un1ty
Members
-
Joined
-
Last visited
-
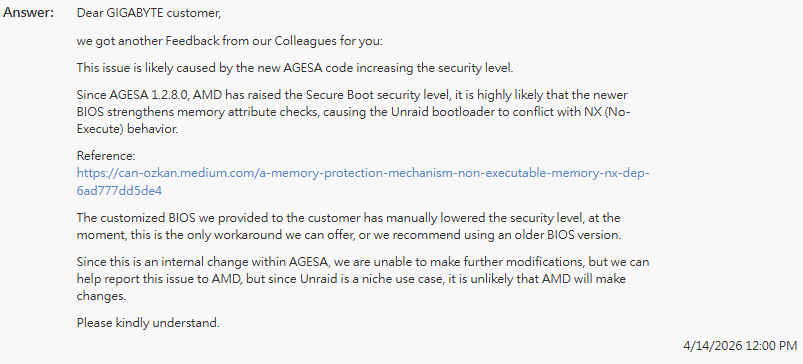
Yep, this was also the feedback I got from unraid. But just to add to the topic, I did receive a custom bios from gigabyte based of F42a, which allowed me to boot with the existing bootloader. Here is the message I received after confirming that this modified bios worked;
-
I actually think this needs to be bumped all the way to the top, because there are going to be support tickets coming left and right! I can confirm this issue also affects the Gigabyte X670E AORUS Master, and the failure goes beyond just blocking USB boot. After updating to F42a, Unraid would no longer boot from USB. Rolling back to F41 did not fix it. Only after downgrading to F39 was I able to boot Unraid again. Here’s the BIOS progression: F42a (Mar 2026) AGESA 1.3.0.0a DDR5 vulnerability fix (CVE‑2025‑6202) Result: Unraid USB will not boot. Additional issue: All front‑panel USB ports became unstable. I could not reliably format, flash, or write to any USB drive connected to the case ports. Attempts to repair the Unraid boot device on those ports failed completely and even caused corruption. Only the rear motherboard USB ports were stable enough to restore the boot device. F41 (Feb 2026) AGESA 1.2.8.0 Result: Unraid USB still will not boot. F39 (Dec 2025) Pre‑2026 AGESA Result: Unraid boots normally again. USB ports behave normally. Based on this, it appears that all 2026 BIOS releases for this board break UnRaid USB booting and likely also other AMD AM5 boards, likely due to AGESA changes and new security hardening. The USB instability in F42a suggests deeper changes to the USB initialization stack, not just the bootloader path. For anyone troubleshooting similar symptoms: F39 is currently the last known‑good BIOS for Unraid on the X670E AORUS Master. I've sent out a message to LimeTech and will also send out a message to gigabyte regarding this problem.
-
I upgraded to 7.0.0-beta.1, and can confirm, backup is now running normally again. Still a bit confusing how 6.12.10 broke what used to be working, but I'm happy that all is back to normal working order!
-
What I meant is how can I get / know when I will receive the newest kernel. Will the kernel be updated in conjunction with unraid 6.13? I completely misread your message! You meant Unraid 7.0.0, gotcha! That is indeed a much newer kernel (currently at 6.1).
-
Is the kernel/KVM releasing with Unraid 6.13? Than I will make note of it and test again after it has been released. Ps. I've just checked my logs once more; and I spotted the kernel/KMV error message; Jun 21 13:59:50 un1ty kernel: SVM: kvm [17169]: vcpu1, guest rIP: 0xfffff85876eb30ec unimplemented wrmsr: 0xc0010115 data 0x0 However it has been running for 6 hours after the message popped up.
-
So the tests I have performened kind of rules out the following issues: It's not hardware (load) related. It's not ZFS related. I've tried with and without ACS with no fix, so it's not ACS related. I had to re-enable it in the end because my network connection is shared with my most important USB ports.... So the issue I'm experiencing is confined to the VM. So the KVM would be my main suspect. Would de-anonymization help with debugging the problem? I'm so happy finding a weird edge case problem on a system that I use on a daily base... NOT 😅! Not complaining to the unraid developers/community, I'm a (embedded) software developer myself so I fully understand how difficult it can be. But this really is an issue that can pop up for anyone at some point. I'm perfectly okay with being on a call with a developer troubleshooting this, because it's the only thing from keeping me the VM as a all-day operating system.
