




eagle470
Members
-
Joined
-
Last visited
-
I don't know what I'm doing wrong, but I'm trying to get this thing online and the system won't initialize. These are the errors in the logs on first boot. {"severity":"WARN","time":"2026-03-16T22:31:11.064Z","meta.caller_id":"Ci::UnlockPipelinesInQueueWorker","correlation_id":"8c22fd5e13898263d8219674f8db8e23","meta.root_caller_id":"Cronjob","meta.feature_category":"job_artifacts","meta.client_id":"ip/","message":"writing value to /dev/shm/gitlab/sidekiq/histogram_sidekiq_0-0.db failed with read/write operation attempted while mmap was being written to"} {"severity":"WARN","time":"2026-03-16T22:31:11.064Z","meta.caller_id":"Ci::UnlockPipelinesInQueueWorker","correlation_id":"8c22fd5e13898263d8219674f8db8e23","meta.root_caller_id":"Cronjob","meta.feature_category":"job_artifacts","meta.client_id":"ip/","message":"writing value to /dev/shm/gitlab/sidekiq/histogram_sidekiq_0-0.db failed with read/write operation attempted while mmap was being written to"} docker run -d --name='GitLab-CE' --net='br0.3' --ip='10.10.3.99' --pids-limit 2048 -e TZ="America/Los_Angeles" -e HOST_OS="Unraid" -e HOST_HOSTNAME="Unraid2" -e HOST_CONTAINERNAME="GitLab-CE" -e 'TCP_PORT_9080'='9080' -e 'TCP_PORT_9443'='9443' -e 'TCP_PORT_22'='9022' -e 'GITLAB_OMNIBUS_CONFIG'='gitlab_rails['\''enable_puma_sampler'\''] = false; gitlab_rails['\''enable_sidekiq_sampler'\''] = false' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:9080]' -l net.unraid.docker.icon='' -v '/mnt/cache/appdata/gitlab-ce/config':'/etc/gitlab':'rw' -v '/mnt/cache/appdata/gitlab-ce/data':'/var/opt/gitlab':'rw' -v '/mnt/cache/appdata/gitlab-ce/log':'/var/log/gitlab':'rw' --env GITLAB_OMNIBUS_CONFIG="external_url 'http://unraid:9080/'" --memory=12g 'gitlab/gitlab-ce'
-
I'm running an HPE Proliant with dual 6262v's. While it's not a fast proc, it should run better than it is and now I'm having issues with the WebUI becoming entirely unavailable. Please take a look and advise. I've done some CPU pinning to try and dedicate resources, but to no avail. I have python 3 installed and have since removed it. unraid1-diagnostics-20260301-0733.zip
-
Over the last 10 years, I have had a lot of changes go on in my library, so I have, using chatgpt, created a script to clean that up. Please take a look and let me know what you think. Below is the complete, ready-to-run User Scripts–compatible script. It is a bash wrapper that runs an embedded Python tool. It: Operates directly on /mnt/disk* (never touches /mnt/user), as requested. Consolidates matching movie/series folders across disks onto the disk with most free space among the participating disks. Uses one worker thread per disk. Serializes writes only: a job that writes to a disk will acquire that disk’s write lock. Reads are not blocked. If a task cannot acquire required write lock(s), it is requeued with a short backoff. Renames seasons to Season_{n}, renames episode video files to your requested formats (best-effort), picks the highest-quality duplicate in a folder and deletes / moves the rest to --trash if provided. Dry-run by default; pass --apply to actually perform moves/deletes. When --apply completes, runs a correcting parity check (mdcmd check) as you requested. Safe for Unraid — must be run on the Unraid host in User Scripts. Important: run the script once without --apply to review the dry-run plan printed to the console. How to useIn Unraid User Scripts, create a new script, paste the code below into it, save. Run without arguments (dry-run): ./your_script_name To apply changes and run the correcting parity check at the end: sudo ./your_script_name --apply --trash /mnt/disk1/Trash Script (paste into User Scripts)#!