




nick5429
Community Developer
-
Joined
-
Last visited
-
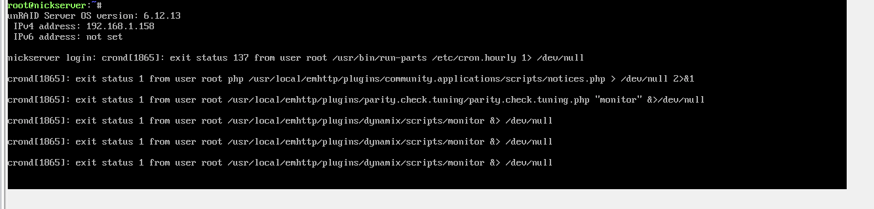
System: Supermicro X8DTE-F, 24GB ram, Xeon L5640 HBA330, bunch of spinning data drives, 1 out-of-pool SSD for misc tinkering and docker storage At least once a week lately, my system will completely hang and be unresponsive to any input. No unraid networking page, nor even respond to physical keyboard attached. Cursor doesn't blink, "enter" doesn't insert a new console line, numlock doesn't toggle, etc. This time, it happened when I was starting a VM which triggered the OOM process. Frequently other times, it will happen 'randomly' as far as I can tell, though with indications an OOM was involved. I'm not sure this even makes a ton of sense outside of this VM-induced crash today, as generally I run no VMs and just typical collection of dockers with 24GB of RAM. `free -m` would typically show at least 1+GB completely free and ~8GB buffered/cached which could be reclaimed under memory pressure rather than killed-for. Aside: I'm playing around with ZFS pools on the 'cache' mount, but is used only as a data drive/pool. I'm unconcerned about associated reported errors in the syslog. Various zfs things use 10-12GB, but nevertheless -- an OOM event should not cause a complete system hang [especially the more routine 'random' ones that aren't requesting 8GB all at once, which aren't captured here] Diagnostics attached; syslog mirrored to flash and captured in diagnostics Screenshot from IPMI "physical console" showing some killed when hung It looks like process 'unraid-api' gets killed at some point; is that a noteworthy problem? nickserver-diagnostics-20240911-0957.zip
-
Another temporary workaround which will allow you to examine things while debugging is to increase the size of the "/var/log" ramfs filesystem: # increase tmpfs for logging mount -t tmpfs tmpfs /var/log -o size=1G,remount
-
I have a proof-of-concept script here which pulls info from Plex's "on deck" API, and remaps the file paths from my docker's paths back into my unraid filesystem paths. I haven't integrated any of this into the actual preloading script You'll need to get your plex API token; a "temporary" token is pretty easy and straightforward to get, see https://support.plex.tv/articles/204059436-finding-an-authentication-token-x-plex-token/ IIRC, these temporary tokens still maybe last 'a while'/long enough to be useful beyond just development? #!/bin/bash # Plex server details PLEX_URL="http://192.168.1.10:32400" API_KEY="" # Define the path mappings declare -A path_map=( ["/Movies/"]="/mnt/user/Movies/" ["/TV-Kids/"]="/mnt/user/TV-Kids/" ["/TV-CurrentShows/"]="/mnt/user/TV-CurrentShows/" # Add more mappings as needed ) # Define the video file extensions video_ext='avi|mkv|mov|mp4|mpeg' # Function to remap file paths remap_path() { local original_path="$1" for prefix in "${!path_map[@]}"; do if [[ "$original_path" == "$prefix"* ]]; then # Replace the prefix with the mapped path echo "${original_path/$prefix/${path_map[$prefix]}}" return fi done # If no mapping found, return the original path echo "$original_path" } # Function to get "On Deck" items from Plex and process file paths get_ondeck() { local plex_url="$1" local api_key="$2" # Query the On Deck list from Plex local plex_on_deck_url="$plex_url/library/onDeck?X-Plex-Token=$api_key" # Get the list of On Deck items (assumed response in XML format) local response=$(curl -s "$plex_on_deck_url") # Parse the XML response and extract the full file paths from <Part> tags local video_files=() while IFS= read -r line; do # Dynamically create a regular expression using the video_ext variable local file_path=$(echo "$line" | grep -oP "(?<=file=\")[^\"]+\.