




sol
Members
-
Joined
-
Last visited
Everything posted by sol
-
FIXED 9/1/2025. See below. ---------------------------------- Tried to update and now it won't start. Shows foundry.domainname.com/auth as the URL and just Internal Server Error in the body of the page. Log has; Error: Failed to lookup view "auth" in views directory "/foundry/fvtt/resources/app/templates/views" at Function.render (/foundry/fvtt/resources/app/node_modules/express/lib/application.js:597:17) at ServerResponse.render (/foundry/fvtt/resources/app/node_modules/express/lib/response.js:1048:7) at AuthView.handleGet (file:///foundry/fvtt/resources/app/dist/server/views/auth.mjs:1:684) at Layer.handle [as handle_request] (/foundry/fvtt/resources/app/node_modules/express/lib/router/layer.js:95:5) at next (/foundry/fvtt/resources/app/node_modules/express/lib/router/route.js:149:13) at Route.dispatch (/foundry/fvtt/resources/app/node_modules/express/lib/router/route.js:119:3) at Layer.handle [as handle_request] (/foundry/fvtt/resources/app/node_modules/express/lib/router/layer.js:95:5) at /foundry/fvtt/resources/app/node_modules/express/lib/router/index.js:284:15 at Function.process_params (/foundry/fvtt/resources/app/node_modules/express/lib/router/index.js:346:12) at next (/foundry/fvtt/resources/app/node_modules/express/lib/router/index.js:280:10) at file:///foundry/fvtt/resources/app/dist/server/express.mjs:1:4115 at Layer.handle [as handle_request] (/foundry/fvtt/resources/app/node_modules/express/lib/router/layer.js:95:5) at trim_prefix (/foundry/fvtt/resources/app/node_modules/express/lib/router/index.js:328:13) at /foundry/fvtt/resources/app/node_modules/express/lib/router/index.js:286:9 at Function.process_params (/foundry/fvtt/resources/app/node_modules/express/lib/router/index.js:346:12) at next (/foundry/fvtt/resources/app/node_modules/express/lib/router/index.js:280:10) UPDATE: I grabbed the latest linux zip from Foundry and unzipped it with the console in Unraid in the Foundry config path and restarted and it booted right up. No idea what happened, but it is working. UPDATE 2: I spoke too soon. If I try to launch any worlds it crashes the server and when rebooted comes up at a critical failure screen. Will wait for guidance on what to do next. Feel like I'm spinning my wheels. UPDATE 3: I'm impatient. I deleted everything in the appdata path and re-downloaded the zip thinking something was corrupted on installation. I was right. Server boots and worlds boot.
-
Updated today to Linuxserver.io version: 3.0.1-ls348 Build-date: 2025-01-03T16:01:30+00:00 All services are down due to emergency error (contoso.com in place of my real domain); 2025/01/03 13:33:59 [emerg] 1131#1131: cannot load certificate "/etc/letsencrypt/live/contoso.com/fullchain.pem": BIO_new_file() failed (SSL: error:80000002:system library::No such file or directory:calling fopen(/etc/letsencrypt/live/contoso.com/fullchain.pem, r) error:10000080:BIO routines::no such file) The fullchain.pem file has not changed and is in the correct location. I reverted to 3.0.0-ls336 as I noticed that the certbot version was changed in the release notes after this version. Services have returned. Please update this thread when this issue is fixed so that I can revert to current updates. Thanks!
-
Mullvad killed port forwarding this month. Didn't know about it until today when things didn't seem to be working right. Privoxy stopped functioning, for some reason, when port forwarding was removed? They said they were removing it July 1 but things didn't break until today. I redownloaded the wireguard config and everything seems to be running again. How bad is not having port forwarding going to screw me? Is it mostly torrent speeds?