/bin/bash # ===================================================================== # Unraid User Scripts launcher - Disk-aware media consolidator (final) # Dry-run by default. Use --apply to perform changes. # ===================================================================== PYTHON_BIN=$(command -v python3 || command -v python) if [ -z "$PYTHON_BIN" ]; then echo "ERROR: python3 not found on this system." exit 1 fi # Pass all args to embedded Python $PYTHON_BIN - "$@" <<'PYCODE' import argparse import os import re import shutil import subprocess import sys import time import random from pathlib import Path from queue import Queue from threading import Thread, Lock from typing import List, Dict, Tuple, Optional # ------------------ Configuration ------------------ VIDEO_EXTS = {".mp4", ".mkv", ".m4v", ".avi", ".mov", ".wmv", ".flv", ".ts", ".webm", ".m2ts"} DISK_ROOT = Path("/mnt") DISK_GLOB_PREFIX = "disk" MOVIES_SUBPATH = "movies" TV_SUBPATH = "media/tv" PARITY_CMD = "/usr/local/sbin/mdcmd" # run: mdcmd check LOCK_BACKOFF = (0.02, 0.08) # seconds TASK_REQUEUE_LIMIT = 100 LOCK_ACQUIRE_TIMEOUT = 5 # --------------------------------------------------- def log(msg: str): print(f"[{time.strftime('%F %T')}] {msg}", flush=True) def list_disks() -> List[Path]: return sorted([p for p in DISK_ROOT.glob(DISK_GLOB_PREFIX + "*") if p.is_dir()]) def disk_free_bytes(disk: Path) -> int: try: st = shutil.disk_usage(str(disk)) return st.free except Exception: return -1 def normalize_for_key(name: str) -> str: s = name.lower() s = re.sub(r"[ _\-.]+", "", s) s = re.sub(r"[^\w]", "", s) return s def prefer_canonical_name(cands: List[str]) -> str: if not cands: return "" for c in cands: if "_" in c: return c for c in cands: if " " in c: return c return max(cands, key=len) def cleanup_target_name(name: str) -> str: s = re.sub(r"\s+", " ", name).strip() s = s.replace(" ", "_") s = re.sub(r"[/:<>?\\|]+", "_", s) return s # Quality heuristics def quality_score(fname: str) -> int: s = 0 ln = fname.lower() if re.search(r"(2160|4k)", ln): s += 500 if "1080p" in ln: s += 300 if "720p" in ln: s += 200 if re.search(r"bluray|bdrip|uhd|remux", ln): s += 250 if re.search(r"web-dl|webdl|webrip", ln): s += 150 if re.search(r"dolbyvision|dolby|dv|hdr", ln): s += 100 if re.search(r"proper|repack", ln): s += 30 return s def choose_best(files: List[Path]): best = None best_val = -1 for f in files: try: sc = quality_score(f.name) size = f.stat().st_size val = sc * (10**12) + size if val > best_val: best_val = val best = f except Exception: continue return best # TV parsing helpers def extract_episode_numbers(name: str): nums = [] for m in re.finditer(r'[sS](\d{1,2})[eE](\d{2})', name): nums.append(int(m.group(2))) if not nums: m = re.search(r'(?:Episode|Ep)[\s._-]*([0-9]{1,3})', name, re.I) if m: nums = [int(m.group(1))] if not nums: m2 = re.search(r'[^0-9]([0-9]{1,3})[^0-9]', f' {name} ') if m2: n = int(m2.group(1)) if 0 < n < 300: nums = [n] # dedupe preserve order out = []; seen=set() for n in nums: if n not in seen: out.append(n); seen.add(n) return out def is_daily(name: str) -> bool: return bool(re.match(r'^\d{4}-\d{2}-\d{2}$', name)) def derive_ep_title(foldername: str, folderpath: Path) -> str: t = re.sub(r'[sS]\d{1,2}[eE]\d{2}(?:[eE]\d{2})*', '', foldername) t = re.sub(r'^(Episode|Ep)[\s._-]*\d{1,3}', '', t, flags=re.I) t = re.sub(r'^\d{4}-\d{2}-\d{2}', '', t) t = re.sub(r'[_\.