($video_ext)\"") if [[ -n "$file_path" ]]; then # Remove trailing quote that gets included file_path=$(echo "$file_path" | sed 's/"$//') # Remap the file path using the remap_path function local remapped_file_path=$(remap_path "$file_path") video_files+=("$remapped_file_path") fi done < <(echo "$response" | grep -oP '<Part[^>]*file="[^"]*"') # Output the array elements, one per line printf "%s\n" "${video_files[@]}" } # Get and print the remapped On Deck video files echo "Remapped On Deck video files:" # Capture the output of get_ondeck into an array called "ondeck_files" mapfile -t ondeck_files < <(get_ondeck "$PLEX_URL" "$API_KEY") # Print the remapped file paths printf "%s\n" "${ondeck_files[@]}"
-
And if that doesn't work, let us know what filesystem you were using. If it was xfs and not working with the mount command above, show the output of this command [changing the /dev/sdd to the device you are working on]: head /dev/sdd | xxd | grep XFSB
-
I agree completely, and the response here has been pretty indifferent and the issue ignored. Not great. Anyway see my response in the bug, but TL;DR for anyone encountering this: try mounting the partition with -o offset=0, or the disk with -o offset=32768. In my case: mount -t xfs -o offset=0 /dev/sdd1 /tmp/is-disk6/
-
fwiw this post isn't me; appears somebody else had this same problem:
-
I'm on 6.12.11 Docker start command shows as: docker run -d --name='binhex-sickchill-fresh' --net='bridge' -e TZ="America/New_York" -e HOST_OS="Unraid" -e HOST_HOSTNAME="nickserver" -e HOST_CONTAINERNAME="binhex-sickchill-fresh" -e 'UMASK'='000' -e 'PUID'='99' -e 'PGID'='100' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:8081]/' -l net.unraid.docker.icon='https://raw.githubusercontent.com/binhex/docker-templates/master/binhex/images/sickchill-icon.png' -p '8091:8081/tcp' -v '/mnt/user/appdata/data':'/data':'rw' -v '/mnt/user':'/media':'rw' -v '/mnt/disks/SanDiskSSD/appdata/binhex-sickchill-fresh':'/config':'rw' 'binhex/arch-sickchill' Manually running /home/nobody/start.sh didn't give me any additional info beyond the prior 'illegal instruction' Redirecting the config/install dir back onto /mnt/user/appdata didn't change anything
-
A brand new copy of this container with none of the default populated settings changed, into a blank config directory, fails in exactly the same way on my system Copying my full config directory and pointing the latest top of tree version of the LSIO sickchill container at it seems to work
-
Created by... ___. .__ .__ \_ |__ |__| ____ | |__ ____ ___ ___ | __ \| |/ \| | \_/ __ \\ \/ / | \_\ \ | | \ Y \ ___/ > < |___ /__|___| /___| /\___ >__/\_ \ \/ \/ \/ \/ \/ https://hub.docker.com/u/binhex/ 2024-07-25 14:24:41.201040 [info] Host is running unRAID 2024-07-25 14:24:41.257635 [info] System information Linux 12937845fbd7 6.1.79-Unraid #1 SMP PREEMPT_DYNAMIC Fri Mar 29 13:34:03 PDT 2024 x86_64 GNU/Linux 2024-07-25 14:24:41.311686 [info] PUID defined as '99' 2024-07-25 14:24:41.401049 [info] PGID defined as '100' 2024-07-25 14:24:41.495063 [info] UMASK defined as '000' 2024-07-25 14:24:41.545407 [info] Permissions already set for '/config' 2024-07-25 14:24:41.630897 [info] Deleting files in /tmp (non recursive)... 2024-07-25 14:24:42.005329 [info] Starting Supervisor... 