




Rudder2
Members
-
Joined
-
Last visited
Everything posted by Rudder2
-
Here is a new supervisord.log. Please help. I ping things in the container and the TX and RX of the tunnel increase so the tunnel is working. Just something isn't working. No idea what. supervisord.log
-
Any ideas anyone? More information needed? Please help.
-
Hello, Been trying to get this to work for a while. I bash in to the container and the VPN is working but Deluge is not accessible. I need a new set of eyes on it. There is so much information I cannot parse it all. Thank you. supervisord.log
-
Total system lockup unresponsive from console, ssh, network, parity check stops, no disk activity at all, no VM working, nothing functioning what so ever. I suffer this lock up when ever I install 6.6.0+. Though it was because of the RealTek NIC problem so downgraded to 6.5.3 and then updated to 6.6.3 and had worse network issues so down graded to 6.5.3. Then Upgraded to 6.6.5 and the RealTek NIC error has been rectified but the Lockup problem remains. The system will run for about 5 or 6 days lock up then run 6 hours lock up and run 3 hours lock up then 30 minutes and lock up. I can't get system logs because they are not stored on flash. I already downgraded to the stable 6.5.3 image. My system log on first boot after the 4 lock up in one day is attached. The first was after the first lock up and the last after the 4th. Don't know if they will help because they were taken after a reset button press to get the system back up. BIOS was updated to the latest BIOS for my motherboard after the second lockup because I saw a hardware error about microcode in the log file 1923. That same error is in log file 2357. rudder2-server-diagnostics-20181114-1923.zip rudder2-server-diagnostics-20181114-2357.zip
-
I like it! This looks like it will work beautifully! I had to manually create all the .Recycle.Bin folders in all my shares to begin with but this was no biggie! I discovered 600GB in my darr app's Recycling Bin Share from the years since I upgraded to using all darr apps. Thank you for your help! Rudder2
-
I use both the Recycling Bin Plugin and I also have a Recycling Bin Share that Sonarr, Lidarr, and Radarr moves files in to instead of deleting them. I would like this share to delete the files every 14 or 30 days. It might be redundant since I have the Recycling Plugin installed. I will have to look in to how that works...Does it copy all files deleted from unRAID no matter what did it? If so than I probably don't need the Recycling Bin share and have my darr apps move files instead of delete them. I will look at those links also. Thank you, Rudder2
-
Your right. I think I know what killed it. I had a problem where I lost 2 DATA disks (Make sure that the new controller card you buy is compatible with unRAID...) When I recovered the Disks I had to restore my APPs folder from a back up to recover my Databases because they scanned and saw the missing DATA and I didn't feel like rebuilding it my self because I would have to correct a lot of incorrect matches. Not thinking about it I recovered all APPs DATA instead of just the ones I needed. I wander if this broke LetsEncrypt. I nuked the APPs folder and Docker Image let it start using the LinuxServer/LetsEncrypt repository to create the APP DATA and them copied back in the CloudFlare.ini and the site-confs back in and it's back up. Should of done this to begin with...This is the beauty of the way the Docker Images from LinuxServer.io are written, easy recovery. One good thing from all this is I discovered I was still on the Preview Channel when I should of been back on the Main update channel. This happens often (usually BETA channel) and I never figure it out till the Docker brakes. Thank you for all your help! Your AWESOME!
-
I changed the channel back to main channel and now I get this error: ------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io We gratefully accept donations at: https://www.linuxserver.io/donations/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [cont-init.d] 10-adduser: exited 0. [cont-init.d] 20-config: executing... [cont-init.d] 20-config: exited 0. [cont-init.d] 30-keygen: executing... using keys found in /config/keys [cont-init.d] 30-keygen: exited 0. [cont-init.d] 50-config: executing... 4096 bit DH parameters present SUBDOMAINS entered, processing Sub-domains processed are: -d www.MYDOMAIN.com -d nextcloud.MYDOMAIN.com -d vpn.MYDOMAIN.com -d onlyoffice.MYDOMAIN.com -d collabora.MYDOMAIN.com E-mail address entered: [email protected] Different sub/domains entered than what was used before. Revoking and deleting existing certificate, and an updated one will be created Saving debug log to /var/log/letsencrypt/letsencrypt.log Unable to load: [('PEM routines', 'CRYPTO_internal', 'no start line')],[('asn1 encoding routines', 'CRYPTO_internal', 'header too long')] Generating new certificate Saving debug log to /var/log/letsencrypt/letsencrypt.log Plugins selected: Authenticator standalone, Installer None Obtaining a new certificate Performing the following challenges: Client with the currently selected authenticator does not support any combination of challenges that will satisfy the CA. Client with the currently selected authenticator does not support any combination of challenges that will satisfy the CA. IMPORTANT NOTES: - Your account credentials have been saved in your Certbot configuration directory at /etc/letsencrypt. You should make a secure backup of this folder now. This configuration directory will also contain certificates and private keys obtained by Certbot so making regular backups of this folder is ideal. ERROR: Cert does not exist! Please see the validation error above. The issue may be due to incorrect dns or port forwarding settings. Please fix your settings and recreate the container
-
Here is is. I purposely changed my domain to MYDOMAIN.com and my account number to ACCT# trying to prevent privet data from being posted in a form. AWESOME! just changed it back to the linuxserver/letsencrypt channel. MYDOMAIN.com.conf