\-]+', ' ', t).strip() if t: return t.replace(" ", "_") files = [p for p in folderpath.iterdir() if p.is_file() and p.suffix.lower() in VIDEO_EXTS] if files: return files[0].stem.replace(" ", "_") return "Episode" def build_tv_name(series_norm: str, season_num: int, ep_nums: List[int], ep_title: str, quality: str, is_daily_flag: bool, daily_date: str="") -> str: if is_daily_flag and daily_date: return f"{series_norm}_{daily_date}_{ep_title}_{quality}" if is_daily_flag: return f"{series_norm}_UNKNOWNDATE_{ep_title}_{quality}" if ep_nums: epseq = f"S{season_num:02d}" + "".join(f"E{e:02d}" for e in ep_nums) return f"{series_norm}_{epseq}_{ep_title}_{quality}" else: return f"{series_norm}_S{season_num:02d}E00_{ep_title}_{quality}" # Worker system class WorkerSystem: def __init__(self, disks: List[Path], apply: bool, trash: Optional[Path]): self.disks = disks self.apply = apply self.trash = trash self.disk_names = [d.name for d in disks] self.queue = Queue() # write lock per disk: serialize writes (destinations / deletes) self.write_locks: Dict[str, Lock] = {d.name: Lock() for d in disks} self.threads: Dict[str, Thread] = {} self.stop_flag = False def start(self): for dn in self.disk_names: t = Thread(target=self.worker_loop, args=(dn,), daemon=True) self.threads[dn] = t t.start() def stop(self): # put sentinel None per worker for _ in self.threads: self.queue.put(None) for t in self.threads.values(): t.join(timeout=5) def enqueue(self, src: Path, dst_dir: Path, src_disk_name: str, dst_disk_name: str): # tuple: src, dst_dir, src_disk_name, dst_disk_name, requeue_count self.queue.put((str(src), str(dst_dir), src_disk_name, dst_disk_name, 0)) def worker_loop(self, my_disk_name: str): while True: item = self.queue.get() if item is None: self.queue.task_done() break src_str, dst_dir_str, src_disk, dst_disk, rq = item src = Path(src_str); dst_dir = Path(dst_dir_str) # For writes, we need to lock destination (and source if deleting source) disks_to_lock = sorted(list({dst_disk, src_disk})) acquired = [] got_all = True for dn in disks_to_lock: lock = self.write_locks.get(dn) if lock is None: continue # try to acquire non-blocking if not lock.acquire(blocking=False): got_all = False break acquired.append(dn) if not got_all: # release any acquired and requeue with backoff for dn in acquired: try: self.write_locks[dn].release() except Exception: pass rq += 1 if rq > TASK_REQUEUE_LIMIT: log(f"[SKIP] too many requeues for task: {src} -> {dst_dir}") self.queue.task_done() continue time.sleep(random.uniform(*LOCK_BACKOFF)) self.queue.put((src_str, dst_dir_str, src_disk, dst_disk, rq)) self.queue.task_done() continue # perform move under locks try: if not dst_dir.exists(): if self.apply: dst_dir.mkdir(parents=True, exist_ok=True) log(f"[MKDIR] {dst_dir}") else: log(f"[DRY MKDIR] {dst_dir}") dst_full = dst_dir / src.name # avoid moving onto itself try: if dst_full.exists() and dst_full.resolve() == src.resolve(): log(f"[SKIP] same file: {src}") continue except Exception: pass # handle name collision if dst_full.exists() and dst_full.resolve() != src.resolve(): base = dst_full.with_suffix(''); ext = dst_full.suffix; i = 1 candidate = Path(f"{base}_{i}{ext}") while candidate.exists(): i += 1 candidate = Path(f"{base}_{i}{ext}") dst_full = candidate if self.apply: shutil.move(str(src), str(dst_full)) log(f"[MOVE] {src} -> {dst_full}") else: log(f"[DRY MOVE] {src} -> {dst_full}") except Exception as e: log(f"[ERROR] moving {src} -> {dst_dir}: {e}") finally: # release locks for dn in acquired: try: self.write_locks[dn].release() except Exception: pass self.queue.task_done() # Scan groups def scan_groups(disks: List[Path]): movie_groups = {} tv_groups = {} for d in disks: mroot = d / MOVIES_SUBPATH if mroot.exists() and mroot.is_dir(): for child in mroot.iterdir(): if child.is_dir(): key = normalize_for_key(child.name) movie_groups.setdefault(key, []).append((d, child, child.name)) tvroot = d / TV_SUBPATH if tvroot.exists() and tvroot.is_dir(): for s in tvroot.iterdir(): if s.is_dir(): key = normalize_for_key(s.name) tv_groups.setdefault(key, []).append((d, s, s.name)) return movie_groups, tv_groups def pick_target_disk(members: List[Tuple[Path,Path,str]]) -> Path: best = None; best_free = -1; seen=set() for d,_,_ in members: if d in seen: continue seen.add(d) f = disk_free_bytes(d) if f > best_free: best_free = f; best = d return best or members[0][0] def canonical_name_from_members(members): names = [m[2] for m in members] pref = prefer_canonical_name(names) return cleanup_target_name(pref) # Enqueue moves to consolidate a group onto the chosen disk def enqueue_group_moves(ws: WorkerSystem, members, apply: bool): if not members: return [], None, None target_disk = pick_target_disk(members) cname = canonical_name_from_members(members) sample = members[0][1] rel_parent = sample.parent.relative_to(members[0][0]) target_parent = target_disk / rel_parent target_path = target_parent / cname if not target_parent.exists(): if apply: target_parent.mkdir(parents=True, exist_ok=True) log(f"[PLAN] ensure parent: {target_parent}") if not target_path.exists(): if apply: target_path.mkdir(parents=True, exist_ok=True) log(f"[MKDIR] {target_path}") else: log(f"[DRY MKDIR] {target_path}") logs = [] # enqueue moves for each member that's not on the target disk for disk, path, name in members: if disk.resolve() == target_disk.resolve(): continue for root, dirs, files in os.walk(str(path)): rel = os.path.relpath(root, str(path)) if rel == ".": rel_dst = str(target_path) else: rel_dst = str(target_path / rel) for f in files: src = Path(root) / f # allow moving all files (subs, nfo, etc.) to keep dir intact ws.enqueue(src, Path(rel_dst), disk.name, target_disk.name) logs.append(f"[ENQUEUE] {src} -> {rel_dst} (dst disk {target_disk.name})") return logs, target_disk, target_path # Post-consolidation normalization (seasons, file renames, duplicate handling) def normalize_seasons_and_files(target_series_path: Path, ws: WorkerSystem, apply: bool, trash: Optional[Path]): logs = [] if not target_series_path.exists(): return logs # Normalize season folders for child in sorted([p for p in target_series_path.iterdir() if p.is_dir()]): m = re.search(r'[sS]eason[_\s\-]*([0-9]{1,2})', child.name) if m: season_num = int(m.group(1)) else: m2 = re.search(r'\b([0-9]{1,2})\b', child.name) if m2: season_num = int(m2.group(1)) else: continue target = child.parent / f"Season_{season_num}" if child.resolve() == target.resolve(): continue if target.exists(): # merge child into target: move items for item in sorted(child.iterdir()): dest = target / item.name ws.enqueue(item, dest.parent, item.resolve().parts[2], dest.resolve().parts[2]) logs.append(f"[ENQUEUE MERGE] {item} -> {dest}") else: # rename (local rename is a write -> enqueue a move from child to target under same disk) ws.enqueue(child, target.parent, child.resolve().parts[2], child.resolve().parts[2]) logs.append(f"[ENQUEUE RENAME] {child} -> {target}") # Per-episode file handling for season in sorted([p for p in target_series_path.iterdir() if p.is_dir()]): season_num = 1 m = re.search(r'Season[_\s\-]*([0-9]{1,2})', season.name, re.I) if m: season_num = int(m.group(1)) for ep in sorted([p for p in season.iterdir() if p.is_dir()]): ep_name = ep.name daily_flag = is_daily(ep_name) daily_date = ep_name if daily_flag else "" ep_title = derive_ep_title(ep_name, ep) ep_nums = extract_episode_numbers(ep_name) vids = [p for p in ep.iterdir() if p.is_file() and p.suffix.lower() in VIDEO_EXTS] if not vids: logs.append(f"[NO-VIDS] {ep}") continue best = choose_best(vids) if not best: logs.append(f"[NO-BEST] {ep}") continue ln = best.name.lower(); q = "" if "web-dl" in ln or "webdl" in ln: q="WEBDL" elif "webrip" in ln or "web-rip" in ln: q="WEBRIP" elif "bluray" in ln or "bdrip" in ln or "remux" in ln: q="BLURAY" if "2160" in ln or "4k" in ln: q = (q + "-" if q else "") + "2160p" elif "1080p" in ln: q = (q + "-" if q else "") + "1080p" elif "720p" in ln: q = (q + "-" if q else "") + "720p" if re.search(r'dolbyvision|dolby|dv', ln): q = (q + "_DV") if q else "DV" if not q: q = "UNKNOWN" series_norm = cleanup_target_name(target_series_path.name) if re.search(r'anime', series_norm, re.I): q = f"{q}_v2" final_base = build_tv_name(series_norm, season_num, ep_nums, ep_title, q, daily_flag, daily_date) final_base = re.sub(r'_+', '_', final_base).strip('_') ext = best.suffix final_name = f"{final_base}{ext}" dst = ep / final_name # enqueue rename of best to dst (same-disk write) ws.enqueue(best, dst.parent, best.resolve().parts[2], dst.resolve().parts[2]) logs.append(f"[ENQUEUE RENAME-BEST] {best} -> {dst}") # inferior files: move to trash if provided, else delete (enqueue trash move) for other in vids: if other.resolve() == best.resolve(): continue if trash: ws.enqueue(other, Path(trash), other.resolve().parts[2], other.resolve().parts[2]) logs.append(f"[ENQUEUE TRASH] {other} -> {trash}") else: # try immediate delete under write lock, else enqueue move to a hidden .delete folder wl = ws.write_locks.get(other.resolve().parts[2]) if wl and wl.acquire(blocking=False): try: if ws.apply: other.unlink() logs.append(f"[DELETE] {other}") else: logs.append(f"[DRY DELETE] {other}") except Exception as e: logs.append(f"[ERROR DELETE] {other}: {e}") finally: wl.release() else: # enqueue move to .delete folder on same disk delete_folder = other.parent / ".delete" ws.enqueue(other, delete_folder, other.resolve().parts[2], other.resolve().parts[2]) logs.append(f"[ENQUEUE DELETE] {other} -> {delete_folder}") return logs def disk_from_path(p: Path) -> Path: parts = p.resolve().parts for i, part in enumerate(parts): if part.startswith("disk"): return Path("/" + os.path.join(*parts[:i+1])) return Path("/mnt") def main(): parser = argparse.ArgumentParser(description="Unraid disk-aware media consolidator (dry-run default).") parser.add_argument("--apply", action="store_true", help="Perform operations (default: dry-run).") parser.add_argument("--trash", type=str, default="", help="If set, move inferior files to this path.") args = parser.parse_args() apply = args.apply trash = Path(args.trash) if args.trash else None disks = list_disks() if not disks: log("No /mnt/disk* found. Exiting.") return 1 log(f"Disks discovered: {', '.join(d.name for d in disks)}") ws = WorkerSystem(disks, apply, trash) ws.start() movie_groups, tv_groups = scan_groups(disks) log(f"Scanned groups: {len(movie_groups)} movie keys, {len(tv_groups)} tv keys") all_logs = [] # Process movie groups for key, members in movie_groups.items(): logs, tdisk, tpath = enqueue_group_moves(ws, members, apply) all_logs.extend(logs) # normalization of target folder and file renames will be handled in post-normalize pass # Process tv groups and track targets for normalization tv_targets = [] for key, members in tv_groups.items(): logs, tdisk, tpath = enqueue_group_moves(ws, members, apply) all_logs.extend(logs) if tpath: tv_targets.append((tpath, tdisk)) # Wait