-
NEVERMIND. Fixed. Bazarr doesn't allow any special ways of excluding IPs for privoxy. You have to list each IP separately. No wildcards, no CIDR. I'm an idiot and can't read. I'm having this same issue. Bazarr has stopped working because it can't connect to Sonarr or Radarr even though I've told it to exclude those IPs. When I test Bazarr's communication to Sonarr or Radarr it times out on port 8118 which is Privoxy. If I turn off Privoxy in Bazarr it works fine. I like having all my arr traffic going through my VPN but it just doesn't seem to want to work for Bazarr. Are there more ways to test Privoxy?
-
New email from Google. Anyone else get this? Anyone figured out how to proceed? (edited out some identifying content) Our records indicate you have OAuth clients that used the OAuth OOB flow in the past. Hello Google OAuth Developer, We are writing to inform you that OAuth out-of-band (OOB) flow will be deprecated on October 3, 2022, to protect users from phishing and app impersonation attacks. What do I need to know? Starting October 3, 2022, we will block OOB requests to Google’s OAuth 2.0 authorization endpoint for existing clients. Apps using OOB in testing mode will not be affected. However, we strongly recommend you to migrate them to safer methods as these apps will be immediately blocked when switching to in production status. Note: New OOB usage has already been disallowed since February 28, 2022. Below are key dates for compliance September 5, 2022: A user-facing warning message may be displayed to non-compliant OAuth requests October 3, 2022: The OOB flow is blocked for all clients and users will see the error page. Please check out our recent blog post about Making Google OAuth interactions safer for more information. What do I need to do? Migrate your app(s) to an appropriate alternative method by following these instructions: Determine your app(s) client type from your Google Cloud project by following the client links below. Migrate your app(s) to a more secure alternative method by following the instructions in the blog post above for your client type. If necessary, you may request a one-time extension for migrating your app until January 31, 2023. Keep in mind that all OOB authorization requests will be blocked on February 1, 2023. The following OAuth client(s) will be blocked on Oct 3, 2022. OAuth client list: Project ID: rcloneclientid-247*** Client: 211984046708-hahav9pt2t2v6mc6*********apps.googleusercontent.com Thanks for choosing Google OAuth. — The Google OAuth Developer Team
-
Replaced cache drive and formatted xfs. Moved everything back and rebuilt docker containers. Up nine days with no issues. No full log, no read only cache. Obviously some kind of cache drive issue even though it tested good on extended smart. Likely btrfs issue that couldn't be easily solved with a solo drive. btrfs likely should not be the default format for solo cache drives in unraid. Solved
-
Yeah, I am going to re-format to XFS and check the drive health. Maybe replace the drive while I'm at it.
-
The container throwing errors at 2:08 in the above docker.log.1 is Plex. Which makes sense as it is one of the few containers that do weekly tasks. Like; Optimize database every week Remove old bundles every week Remove old cache files every week Refresh local metadata every three days Update all libraries during maintenance Upgrade media analysis during maintenance Refresh library metadata periodically Perform extensive media analysis during maintenance Fetch missing location names for items in photo sections Analyze and tag photos
-
tmedia-diagnostics-20220224-0746.zip
-
ime="2022-02-17T09:39:13.452768189-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/11042cc115649e3ab6 time="2022-02-17T09:39:14.623462556-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/b561fa76d6448f3866 time="2022-02-17T09:39:22.156585651-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/2797cb4cbee2465f19 time="2022-02-17T09:39:29.803429402-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/46ed75f24b478dac09 time="2022-02-17T09:39:42.249379513-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/5d9bc873b3912de1d8 time="2022-02-17T09:41:56.087910866-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/813c029f1297badc0d time="2022-02-17T13:17:05.810879095-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/11042cc115649e3ab6 time="2022-02-17T16:02:40.611782191-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/1e12f74ffa47552535 time="2022-02-17T16:10:26.454018823-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/2917c4264a8d7fa646 time="2022-02-17T16:12:57.570313462-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/6e5057e30f675ad9e1 time="2022-02-17T19:42:31.947233453-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/029848900a6b20de1f time="2022-02-20T03:02:27.631077081-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/074683c5cf36bad42a