




ratmice
Members
-
Joined
-
Last visited
Everything posted by ratmice
-
Started after upgrading to 7.1.14 from 7.0.1. I also got an error from my plex docker about "Critical: libusb_init" failed, which I fixed with advice from this thread: https://www.reddit.com/r/docker/comments/j0klle/critical_libusb_init_failed_what_does_this_mean/ Trying to downgrade back to 7.0.1 to see if it helps
-
Gotcha, thanks for taking time to help me out. So, I will unassign parity 2 regardless of whether I do a regular restart and sync, or start in maintenance and sync. Well, unassigning parity2 and adding the new disk as parity1 leads to an invalid configuration, so I guess I just assign the new disk, tick the maintenance mode box, and restart the array?
-
Sorry, I'm a bit confused. I've never really used maintenance mode. I can have the array offline, but how do you keep parity2 intact if it's removed for the sync. There seems to be something I'm missing, maybe it's the distinction between the disk used to store parity information (parity2 disk) vs the actual information (parity2). Sorry for the endless questions, but I don't want to do something stupid because my understanding is incorrect. Thanks for your patience.
-
So, circling back to my server issues. I am ready to add in the new the parity disk, but am a little worried about the Parity 2 disk (SMART errors) currently in the server. Is the best course of action to just allocate the new disk to parity, rebuild, and see what happens? I'm a bit afraid that the Parity 2 disk will be pulled out of service due to the errors. As I understand it the 2 parity disks are independent of each other so that even if that happens, I can just deallocate the Parity 2 and not have any issues with the new parity disk, or the array, aside from only having protection from one disk failure. Or, is there some other procedure I should follow to keep things efficient and safe? As always, I really appreciate the help here, as I can just think myself into circles due to incomplete knowledge. p.s. the other factor here is that I will be away from home for the next couple of months, so will not be able to physically lay hands on the server to do any more disk switching, etc... Perfect timing!
-
the test fails almost immediately with a read error 🤬 I guess I need to get the new disk added as parity and get another new replacement. Odd for the 2 parity disks to crap out almost simultaneously.
-
So, quick recap, Had a parity disk go belly up last week, then the flash drive died. Got the flash replaced and a new parity drive came today. Now, of course, I am seeing a bunch of pending sectors on the currently installed parity 2 disk. My question is what is the most efficient, and safest, way to get things back to normal. I assume I just need to pre clear the new disk, add it to the array as parity 1, and start a sync to calculate parity on the new disk as well as to see if the pending sectors on the parity 2 disk go away? What am I missing? Or, maybe do an extended SMART test, on parity 2, while the pre-clear is happening ?
-
Yeah, I followed the changing flash drive guide. Unfortunately, The flash drive was totally toast, so I couldn't copy it and my latest flash backup was too old to trust. However, I did have all the disk assignments, so recreating the array was trivial. Everything, array related, seems good at the moment. The thing I am struggling with now is getting Plex back in order, no easy feat, I will tell you, as I am switching docker containers, and it is not happy with the previous app data.
-
Yesterday, I had a parity disk die unceremoniously. Today, I woke up to a corrupt flash drive. I am about to replace it. Unfortunately, I cannot get any diagnostics, right now, as it is dead. 2 quick questions for those smarter than I, 1. any pitfalls to look out for when replacing the flash drive (I did read the docs about it) and, 2. could this have had any impact on yesterday's dead parity disk situation.
-
Thanks for making this clear
-
@trurl and @JorgeB thank you both for your help with this issue, now if only I had a spare drive.
-
No show, must be dead ☠️. Since there is now only 1 parity disk, do I need to rebuild parity to account for the missing second disk, or will the array still be protected, but only from one data disk going down? Sorry, not 100% sure how the disk parity is calculated. Also, do I need to reassign the Parity 2 disk to the single parity slot?
-
I shutdown the server, checked all cables/connections. The user shares did reappear (thanks), but the #1 parity disk is not showing up in the array. Here are the new diagnostics, after reboot. tower-diagnostics-20250429-1335.zip
-
I hate to reply to my own post, but digging around I, I get this : as the output to ls -lah /mnt. I assume that this is where the User shares have gone. Can I just: to repair that part, of the issue? Sorry for the noob questions, I am just not very Linux technically inclined.