for initial consolidation moves log("Waiting for consolidation move tasks to complete...") ws.queue.join() log("Consolidation moves complete.") # Attempt to remove empty source directories (acquire write lock per disk) _, movie_groups_post = scan_groups(disks), tv_groups # simple refresh # simply attempt cleanup across all disks for d in disks: for root, dirs, files in os.walk(str(d), topdown=False): try: p = Path(root) if p.is_dir() and not any(p.iterdir()): dn = p.parts[2] if len(p.parts) > 2 else d.name wl = ws.write_locks.get(dn) if wl and wl.acquire(timeout=LOCK_ACQUIRE_TIMEOUT): try: p.rmdir() log(f"[RMDIR] {p}") except Exception: pass finally: wl.release() except Exception: pass # Post-normalize TVs across all disks: enqueue renames and duplicate handling log("Enqueuing post-normalization across TV series...") for d in disks: tvroot = d / TV_SUBPATH if not tvroot.exists(): continue for series in sorted([p for p in tvroot.iterdir() if p.is_dir()]): logs = normalize_seasons_and_files(series, ws, apply, trash) for l in logs: log(l) # Wait for post-normalization tasks log("Waiting for post-normalization tasks...") ws.queue.join() log("Post-normalization complete.") # Final empty-directory cleanup log("Final empty-directory cleanup pass...") for d in disks: for root, dirs, files in os.walk(str(d), topdown=False): p = Path(root) try: if p.is_dir() and not any(p.iterdir()): dn = p.parts[2] if len(p.parts) > 2 else d.name wl = ws.write_locks.get(dn) if wl and wl.acquire(timeout=LOCK_ACQUIRE_TIMEOUT): try: p.rmdir() log(f"[RMDIR] {p}") except Exception: pass finally: wl.release() except Exception: pass # Stop workers ws.stop() log("All tasks done. Summary (first 200 actions):") for i, line in enumerate(all_logs[:200]): log(line) if apply: # Run parity check (correcting) log("Running correcting parity check (this will modify parity if mismatches are found).") try: subprocess.run([PARITY_CMD, "check"], check=True) log("Parity check command completed.") except Exception as e: log(f"[ERROR] parity check failed: {e}") return 0 if __name__ == '__main__': sys.exit(main()) PYCODE Short plain-language description (paste into User Scripts description field)This job scans all data disks (/mnt/disk*) for movies/ and media/tv/ folders, groups same-named media, and consolidates scattered copies onto the disk with the most free space among the disks currently holding parts. It renames season folders to Season_n, renames episodes to your requested standardized format (Standard/Daily/Anime heuristics), deduplicates files keeping the highest-quality copy, and moves/deletes inferior copies (optionally to --trash). The tool serializes writes only (no two writes will occur on the same disk at once); reads are unrestricted. Default is dry-run; pass --apply to make changes. When --apply completes, a correcting parity check (mdcmd check) is run.
-
I was using 7.2.2 when this issue was occuring, so that can't be right. The steps given to me in email where what solved the problem For those looking for the answer, know I jammed this in by hand so you could have an answer and I didn't want to sign into email on a new laptop: paste this into terminal and execute: unraid-api plugins install unraid-api-plugin-connect
-
Would you please make a template for this? https://github.com/ChuckPa/DBRepair I'm honestly shocked that it isn't on the CA store yet. But I need it. Thanks!
-
most things had been up for atleast 3 days, ther rest have been up for longer. I don't know what the issue could be. This is a brand new install, I don't even have my license converted to the new USB yet.
