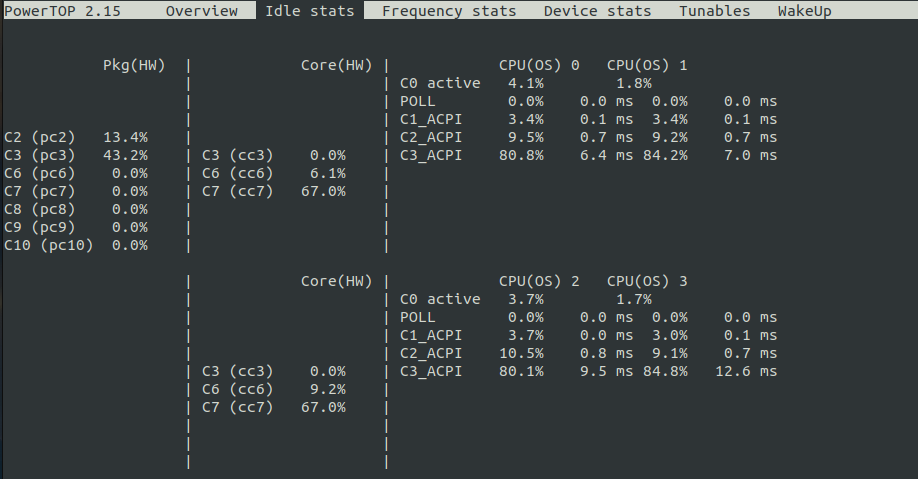
This fixed the Realtek card issue with ASPM disable. Now it is shown as enabled: echo 1 > /sys/bus/pci/devices/0000:02:00.0/link/l1_aspm Unfortunately powertop still shows
-
Hi people! My setup is: Mobo: ASRock H670M-ITX/ax RAM: 2X16GB PSU: picoPSU 150w CPU: 13th Gen Intel® Core™ i3-13100 @ 3366 MHz 2 nvme as cache: Crucial P3 2 SSD: 1 Samsung 870QVO and 1 Crucial BX500 2x12TB HDD: 1 parity and 1 data disk Unfortunately I'm not able to go lower than C3. The ASPM output shows ASPM disabled for 2 devices: I've enabled all ASPM settings, p-cores and c-states supports as suggested in the first @mgutt post but I'm still unable to understand why I cannot enable ASPM also for those 2 devices shown in the above output. These are some of the settings I edited from BIOS: CPU C-state support: enabled enhanced halt state(C1E): enabled CPU C6/C7 state support: enabled package Cstate support: enabled CFG lock: enable (don't really know if it's necessary or not) C6 DRAM: enabled PCIE native controll: enabled PCIE ASPM Support: L0S1 PH PCIE ASPM Support: L1 (is the only available) DMI ASPM Support: enabled SATA Aggressive link power mode: enabled onboard WAN device: disabled onboard Audio: disabled I also performed the actions suggested here, using another ssd formatted with windows 11 only to perform those steps: Actually my power draw from wall is not bad when idle (it flows between 18w/h and 30w/h, especially after I did the above reddit post steps. Before the power draw was pretty stable at 20w in idle), but I think this mobo could consume less if it could reach lower c-states. EDIT: with ubuntu desktop with the same setup and disks spun down it consumes 16watt, but powertop shows a different interface where cstates are only shown as C1_ACPI,C2_ACPI, C3_ACPI and RC6pp and it reaches C3_ACPI for 97% of the time (don't know if this could help). In addition lspci return all ASPM status as enabled for all the devices. Do anyone of you have any suggestion for me?
-
sure, if it may help you. In alternative you can install GPU Statistic plugin (this is the package URL: https://raw.githubusercontent.com/b3rs3rk/gpustat-unraid/master/gpustat.plg) have you added the following in the Extra Parameters setting of Jellyfin container (you have to enable the advanced view)? --device=/dev/dri If you have done it, check in the host and into the docker container (with docker exec -it <container name> bash or using the Unraid interface to open a terminal session into the container) if that device is available. jellyfin-template.xml
-
The template for the official one was removed recently because the maintainer of the template wasn't able anymore to maintain it anymore. I guess you can just select one of the template available in the App Center and just use the official docker image in the field "Repository" (it is jellyfin/jellyfin ). Of course you should adapt the container internal paths
-
using intel-gpu-top
-
it looks like it is correctly configured