2024-07-25 14:24:42,748 INFO Included extra file "/etc/supervisor/conf.d/sickchill.conf" during parsing 2024-07-25 14:24:42,748 INFO Set uid to user 0 succeeded 2024-07-25 14:24:42,757 INFO supervisord started with pid 7 2024-07-25 14:24:43,759 INFO spawned: 'start-script' with pid 47 2024-07-25 14:24:43,760 INFO reaped unknown pid 8 (exit status 0) 2024-07-25 14:24:44,762 INFO success: start-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2024-07-25 14:24:45,028 DEBG 'start-script' stderr output: /home/nobody/start.sh: line 7: 49 Illegal instruction "${install_path}/bin/sickchill" --config /config/config.ini --datadir /config 2024-07-25 14:24:45,028 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22418072691408 for <Subprocess at 22418073011728 with name start-script in state RUNNING> (stdout)> 2024-07-25 14:24:45,028 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 22418085474448 for <Subprocess at 22418073011728 with name start-script in state RUNNING> (stderr)> 2024-07-25 14:24:45,028 WARN exited: start-script (exit status 132; not expected) 2024-07-25 14:24:45,029 DEBG received SIGCHLD indicating a child quit Docker fails to start I rolled back to binhex/arch-sickchill:2024.2.18-01 a while back; tried again today and it's still failing
-
Thanks for clarifying It would be great to have this documented much more clearly/prominently and explicitly, since in other places IIRC parallels are/were drawn between the prior concepts of 'cache' and 'main unraid array' as 'pools'. If that were the case, then what I was originally trying to do ought to have been possible
-
That doesn't, and shouldn't, make a difference. After making your suggested change and rebooting: I don't mean to offend -- but can I get clarity from someone else who confidently knows the correct answer to the core question here? Is this actually possible? I'm surprised that I haven't been able to find anyone else either asking this question or trying but failing to accomplish this.... Diagnostics attached nickserver-diagnostics-20240216-1838.zip
-
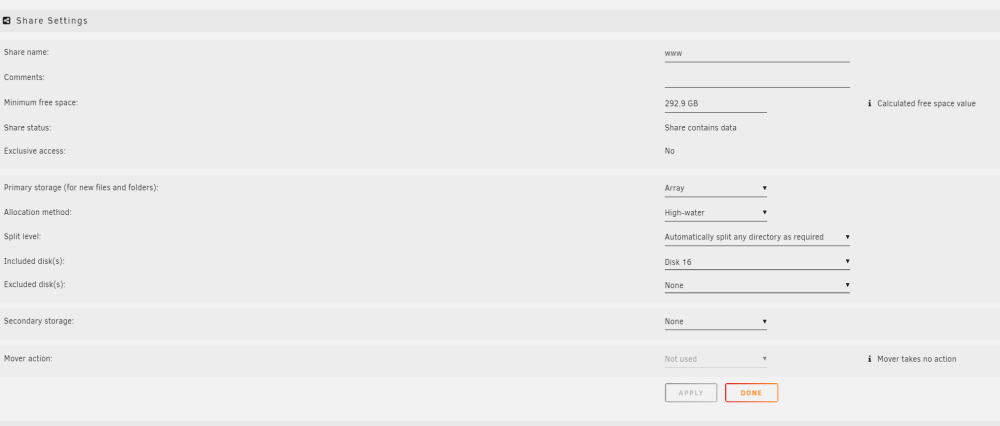
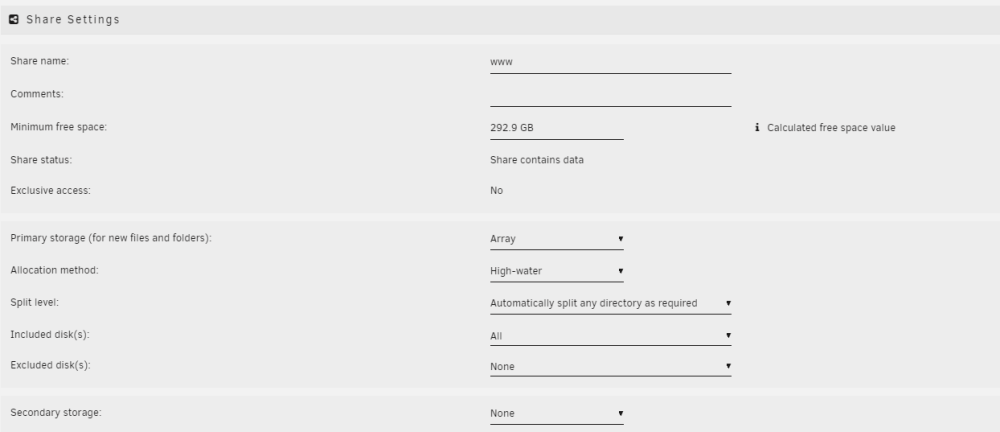
I'm talking above about read-only scenarios where my server has become nearly unusable. The write parity mechanism isn't coming into play. Accessing the data I mentioned above using direct disk shares alleviates many of the problems, but I'm not interested in trying to memorize which shares belong on which disks just to use them without twiddling my thumbs while I wait for a directory listing. # ls -d /mnt/*/www /mnt/disk16/www/ /mnt/user/www/ /mnt/user0/www/ This extremely simple share stored entirely on disk16, and won't mount with 'exclusive access'. Should it be able to, or am I wasting my time trying to get this working with data on the regular unraid pool?
-
My reading of the exclusive shares and 'pools' concepts in the release notes implied that the 'array' was a pool, largely like any other pool. If I have ALL of the data for a share on a single disk, on the regular unraid array (along with the other usual conditions) -- is it eligible to be mounted as an 'exclusive share'? I have several shares which I have worked to reorganize onto a single disk, inside the regular pool. NFS is disabled both on the shares, and globally. No data for those shares exists on other disks, nor empty directories. The shares still do not mount as 'exclusive share'. Performance even of browsing directories through shfs has gotten atrocious. I can't even stream a single moderate-bitrate video through a user share over samba while simultaneously browsing directories on completely separate disks via user share, without the video skipping and buffering.
-
Updated, and get no errors on boot with the new version. Haven't testing anything beyond that. But thanks!
-
I had created a set of directories holding my various plugins, to try to iteratively enable some and track down a bug. One of the folders had a space in the name: "newly enabled". Plugins cannot be installed from this folder when files within it are picked using the WebUI's file picker; the popup complains "plugin: newly is not a plg file". Screenshots clearly illustrate the problem. Input string needs quoted? Not going to bother posting diagnostics, it's irrelevant