time="2022-02-20T03:02:27.869498318-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/e7fbdfeaf2938bf844 time="2022-02-20T03:02:28.093142878-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/e971c0d73df2f126ce time="2022-02-20T03:02:28.759846471-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/5fde6164eee377132e time="2022-02-20T18:15:32.855833192-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/e7fbdfeaf2938bf844 time="2022-02-20T18:15:35.908244972-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/e971c0d73df2f126ce time="2022-02-20T18:21:25.657697206-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/361f9711b624934400 time="2022-02-20T18:30:55.243448330-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/623879e0f6a156ec9f time="2022-02-20T18:31:30.396987709-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/623879e0f6a156ec9f time="2022-02-20T18:31:33.436374626-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/361f9711b624934400 time="2022-02-21T05:16:53.142672669-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/839d03928f88bace48 time="2022-02-21T05:16:53.338638453-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/46b04ec6c0c08c67c0 time="2022-02-21T05:16:53.483946879-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/c683260bf2fce1850a time="2022-02-21T05:16:53.747645779-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/623879e0f6a156ec9f time="2022-02-21T05:16:53.974481072-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/361f9711b624934400 time="2022-02-21T05:16:54.837505517-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/074683c5cf36bad42a time="2022-02-21T05:16:55.094084245-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/b561fa76d6448f3866 time="2022-02-21T05:16:55.635014188-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/5fde6164eee377132e time="2022-02-21T05:16:55.880927303-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/6e5057e30f675ad9e1 time="2022-02-21T05:16:56.624917396-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/46ed75f24b478dac09 time="2022-02-21T05:16:57.072193293-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/4bf9a4eefa4506e462 time="2022-02-21T05:16:57.458395737-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/813c029f1297badc0d time="2022-02-21T05:16:57.846209906-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/5d9bc873b3912de1d8 time="2022-02-23T08:04:16.299433190-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/cfac2a914f66fac185 time="2022-02-23T08:04:32.226963630-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/8e13546ef3b1fc375f time="2022-02-23T08:04:45.446979587-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/66012d868342c76e6f time="2022-02-23T08:05:28.088544708-06:00" level=info msg="starting signal loop" namespace=moby path=/var/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/ade6eb0470838d3937 time="2022-02-24T02:08:39.381326314-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:39.388577844-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:39.388614598-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:39.388655682-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:40.382377322-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:40.389256094-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:40.389308017-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:40.389369289-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:41.340254415-06:00" level=error msg="Error replicating health state for container 6e5057e30f675ad9e12892bdab82a35ccbf6c79520f015c145eb219607b9392f: open /var/lib/doc time="2022-02-24T02:08:41.383229258-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:41.389602197-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68e time="2022-02-24T02:08:41.389639522-06:00" level=error msg="Failed to log msg \"\" for logger json-file: error writing log entry: write /var/lib/docker/containers/623879e0f6a156ec9f5f2e68 The beginning of the errors of docker.log.1 are at the bottom here.
-
root@tmedia:~# df -h /var/log Filesystem Size Used Avail Use% Mounted on tmpfs 384M 384M 0 100% /var/log root@tmedia:~# du -sm /var/log/* 1 /var/log/apcupsd.events 1 /var/log/apcupsd.events.1 0 /var/log/btmp 0 /var/log/cron 0 /var/log/debug 1 /var/log/dmesg 0 /var/log/docker.log 383 /var/log/docker.log.1 0 /var/log/faillog 1 /var/log/gitflash 0 /var/log/lastlog 0 /var/log/libvirt 1 /var/log/maillog 0 /var/log/messages 0 /var/log/nfsd 1 /var/log/nginx 0 /var/log/packages 1 /var/log/pkgtools 0 /var/log/plugins 0 /var/log/pwfail 0 /var/log/removed_packages 0 /var/log/removed_scripts 0 /var/log/removed_uninstall_scripts 1 /var/log/samba 0 /var/log/scripts 0 /var/log/secure 0 /var/log/setup 0 /var/log/spooler 0 /var/log/swtpm 1 /var/log/syslog 2 /var/log/syslog.1 0 /var/log/unraid-api 0 /var/log/vfio-pci 1 /var/log/wtmp
-
Is PIA still the darling for a port-fowarding VPN?