-
So, this morning woke up to a disabled parity disk (1 of 2), user shares not showing up and I'm not sure where to begin, to safely figure out what's going on, and how to rectify the situation. All disk shares are accessible and seem to be working properly. tower-diagnostics-20250429-1037.zip
-
Thanks for this, I have been pulling my hair out trying to figure out why only Chrome was not able to connect.
-
On the page with the color selection might be good, maybe right near the color picker? While we're at it, would it be possible to have different color schemes for the disk view and heat map view, that would be awesome.
-
Thanks for replying so quickly. I did indeed change some colors on the heat map. The reset colors worked to set things right. BTW, the reset colors is on the tray allocation tab, for those trying to find it.
-
I just installed, and really like this plug in. However, I cannot seem to get the Main page to use the colors, for the drives, from the configuration page. I changed them but the old colors remain, or even began using new colors entirely. One category changed to black and I can't read any info at all 😆
-
after 4hrs, and not even getting through 1% of the pre-read, I killed that pre clear and added another drive in that spot. The pre clear on that is moving along at about 270 MB/s, with no errors, so I think the drive is just toast. I will try ite again after the current pre clear is finished.
-
SO I am pre clearing a 6TB disk I had laying around, and the speeds are abysmal (2-3 MB/s). I notice a lot of these blocks within the log: Apr 30 11:40:31 Tower kernel: ata8.00: exception Emask 0x0 SAct 0x80e00000 SErr 0x0 action 0x0 Apr 30 11:40:31 Tower kernel: ata8.00: irq_stat 0x40000008 Apr 30 11:40:31 Tower kernel: ata8.00: failed command: READ FPDMA QUEUED Apr 30 11:40:31 Tower kernel: ata8.00: cmd 60/40:a8:00:94:73/05:00:00:00:00/40 tag 21 ncq dma 688128 in Apr 30 11:40:31 Tower kernel: res 41/40:00:00:94:73/00:00:00:00:00/00 Emask 0x409 (media error) <F> Apr 30 11:40:31 Tower kernel: ata8.00: status: { DRDY ERR } Apr 30 11:40:31 Tower kernel: ata8.00: error: { UNC } Apr 30 11:40:31 Tower kernel: ata8.00: configured for UDMA/133 Apr 30 11:40:31 Tower kernel: sd 9:0:0:0: [sdo] tag#21 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=11s Apr 30 11:40:31 Tower kernel: sd 9:0:0:0: [sdo] tag#21 Sense Key : 0x3 [current] Apr 30 11:40:31 Tower kernel: sd 9:0:0:0: [sdo] tag#21 ASC=0x11 ASCQ=0x4 Apr 30 11:40:31 Tower kernel: sd 9:0:0:0: [sdo] tag#21 CDB: opcode=0x88 88 00 00 00 00 00 00 73 94 00 00 00 05 40 00 00 Apr 30 11:40:31 Tower kernel: I/O error, dev sdo, sector 7574528 op 0x0:(READ) flags 0x84700 phys_seg 168 prio class 0 Apr 30 11:40:31 Tower kernel: ata8: EH complete Is this due to a failing drive, and does it also explain the speeds being in the toilet?
-
Thanks for pointing me in the right direction, I really appreciate it.
-
So, I'm guessing if I change the current static IP address to 10.0.0.88 (assuming it's currently not used) and change the port mappings in the docker settings to reflect that change, I might be good to go. I assume I will also need to change the default gateway to 10.0.0.1, as well.