-
I ran the commands you gave me, It's still doing the same thing. Here are the post run diags.unraid2-diagnostics-20251126-1003.zip
-
I did! I recently had to reload the flash drive on this because it corupted. I would like to see the option to consume a drive slot for boot. unraid2-diagnostics-20251124-1054.zip
-
I'm missing most of the functions of the Connect plugin. anythoughts on this?
-
host1-diagnostics-20250908-1814.zip
-
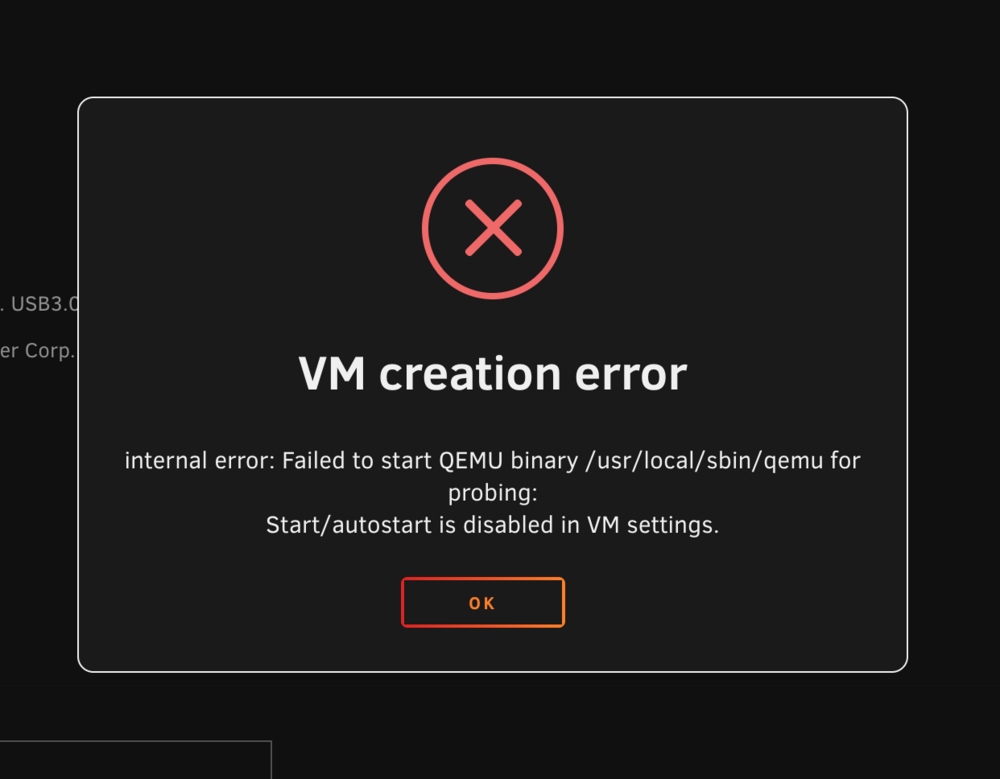
I mean the ability to do shared storage for the OS disk. Not within the VM itself.
-
Hello, I would like to see a method to manage multiple unraid systems from a single GUI without having to sign into each opne ever time my browser restarts or session times out. It would be nice if there was an option to select where to deploy a docker app or VM in terms of which system I am running on. I would also like to see the unassiugned drives plugin more integrated into the servers for shared storage capability. I have three servers, one runs a true ZFS array and I would like to use that for all my virtual machines and present that as shared storage. There seems to be some problems with presenting UNRAID storage out to non-UNRAID systems, like ESXi, so it would be nice to alleviate that issue, if it hasn't been done already. But adding the ability for shared storage where I can host all my containers and VM's would make it very easy to create and manage and MIGRATE my systems for optimal uptime.
-
better storage management GUI to facilitate the addition of shared storage.
-
Please add intel an amd microcode update tools into the OS or issue a plugin. That is all. Thank you
-
Oh man, thats so old, I'm about 7 system revisions from that now....