-
Every Thursday morning for a few months now I wake up to a banner on my docker page (haven't screenshot it sorry) with no icons or access to any docker containers. A reboot seems to fix it. Unraid typically just "runs" for me and has for years, so I wasn't sweating it. Today I had some time to dig around a bit. I can't find any processes/jobs that are running on a Wednesday night/Thrusday morning (There HAS to be something....) but I did find that there were a bunch of btrfs errors in the log. I only have btrfs on my cache drive which is where the docker folder is stored of course. I restarted the system and ran a memtest with no errors reported. I then started the array in maintenance mode and ran a btrfs check on the cache drive and got this, but I don't have any idea what to do from here; [1/7] checking root items [2/7] checking extents data backref 40881405952 root 5 owner 46973646 offset 0 num_refs 0 not found in extent tree incorrect local backref count on 40881405952 root 5 owner 46973646 offset 0 found 1 wanted 0 back 0x1ae7ab40 incorrect local backref count on 40881405952 root 5 owner 46973646 offset 32768 found 0 wanted 1 back 0x183e3cb0 backref disk bytenr does not match extent record, bytenr=40881405952, ref bytenr=0 backpointer mismatch on [40881405952 45056] ref mismatch on [48950460416 8192] extent item 549755813888, found 0 owner ref check failed [48950460416 8192] ERROR: errors found in extent allocation tree or chunk allocation [3/7] checking free space tree [4/7] checking fs roots root 5 inode 74013114 errors 200, dir isize wrong root 5 inode 77896360 errors 1, no inode item unresolved ref dir 74013114 index 3862251 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896362 errors 1, no inode item unresolved ref dir 74013114 index 3862253 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896370 errors 1, no inode item unresolved ref dir 74013114 index 3862255 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896373 errors 1, no inode item unresolved ref dir 74013114 index 3862257 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896374 errors 1, no inode item unresolved ref dir 74013114 index 3862259 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896379 errors 1, no inode item unresolved ref dir 74013114 index 3862261 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896382 errors 1, no inode item unresolved ref dir 74013114 index 3862263 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896383 errors 1, no inode item unresolved ref dir 74013114 index 3862265 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896384 errors 1, no inode item unresolved ref dir 74013114 index 3862267 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896385 errors 1, no inode item unresolved ref dir 74013114 index 3862269 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896388 errors 1, no inode item unresolved ref dir 74013114 index 3862271 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896391 errors 1, no inode item unresolved ref dir 74013114 index 3862273 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896392 errors 1, no inode item unresolved ref dir 74013114 index 3862275 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896393 errors 1, no inode item unresolved ref dir 74013114 index 3862277 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896394 errors 1, no inode item unresolved ref dir 74013114 index 3862279 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896397 errors 1, no inode item unresolved ref dir 74013114 index 3862281 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896400 errors 1, no inode item unresolved ref dir 74013114 index 3862283 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896401 errors 1, no inode item unresolved ref dir 74013114 index 3862285 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896402 errors 1, no inode item unresolved ref dir 74013114 index 3862287 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref root 5 inode 77896403 errors 1, no inode item unresolved ref dir 74013114 index 3862289 namelen 45 name 3d18b2ea89fa5357cf6423b4e6985b46fa10195e.json filetype 1 errors 5, no dir item, no inode ref ERROR: errors found in fs roots Opening filesystem to check... Checking filesystem on /dev/sdf1 UUID: 482f734c-0b01-4faf-8bc0-86c08db6bd62 cache and super generation don't match, space cache will be invalidated found 137627197440 bytes used, error(s) found total csum bytes: 131599768 total tree bytes: 2780954624 total fs tree bytes: 2420736000 total extent tree bytes: 176078848 btree space waste bytes: 704096014 file data blocks allocated: 190648750080 referenced 137950638080
-
I have a CyberPower CP1500PFCLCD, very similar to yours, with the same issue. Log fills up with; Dec 23 12:38:43 tmedia usbhid-ups[4122]: nut_libusb_get_report: Input/Output Error. Dec 23 12:40:53 tmedia usbhid-ups[4122]: nut_libusb_get_report: Input/Output Error. Dec 23 12:42:17 tmedia usbhid-ups[4122]: nut_libusb_get_report: Input/Output Error. Dec 23 12:43:35 tmedia usbhid-ups[4122]: nut_libusb_get_report: Input/Output Error. etc etc. Have you figured out how to stop it?