-
Its an Xfinity router XB8, which I believe is a Technicolor CGM4981COM Wi-Fi 6E under the hood. It's admin page is accessed by the typical 10.0.0.1 IP Addy. My MacPro seems to be happy with an IP address of xx.xx.xx.190, if that helps. note: this thing has been installed for only a few hours so I haven't had much of a chance to check everything out. I started with UnRAID as that is my priority. I found this, too:
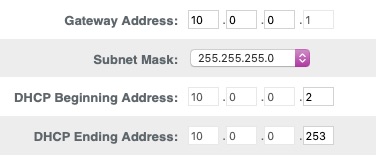
-
So, I was out of town for a couple of months and came home to a dead router, which has now been replaced. After getting things set-up, I am now seeing a host of problems with UnRAID. I was able to start my array without issue, and can see my shares from my home network, but that's where it seems to end. Updating dockers, plug-ins, and even UnRAID OS will not work. Also, server is no longer registering in My Servers. The common factor is that the versions of all the aforementioned things (plugins, dockers, OS) do not show up, so therefore, the updates cannot occur. I am not super computer savvy and am having a bit of trouble even knowing where to begin. I am currently on UnRAID 6.11.5. I will attach a few SSs of what I am seeing. It seems likely that there is still some setup to do on the new router, but I thought I would begin to try to get things back in order. To be honest that router, and UnRAID itself, was set up over a decade ago, so my memory of what was necessary to get unRAID running has long since disappeared. Any guidance will be much appreciated. tower-diagnostics-20230407-1817.zip
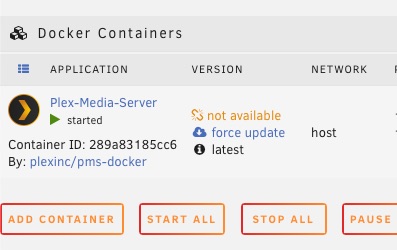
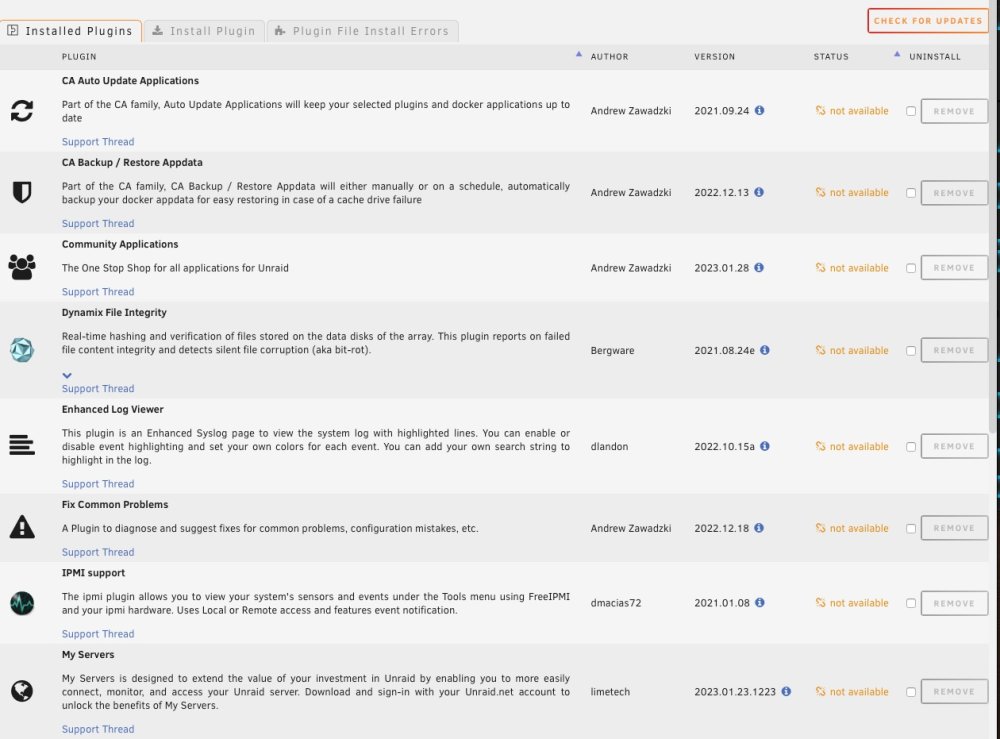

-
One last thing. I am going to add a second parity disk. I assume that this should happen after I rebuild the disabled disk and update the OS, correct?








