

wsume99
-
Posts
531 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by wsume99
-
Did you leave the jumper on? I think you just need to jumper the pins for a very short time.
-
Thanks for the explanation. That is exactly how I imagined that it worked. That explains why the update frequency slows as the reading of the disk progresses and the read rate slows.
-
Well I'm RMAing the drive. I let the 3rd preclear attempt run for two hours and I'm only at ~37GB out of 2TB read. That's an average read rate of ~5 MB/sec. At that rate it would take almost 5 days just to complete the pre-read of the drive! Not to mention the fact that I have thousands of lines worth of read errors being reported in the syslog. But my real question is I'm wondering how the preclear script determines what frequency to update the display? That is what really threw me off at the beginning. I'm accustomed - based on what I've seen from previous preclear cycles on other drives - to seeing the display refreshed with new data (bytes processed, drive speed (MB/sec), drive temperature, and elapsed time) at a regular frequency. However when running my first preclear I initially thought that something was wrong with the preclear script because the data did not update for more than 10 minutes before I eventually killed the process. It seems like when it encountered the "bad" area on my new drive the frequency of screen refreshes drastically changed. During the first four minutes when the drive appeared to be behaving normally the data would be refreshed about every 30-40 seconds until about 4:15 (~27GB read) then the process appeared to be hung because no updates were being displayed. Even if there was little to no progess in the number of bytes processed due to the read errors I would still expect to see the elapsed time increment at a regular frequency. It wasn't until the third preclear cycle that I decided to just let the process run for a while that the display was eventually refreshed with new data at something like 25 minutes elapsed time and then again about every 20 minutes thereafter. This was not a situation I had ever encountered before although I have read about drives being "hung" during preclear. So perhaps a little ignorance combined with some impatience lead me to the wrong conclusion - i.e. thinking something was wrong with the preclear script. But it certainly would have been more helpful if at least the elapsed time counter would have kept refreshing at a more reasonable frequency (i.e. every 1-2 minutes). That way I would have at least known that the process was still operating and not "hung". PS - Sometimes its hard to be patient when your wife is asking "I thought this was only going to take 10 minutes."
-
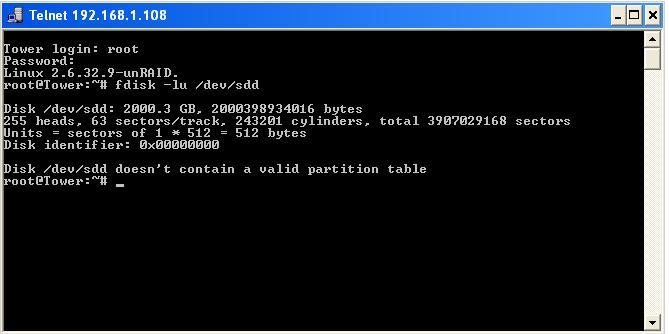
I checked my power connection and replaced the sata cable and started another preclear. It froze at basically the same point again. This drive is now 3 for 3. I'm starting to see a pattern here. It does respond to the fdisk command. I attached a screen shot of the response. I also got a few read errors from the second preclear process... Feb 28 18:34:59 Tower kernel: sd 3:0:0:0: [sdd] Unhandled error code Feb 28 18:34:59 Tower kernel: sd 3:0:0:0: [sdd] Result: hostbyte=0x00 driverbyte=0x06 Feb 28 18:34:59 Tower kernel: sd 3:0:0:0: [sdd] CDB: cdb[0]=0x28: 28 00 03 66 19 48 00 01 00 00 Feb 28 18:34:59 Tower kernel: end_request: I/O error, dev sdd, sector 57022792 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127849 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127850 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127851 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127852 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127853 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127854 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127855 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127856 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127857 Feb 28 18:34:59 Tower kernel: Buffer I/O error on device sdd, logical block 7127858 I've gotten similar errors from the thrid cycle so far as well ... Feb 28 19:07:18 Tower kernel: sd 3:0:0:0: [sdd] Unhandled error code Feb 28 19:07:18 Tower kernel: sd 3:0:0:0: [sdd] Result: hostbyte=0x00 driverbyte=0x06 Feb 28 19:07:18 Tower kernel: sd 3:0:0:0: [sdd] CDB: cdb[0]=0x28: 28 00 03 67 a0 48 00 01 00 00 Feb 28 19:07:18 Tower kernel: end_request: I/O error, dev sdd, sector 57122888 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140361 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140362 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140363 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140364 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140365 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140366 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140367 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140368 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140369 Feb 28 19:07:18 Tower kernel: Buffer I/O error on device sdd, logical block 7140370 I'm going to just let this preclear run for a while, maybe overnight, and see what happens. I'm thinking that I'll probably RMA this drive based on what I see so far. Is there something else I should check before doing that?