-
I guess the question now is, be pro-active and try to get signed up with one user at $20/month unlimited and eat the paltry $8 increase for a few extra months? Or, let them transition me sometime next year and see what they sign me up for. Probably a terrible idea to leave it in their hands. I'll likely wait until they start warning me with an actual conversion date before I try to switch.
-
Looks like we are getting down to the wire on Google Workspace transition. Getting the email below now. Any recommendations/thoughts? One user, just over 7TB (growing slowly). Hello Administrator, We previously notified you that your G Suite subscription will transition to a Google Workspace subscription. We’re writing to let you know that you can now begin your transition. There are two options: Option 1 (recommended): Self-transition now in a few easy steps. Option 2: Let Google transition you automatically once your organization is eligible*, starting from January 31, 2022. We will provide you with at least 30 days notice before your transition date. (There's more but relatively un-important)
-
Looks like it is some kind of issue with ca-montreal. Changed to ca-ontario and speeds and logs look normal. Thanks for your kind attention. It gives me the confidence to dive in and tinker.
-
I restarted mine and got these interesting results; 2021-11-08 10:24:18,692 DEBG 'start-script' stdout output: [warn] PIA VPN info API currently down, skipping endpoint port forward check 2021-11-08 10:24:50,767 DEBG 'start-script' stdout output: [warn] Unable to successfully download PIA json to generate token from URL 'https://privateinternetaccess.com/gtoken/generateToken' [info] 12 retries left [info] Retrying in 10 secs...
-
Did PIA change it's port forwarded servers again? I'm getting all KB speeds this morning. My supervisord.log only shows; [info] qatar.privacy.network [info] saudiarabia.privacy.network [info] sg.privacy.network [info] srilanka.privacy.network [info] taiwan.privacy.network [info] tr.privacy.network [info] ae.privacy.network [info] vietnam.privacy.network [info] aus-melbourne.privacy.network [info] au-sydney.privacy.network [info] aus-perth.privacy.network [info] nz.privacy.network [info] dz.privacy.network [info] egypt.privacy.network [info] morocco.privacy.network [info] nigeria.privacy.network [info] za.privacy.network None of which I currently have configured.
-
UPDATE: I figured this out after about four hours of re-teaching myself lol. Something odd happened in Google Workspace. App Access Control (api) was untrusted. I re-enabled it and then had to run rclone config as headless and use my Workspace admin account to get the token and update it. I screwed it up the first time by using my main(old) regular google(gmail) account and could see my personal google drive in rclone lol. Using the admin account for Workspace fixed that. I really appreciate this forum. It gives me the confidence to poke around! I figured I was fine as long as I keep copies of the encryption passwords for the crypt portion and, sure enough, I eventually got it. Lost my mount three days ago apparently and it looks like the token has expired. From the mount script log; couldn't fetch token - maybe it has expired? - refresh with "rclone config reconnect gdrive{UpdQG}:": oauth2: cannot fetch token: 400 Bad Request Response: { "error": "invalid_grant", "error_description": "Token has been expired or revoked." } The "rclone config reconnect" command in the log doesn't work, I get; Error: backend doesn't support reconnect or authorize Usage: rclone config reconnect remote: [flags] Flags: -h, --help help for reconnect Use "rclone [command] --help" for more information about a command. Use "rclone help flags" for to see the global flags. Use "rclone help backends" for a list of supported services. 2021/08/16 23:40:29 Fatal error: backend doesn't support reconnect or authorize Going to need some detailed help. I set this up a few years ago and it's been cruising along on its own just fine until now. Thanks.