-
So far I've tried the following without causing the system to crash, all while the Windows VM was online: Created a new share on both the flash and disk zpools (temp_src and temp_dst resp), and copied all of the drive's content onto the flash share. Copied using the unraid WebGUI from temp_src to temp_dst Created a 7z archive, using '7z a -t7z /mnt/tank/tmp_dst/D.7z /mnt/flash-tank/tmp_src/D' Moved the content onto the share/dataset 'flash-tank/domains/Windows 11' where the vdisk images also reside, and created a 7z archive to dataset 'tank/backup/01_Disk/' where the backups are normally stored stored. using '7z a -t7z /mnt/tank/backup/01_Disk/D.7z "/mnt/flash-tank/domains/Windows 11/D"'. Creating the archives fully loaded up the isolated CPU cores, and I even attempted to put some extra load on the system while the it was creating the archives, by running cinebench for and crystal disk mark. But none of it caused the system to even hitch, file copies were a bit slower, but that was to be expected copying small files onto a spinning rust.
-
I have copied the vdisk images before in the same way, even recently after the problems arrose, without problems (at 600+MB/s, so decent performance). I suppose I can place the contents of vdisk2 onto a share on flash based zfspool and copy it to the harddrive based zfspool, so it would include more random IO. Would that suffice as a test?
-
How would I troubleshoot this any further? I have even tried setting up a 'clean' Windows VM from the template, using only the options given from the form (no edits in the xml. But that did not solve the issue.
-
tl:dr in bold. So I've been working all day in the VM without issues (12 hour uptime) before I turned off ACS, using the SVN repo that would cause the crash if it was included in the backup. Then I did a complete SVN clean and check the repo status to make sure there are no inconsistencies / weird things going on. Then I disabled ACS. After which I restarted the server twice just to make sure everything was in working order, then I repeated the same steps I did before: Add the folders containing the SVN repo(s) back into the backup schedule, and perform the backup. But with no succes, the system once more crashed. Then booting up after the crash, I removed the SVN repo from the backup and ran the backup once more, but this time it finished backing up succesfully. I also tried to backup the repo folders containing only the .svn folder without the contents, and this also fails. To me this really seems like a bug in either the unraid kernel or the filesystem, and not necessarily a hardware fault. ZFS is relatively new in unraid, maybe there is an edge case where ZFS is running out of memory because it attempts to deduplicate as much as it can? it's a SVN repo with a lot of repeating externals (jay for legacy code/systems). I've added diagnostics, but there is nothing on there that jumps out to me that indicates what caused the fatal error. un1ty-diagnostics-20240617-2204.zip
-
Yes, I have had ACS override enabled since the beginning, because it wasn't able to detect my onboard wifi otherwise. Is ACS override something that could affect from within the VM over time (driver updates etc)? Since 'on the outside' of the VM, nothing has changed other than unraid updates. However, given the timeframe, it did start occuring right around the time 6.12.10 became available? List of the hardware (note, apart from the SSD's these were all bought Q3-Q4 of 2024); AMD Ryzen 9 7950X3D Gigabyte AORUS X670E MASTER Gigabyte GeForce RTX 4060 Gaming OC 8G (VM passthrough) 4x Toshiba MG07ACA12TE (512e), 12TB (ZFS pool 2) 1x WD Red Plus "5400rpm class", 14TB (unassigned, cold spare) G.Skill Flare X5 F5-6000J3038F16GX2-FX5 (2x 16GB DDR5 6000 CL30, plan on switching to 96GB so ZFS can use more for ARC) FSP Hydro Ti PRO 850W 3x Samsung 970 Evo Plus 1TB (ZFS pool 1) 1x Samsung 980 Pro 1TB (baremetal windows installation) Gigabyte GC-TPM2.0 SPI 2.0 I specifically picked the core components for longevity (or at least didn't cheap out on), so being barely 6 months old for the most part, component failure feels unlikely. Especially given that it was running for months without failure beforehand, with uptimes of +2 weeks at given times and the fact that all the stress tests that I threw at it (and can still perform without issue). Ps. I wouldn't exactly call it 'server restarting', it's almost as if someone pressed the hardware reset button on the motherboard. But instead it seemes to be caused by some software interaction (in this case IO operations). I would almost compare it to a hardfault on embedded systems, like div0 or segmentation fault, based on how (sudden) it occurs. Edit: I don't need the WiFi/bluetooth passthrough anymore right now, I will give it a try tomorrow with ACS disabled and check if it solves anything. Unless you have another idea.