-
Sorry, you read the post before I corrected my typos. The preclear was hung at 1% and not progressing. The time and bytes read counters were not incrementing either. I stopped the array and rebooted. Switched back to preclear v1.6 and launched another preclear. This time I'm getting essentially the same result. Now hung at 4:09 & 1% complete. I've never had a drive get hung in the preclear process. Is this a sign of a bad drive or something else?
-
I just updated to unRAID 4.7 and also dumped the new preclear script (v1.7) onto my USB dive as well. I launched a preclear cycle on my new WD20EARS drive using the -A option and NO jumper installed. The preclear in now hung at 1% complete (time=4:17). The drive responds to smart status requests using the unMenu Disk Management page. I do not see any errors in my syslog either but there is a message about an unknown partition table on the drive in question (sdd). What should I do? syslog-2011-02-28.txt
-
How to change motherboard to another on a running unraid server???
wsume99 replied to Lappen's topic in Motherboards and CPUs
And don't forget that you'll need to setup the BIOS correctly for your new MB on first boot. SATA to AHCI mode and boot from USB. -
I've been seeing lots of PVR activity in the XBMC forums the past few weeks actually. I think it even comes standard on version 10.x. I'll have to look into that then. I really want to have a single solution to my media needs. The WAF would increase substantially.
-
I'm actually in the middle of that struggle now myself. I have used Media Browser but I prefer XMBC for the following reasons... 1. Better GUI 2. Highly customizeable 3. The scrapers seem to work a lot better than WMC or Media Browser 4. Upconverts SD DVDs to 1080p reasonably well (not perfect but it's better than WMC or Media Browser) 5. Large user base with good support forums The biggest downside to XBMC is that is does not have PVR capability but the developers are working on that and I think there is a beta version out there. Once the PVR capability is there I'll ditch WMC and use XBMC only.
-
What the heck are you waiting for, come join the fun, we're always looking for ways to increase the size of our tax base.
-
Which 2 TB drive should I buy?
wsume99 replied to Rajahal's topic in Storage Devices and Controllers
I bought a bag of them at Frys Electronics LOL - You make it sound like you're planning to build a server farm. I got a few (~10) for free from my local PC shop. -
I don't know - I've never tried that. I just pulled off the SATA cable and then reconnected it after I was done.
-
Not sure. I'm using a Wolfdale CPU (E5500) in my C2SEE and it works just fine. From what I can see the only difference is that your CPU has a higher clock speed. I don't see why that would make it incompatible.
-
n00b question: chkdsk or preclear?
wsume99 replied to hklt's topic in General Support (V5 and Older)
Holy #$)%!! And I thought that it was overkill when I ran a 2TB drive through 4 cycles once. Just wondering, do most bad drives get discovered right away or do you find drives that looked perfect through 3+ preclears and then on the 4th, 5th, or 6th run suddenly look bad? -
Sounds like a very good plan to me. I think you'll be surprised how much fun you'll have building your own server. You're welcome.
-
You answered your own question there. DDR2 vs. DDR3 is just a matter of what you have laying around. There is no performance difference in unRAID. If you don't have any DDR2 laying around that you can use then go with DDR3. In my opinion people are much more likely to write a review if they've had a problem with a product. So for a product like a 1TB or 2TB HDD that Newegg has probably sold tens or hundreds of thousand units of I'd expect for there to be a lot of bad reviews. All HDDs will eventually fail. The best thing to do is run pre-clear on any drive before installing it into your array. That will hopefully detect any suspect drives from the get go. Then continue to monitor its health as you use it. That way hopefully you'll detect the drive starting to go bad before it causes any major problems. I've purchased 4 WD green drives in the last 6 months and I had to RMA one because it was a little suspect during pre-clear. Getting a DOA or early failure seems to be the norm now for all HDD mfgs. But isn't this one of the reasons why you're using unRAID - to minimize the impact of a HDD failure?