-
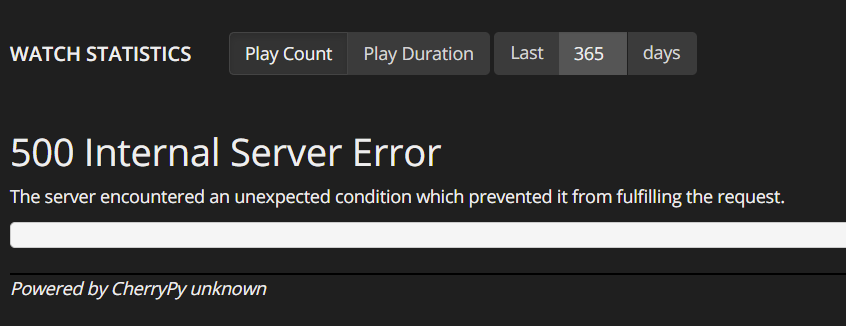
Home page has a display error of some kind. History and graph tabs look fine. Image is attached of what it looks like. I found one error in the logs; 2021-05-19 19:33:35ERROR[19/May/2021:19:33:35] HTTP Traceback (most recent call last): File "/app/tautulli/lib/cherrypy/_cprequest.py", line 630, in respond self._do_respond(path_info) File "/app/tautulli/lib/cherrypy/_cprequest.py", line 689, in _do_respond response.body = self.handler() File "/app/tautulli/lib/cherrypy/lib/encoding.py", line 221, in __call__ self.body = self.oldhandler(*args, **kwargs) File "/app/tautulli/lib/cherrypy/_cpdispatch.py", line 54, in __call__ return self.callable(*self.args, **self.kwargs) File "/app/tautulli/plexpy/webserve.py", line 399, in home_stats stats_count=stats_count) File "/app/tautulli/plexpy/datafactory.py", line 314, in get_home_stats timestamp = int((datetime.now(tz=plexpy.SYS_TIMEZONE) - timedelta(days=time_range)).timestamp()) AttributeError: 'datetime.datetime' object has no attribute 'timestamp' Any idea how to fix? Or just wait for update... Thanks in advance.
-
NEVERMIND FIXED: After discovering there were no config files for deluge-vpn I disabled and re-enabled docker. Config files showed up, copied openvpn files as per usual and I'm back up and running. Leaving this post for others. Had some kind of event at 3am that killed my dockers. Could have been a power outage I guess, I have a UPS but it has never worked very well with unraid. I'm not even sure that was it as the server was powered on and it shouldn't have been if there was an outage. UPDATE: 3am on Sunday is when my dockers auto-update. Regardless, all of my dockers came back up except binhex deluge-vpn. When I try to start it I get Execution Error Server Error window. When I check the server logs the only thing that shows up is BELOW. I have had my server set up for IPV4 only in network settings for years. Supervisord.log hasn't been touched since 3am. UPDATE: I got impatient and deleted the docker and re-installed. On startup I got; /usr/bin/docker: Error response from daemon: driver failed programming external connectivity on endpoint binhex-delugevpn (af91521bd4e05570c2288cc4ccc838cbe668d260d8971415f2e7ecf929226404): Bind for 0.0.0.0:58946 failed: port is already allocated. The port is not allocated to any other docker though. UPDATE: Now there are no config files written at all. Dec 21 09:23:33 tmedia kernel: IPv6: ADDRCONF(NETDEV_UP): veth37e079a: link is not ready Dec 21 09:23:33 tmedia kernel: docker0: port 8(veth37e079a) entered blocking state Dec 21 09:23:33 tmedia kernel: docker0: port 8(veth37e079a) entered forwarding state Dec 21 09:23:33 tmedia kernel: docker0: port 8(veth37e079a) entered disabled state Dec 21 09:23:33 tmedia kernel: docker0: port 8(veth37e079a) entered disabled state Dec 21 09:23:33 tmedia kernel: device veth37e079a left promiscuous mode Dec 21 09:23:33 tmedia kernel: docker0: port 8(veth37e079a) entered disabled state Dec 21 09:29:18 tmedia kernel: docker0: port 8(vethd741bb1) entered blocking state Dec 21 09:29:18 tmedia kernel: docker0: port 8(vethd741bb1) entered disabled state Dec 21 09:29:18 tmedia kernel: device vethd741bb1 entered promiscuous mode Dec 21 09:29:18 tmedia kernel: IPv6: ADDRCONF(NETDEV_UP): vethd741bb1: link is not ready Dec 21 09:29:18 tmedia kernel: docker0: port 8(vethd741bb1) entered blocking state Dec 21 09:29:18 tmedia kernel: docker0: port 8(vethd741bb1) entered forwarding state Dec 21 09:29:18 tmedia kernel: docker0: port 8(vethd741bb1) entered disabled state Dec 21 09:29:18 tmedia kernel: docker0: port 8(vethd741bb1) entered disabled state Dec 21 09:29:18 tmedia kernel: device vethd741bb1 left promiscuous mode Dec 21 09:29:18 tmedia kernel: docker0: port 8(vethd741bb1) entered disabled state Dec 21 09:32:30 tmedia kernel: docker0: port 8(veth63d7cc7) entered blocking state Dec 21 09:32:30 tmedia kernel: docker0: port 8(veth63d7cc7) entered disabled state Dec 21 09:32:30 tmedia kernel: device veth63d7cc7 entered promiscuous mode Dec 21 09:32:30 tmedia kernel: IPv6: ADDRCONF(NETDEV_UP): veth63d7cc7: link is not ready Dec 21 09:32:30 tmedia kernel: docker0: port 8(veth63d7cc7) entered blocking state Dec 21 09:32:30 tmedia kernel: docker0: port 8(veth63d7cc7) entered forwarding state Dec 21 09:32:30 tmedia kernel: docker0: port 8(veth63d7cc7) entered disabled state Dec 21 09:32:30 tmedia kernel: docker0: port 8(veth63d7cc7) entered disabled state Dec 21 09:32:30 tmedia kernel: device veth63d7cc7 left promiscuous mode Dec 21 09:32:30 tmedia kernel: docker0: port 8(veth63d7cc7) entered disabled state Dec 21 09:37:49 tmedia kernel: docker0: port 8(vethdc3cb46) entered blocking state Dec 21 09:37:49 tmedia kernel: docker0: port 8(vethdc3cb46) entered disabled state Dec 21 09:37:49 tmedia kernel: device vethdc3cb46 entered promiscuous mode Dec 21 09:37:49 tmedia kernel: IPv6: ADDRCONF(NETDEV_UP): vethdc3cb46: link is not ready Dec 21 09:37:49 tmedia kernel: docker0: port 8(vethdc3cb46) entered blocking state Dec 21 09:37:49 tmedia kernel: docker0: port 8(vethdc3cb46) entered forwarding state Dec 21 09:37:49 tmedia kernel: docker0: port 8(vethdc3cb46) entered disabled state Dec 21 09:37:50 tmedia kernel: docker0: port 8(vethdc3cb46) entered disabled state Dec 21 09:37:50 tmedia kernel: device vethdc3cb46 left promiscuous mode Dec 21 09:37:50 tmedia kernel: docker0: port 8(vethdc3cb46) entered disabled state
-
I really appreciate your responses. Thanks for the assist!
-
I got impatient just now and started trying things. I removed the movies folder in union with rmdir and it deleted, so it didn't have anything in it or it would have warned me. I recreated the movies folder and tried to run the mount script. Same error. I removed the movies folder from union and ran the mount script. No error!! I looked in union and nothing was there. I added the moves folder back and everything in rclone reappeared. It looks like it's fixed for now, but I don't know how it got broken and why the script wouldn't fix it as it's been running fine.
-
/mnt/user/mount_rclone/google_vfs ? No, that's not empty, but unless I'm confused it shouldn't be. It's showing everything that's in my google drive.