-
The thing is, none of the drives report any smart issue. I also ran multiple benchmarks (furmark, memtest, cinebench, crystaldisk mark) for hours without any instability, because I also assumed it was hardware related. Baremetal Windows runs just fine, and as long as I don't use the Windows VM, unraid is stable as well (with HA VM and plex, sonarr, radarr dockers etc.).
-
Hi all, I've setup my unraid system in December and have been mostly happy about how it performed. However, I didn't like the IO performance of the of the unraid array, so in January I switched over to ZFS pools and it was running 100% stably for the first 4 months. However recently I've been experiencing sudden system crashes and haven't been able to pinpoint what is causing the problem, but can reproduce it quite easily. In my setup I have the following: ZFS pool 1: 3*1TB Samsung 970 SSD (zraid) ZFS pool 2: 4*12TB Toshiba MG07 HDD (zraid) For my Windows VM I'm using 2 qcow images on pool 1, vdisk1 for the operating system and vdisk2 for data/game storage. I use EaseUS todo backup to create separate backups of the 'drives' from inside the VM onto pool 2, I use this instead of snapshots because I can do this while the VM is running + I use it as a base image/template for creating new Windows VM's. Also it allows me to synchronise data between my VM and the baremetal Windows installation on a 4th SSD inside the system. However recently the system started crashing (immediate power down, back to bios) while creating a backup. The vdisk1 backs up without any issues, but during the backup process vdisk2 the system crashes around 90% progress. Note that the backup of vdisk2 is a file backup, not a drive backup. What I've found is that this is happening while it is in the process of backing up a SVN repository I have stored on that drive. If I exclude that folder the backup finishes succesfully again, which is odd because that repository has been on the drive since the beginning and hasn't caused any problem before. Also this isn't the only time the system crashes, but the most common one, it also (irregularly) happens when I play a game which is also stored on vdisk2. What I have tried to troubleshoot the problem so far: - Restore to an older backup of vdisk2 (~2 months old, far before the problems started) - Scrub both pools (no errors found) - Qemu-img check -r all (no errors found) - Performed chkdsk from within the VM (no errors found). - Create a new vdisk and restore data of vdisk2 I'm at a dead-end and can't think of anything else that could cause &| fix the problem. My gut feeling is that it has to do with the ZFS pool itself, and scrub is not properly finding and repairing problems (unlike the normal raid integrity checks).
-
I have the same problem, however I see many warnings that ZFS is not available on the newer kernels.. So I'm afraid I'm stuck at the default 6.1.74 kernel with Unraid 6.12.8. Or do you have other experiences?
-
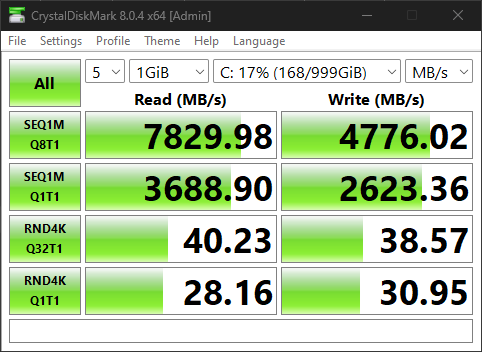
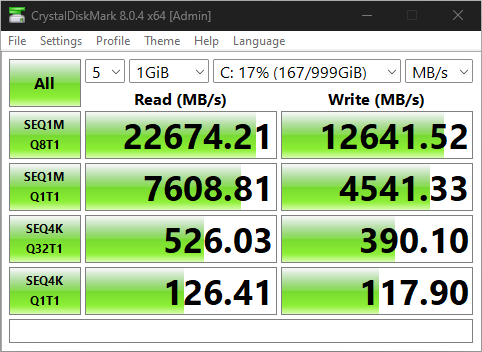
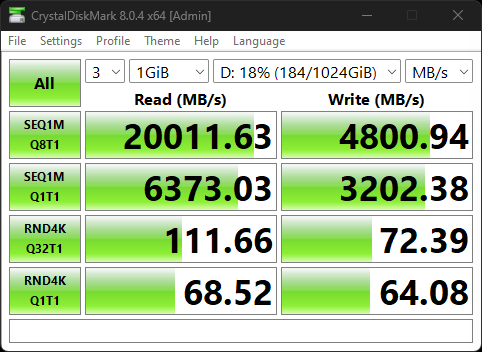
Also to update from my original post at Original performance (cpu mode passthrough): Same configuration (cpu mode QEMU64): Current configuration (cpu mode passthrough, tuned) is attached. sequential is much better, but random IO barely doubled, where as it should have been closer to 6x or above to approach baremetal.