-
I have that MB and the manual says that a continuous beep code is a System Overheat error. Is your CPU fan plugged in and spinning?
-
You could check out Raj's prototype design thread for some more info on sample builds. I think he keeps it pretty up to date WRT including MBs that are available.
-
The label on the psu should tell you how many 12v rails you have. There will be a column labeled +12v for each rail showing its capacity ... one column = single rail, two columns = two rails, etc. In any case, if you are going to start with three drives your current psu should be up to the task. Short answer is green drives will be fine. 7200 rpm drives will give you a little faster parity check and maybe a slightly higher data transfer rate but nothing real significant. They will also cost more, produce more heat, and use more power. I have all green drives in my server and it works great for me.
-
n00b question: chkdsk or preclear?
wsume99 replied to hklt's topic in General Support (V5 and Older)
Yes you can do that. I have done it personally. Like prostuff1 said just be careful to make sure you are preclearing the right drive otherwise you'll be reinstalling windows after the preclear is done. -
LOL - I started my array with a 13GB IDE drive and a 160GB SATA I drive and no parity. Now I have all 1TB & 2TB WD Green drives in there. They are really quiet, use little power, and are easy to work with when it comes to advanced format drives. (Although it sounds like that last benefit will be of little value when 5.0 released.)
-
Ignorance is bliss comes to mind. You should follow madpoet's advice and read the threads he mentioned.
-
I would take the advice from the HW compatability page and stay away. Should work fine but you'll need to use one of those old video cards and I'm not sure how well the onboard NIC will perform. An Antec tower (300,900,1200) will work fine. The PSU might be another story. Is this a single rail PSU? If not then you might consider getting one that has a single 12v rail. If you're only going to use just a few drives then it probably won't matter much but as you add more drives it is possible to overload a multi-rail PSU eventhough you are well below its rated watt output. I have powered five green HDDs with my Antec Earthwatts 430 PSU which has 2 12v rails. So it is possible to use a multi-rail PSU (with a few drives) but I just wanted to warn you. If they are SATA drives and they are still under warranty then I'd at least run a preclear cycle on them. If you discover that they are failing or at least something in the SMART report gives you confidence that they are flaky then you could RMA them. There is a chance that the mfg might give you a larger HDD in return (maybe a 500GB if you keep your fingers crossed). Just my 2 cents -- If I was in your position I would use the free copy of unRAID and throw together a server using the components that you have on hand. You'll learn a lot about unRAID in the process and if you decide that your current HW cannot satisfy your needs then you'll be better educated on unRAID and be able to properly select the components you need. This is the path that I followed and I must say that my thoughts about what I wanted to do with my server changed as my knowledge of unRAID matured. Had I bought new HW right off the bat I might have chosen something that would not have suited my eventual needs once I understood all the things I can do with unRAID. So if you have the time and the spare HW I would give that a shot before buying anything. Once you have a running system it's easy to upgrade/swap out any component - even the MB. I'm on my 4th MB now.
-
I'm not surprised to hear you say that. It seems that you have a PC building addiction/fettish. Not that that's a bad thing. Hey there's an idea. Maybe Tom needs to add a "support" section in the forums (a la Alcoholics Anonymous) for help with PC related addictions. Perhaps just start with two sections - digital hoarding and compulsive PC construction.
-
It runs in a DOS environment. All you need to do is create a DOS-bootable USB drive and place the wdidle3 application on it (google wdidle3 for more info). Then power down your unraid server and disconnect all non WD drives and any WD drive that you do not want to disable head parking on. Replace your unRAID USB drive with the DOS-bootable drive that you created. Disable the idle3 timer and confirm (use -R command) that it was disabled (again use google). Power down, reconnect HDDs that you disconnected, replace unRAID USB drive and reboot into unRAID. I did exactly this on all 3 of my EARS drives (1x1TB ans 2x2TB) and they all worked fine. It doesn't matter if you have already used them in the unRAID server. I don't think so but there is no need to do that if you do as I recommended above.