-
I have a Recycle Bin share for my Sonarr and Radarr and Lidarr Recycling just in case I need to jump back to the previous version...What I didn't realize was that after years of this it's taking A LOT of space. I was wandering if there was a script to Delete everything in my Recycling Bin that's older than 30 days every week. Thank you in advance for your help, Rudder2
-
@aptalca I'm having problems with the CloudFlare DNS-01. Is it main stream or should I still be on the preview update you made 3 months ago? I'm getting this error in the log: <-------------------------------------------------> cronjob running on Sat Apr 7 12:33:51 CDT 2018 Running certbot renew Saving debug log to /var/log/letsencrypt/letsencrypt.log ------------------------------------------------------------------------------- Processing /etc/letsencrypt/renewal/MYDOMAIN.conf ------------------------------------------------------------------------------- expected /etc/letsencrypt/live/MYDOMAIN.com/cert.pem to be a symlink Renewal configuration file /etc/letsencrypt/renewal/MYDOMAIN.com.conf is broken. Skipping. ------------------------------------------------------------------------------- No renewals were attempted. Additionally, the following renewal configuration files were invalid: /etc/letsencrypt/renewal/MYDOMAIN.com.conf (parsefail) ------------------------------------------------------------------------------- 0 renew failure(s), 1 parse failure(s) [cont-init.d] 50-config: exited 0. [cont-init.d] done. [services.d] starting services [services.d] done. nginx: [emerg] PEM_read_bio_X509_AUX("/config/keys/letsencrypt/fullchain.pem") failed (SSL: error:09FFF06C:PEM routines:CRYPTO_internal:no start line:Expecting: TRUSTED CERTIFICATE) Server ready nginx: [emerg] PEM_read_bio_X509_AUX("/config/keys/letsencrypt/fullchain.pem") failed (SSL: error:09FFF06C:PEM routines:CRYPTO_internal:no start line:Expecting: TRUSTED CERTIFICATE)
-
@aptalca You rock! you made my decision an easy one...I'm changing from NO-IP to Cloudflare. I've been thinking about doing it anyways because Cloudflare's free service it better than NO-IP's paid service. Done a lot of research so I wouldn't have to bother you but I though that reading the inclusion of DNS-01 verification warranted a big thank you.
-
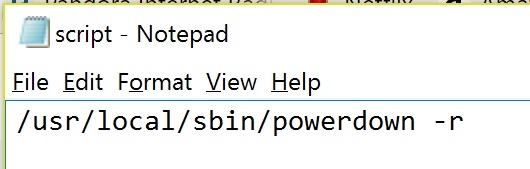
It works. The complete path is /usr/local/sbin/powerdown -r and you must use it. Thank you both CHBMB and Squid! I though that was the problem but nowhere on-line could I find that path. The working script Just want to spell it out so the next person who looks for this will hopefully be able to get it to work without asking. I'm all about self help but sometimes after days of searching and coming up short I eventually ask for help. I've been researching this for 3 days till I got frustrated and asked for help. Thank you for both of your time so much! Rudder2
-
6.3.3
-
I tried that and I get command not found. Script location: /tmp/user.scripts/tmpScripts/powerdown -r/scriptNote that closing this window will abort the execution of this script/tmp/user.scripts/tmpScripts/powerdown -r/script: line 2: powerdown: command not foundThis is going to sound stupid but I don't understand acronyms...What does op mean? I've read over and over what you originally said Squid but end up with more questions than answers. I went to the Plugin Page and read all I could there and even went to the Scripts page and read there. Yes, I discovered when I saved the script it didn't save with the enter the first time. Should of saw that when I copied and pasted, Thanks for pointing that out CHBMB. The new saved script it: #!/bin/bash powerdown -r And I get this error now: Script location: /tmp/user.scripts/tmpScripts/powerdown -r/scriptNote that closing this window will abort the execution of this script/tmp/user.scripts/tmpScripts/powerdown -r/script: line 2: powerdown: command not found Ironically, when I type powerdown -r in terminal it works fine. I think I need to know the location of the powerdown file to put in the script but I don't know that for sure. Thank you for your time, Rudder2Squid, I spoke too soon. I cannot get the powerdown -r to function because I cannot find the location of the powerdown command to write my own user script and I cannot find a pre written powerdown -r script. I've once again search google high and low and have resorted back to this form. I keep getting a this error: Script location: /tmp/user.scripts/tmpScripts/powerdown -r/scriptNote that closing this window will abort the execution of this script/usr/local/emhttp/plugins/user.scripts/startScript.sh: /tmp/user.scripts/tmpScripts/powerdown -r/script: /bin/bashpowerdown: bad interpreter: No such file or directory The script I wrote is #!/bin/bashpowerdown -r Please tell me what I'm doing wrong. Sorry for any inconvenience. Thank you for you time, Rudder2Thank you so much Squid! This is exactly what I needed!My server runs non stop with minimal servicing. I find when it's up from 1.5 to 8 weeks the server's internet speed is seriously slowed on everything from Dockers to VMs. I don't find this as off because I reboot all my computers once a week but unRAID get neglected because it's the server and I don't think about it when I'm home and I'm also away from home relying on unRAID to keep chugging on it's own. I was wandering if there was either a plugin, or command I can use in a cron script, to have my server reboot every week on a certain day @ 0400. Since the problem always manifests greater than one week, usually closer to 2 weeks, and after a reboot the whole server functions better as a whole makes me feel this is a good idea. I've been searching the internet and Lime-Tech forms high and lot to find this answer and nothing has came from it. If anyone could help me I would GREATLY appreciate it. Oh, yeah, I'm running unRAID 6.3.3 at the time of writing this. It would be nice if a reboot was able to be scheduled from the Scheduler but I'm not asking for that because I know you have more pressing matters. Thank you for your time, Rudder2




