




darkwolf
Members
-
Joined
-
Last visited
-
All working now. I forget in my testing last night that I added a digit to my token to force a rebuild of the docker on UnRaid, but did not modify the Plex Webhook URL. Not sure what happened to cause it issues in the first place. But forcing a rebuild seems to have worked! Thank you for being there and the quick replies, as a developer and a Unix Admin for 25 years, it is much appreciated and respected.
-
The webhook in Plex is still pointing to the same IP it was before (where PA resides), and the docker is in bridge mode and has been, so is the IP of the server, so not sure what to change, nothing on the network has changed. I could just as easily throw this in a docker on the plex host (I have a few running there already), so I may do that.

-
Well damn, you know, I didn't even notice what it was showing! HA! Weird thing is... My plex server has been on a different IP for well over a year, but it has been working fine for 2 years... don't know what changed. But this is what my UnRaid config has for fields So, not sure if the fields changed or something else happened. But creating a new instance on Unraid shows the same fields, no place for plex server URL just webhook port
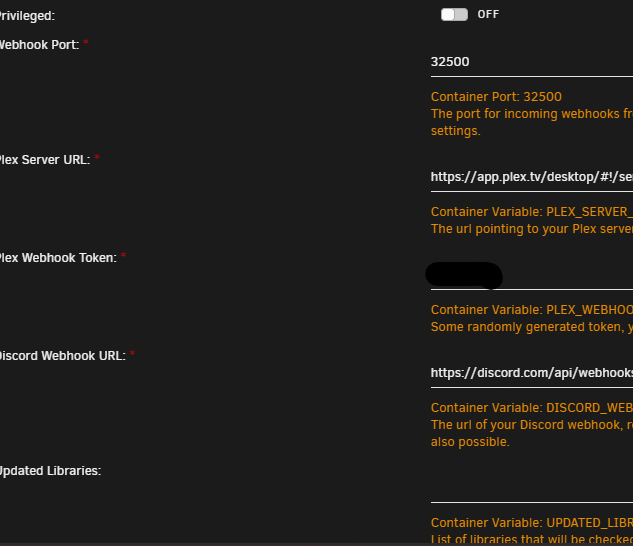
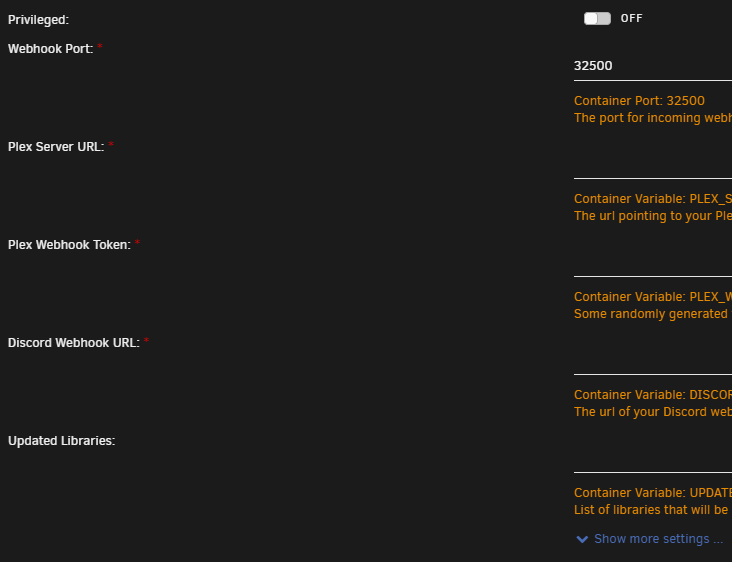
-
Dang, still no reason why it is not working I can see. I can ping out inside the container, name resolution works fine, did not make any changes to either plex or discord (that I am aware of) (Though the issues looks like plex, as I WAS getting updates (play stop updates from plex.tv) up until 7/21) I rebuilt the container, so can not access the older run logs. I get the normal 2024-08-14 20:49:25 INFO Plex webhook URL: http://localhost:<yadda/yadda> but nothing after that. Any advice on further troubleshooting? (It had been working great for well over 2 years, THANKS!)
-
Thanks for the quick reply! I will debug on my end then.
-
Has there been a change to Plex, doesn't seem like the docker is able to announce to Plex anymore (last update to my server was 7/21/2024 according to the logs)
-
I am also having this problem with modpacks like ATM8, Stoneblock3, and Seaopolis2. Runs fine on my custom dockers and local machine with 17, but current version installed on this docker is 19, which crashlogs all the modpacks I have tried (all forge servers that I remember) based off java minecraft 1.18 and 1.19
-
Happened after trying to disable Attribute SMART Monitoring on flash storage that does not report errors right. Fixed by going in and trying to do it again. Seems to randomly do it when changing and applying on one disk, then using the < > arrows to change disks instead of hitting done.
-
darkwolf changed their profile photo
-
So RE A26, any way to fix Sickchill, as it does not give an option to ignore locals. I setup Sonarr again, and I still don't like it
-
Before the update I was using privoxy for various apps including nzbhydra, jackett, radarr, and now the problem child sickchill All the others are working fine as I already had bypass locals and bypass my grabbers, but now sickchill can not sent nzbs to SABnzbd. Is there any way to tell it to bypass locals (I have not found a way), besides moving everything over to sonarr?
-
DOH!! I thought I had tried that before coming here. (I blame it on the meds!!!) Thank you, worked like a charm, continue the good fight!!!
-
I tried with entering the IP address, still does not find the shares. I would LOVE to manually add the shares, but do not see how from the "ADD REMOVE SMB/NFS SHARE" It finds my server just fine in the "SEARCH FOR SERVERS", just can not find any shares after trying to authenticate. Can I add it manually via config file?
-
Hello I tried searching up and down in the various UD threads and can't find an answer for the new interface. I have been having problems mounting an smbv1 mount on an ancient NAS device (probably moving it over to unraid but have had other things to do :P). I have had it mounted before last year, and was backing it up with Duplicati, though it failed later last year and I never realized it Yes I still have force SMBv1 in settings, I can manually mount it so I know the password works. I deleted the mounts as I saw there was a change in UD with encrypting passwords (Applause there ), but I can not seem to get a listing of shares. I get the scan for 'Win 10' shares, enter username and next, password and next, don't enter anything for Domain and then ext, hit Scan for Shares and it's an immediate come back with nothing. I can mount it fine from the command line, but want to use UD since you guys do an awesome job with it (And having supported a few free apps in the past, I feel your pain! You need more love!!!)! Command line mount -t cifs -o rw,nounix,iocharset=utf8,_netdev,file_mode=0777,dir_mode=0777,sec=ntlm,vers=1.0,username='****',password='****' '//STORAGE1/C' '/mnt/disks/STORAGE1_C/' I don't get an error in dmesg or syslog when trying to use UD, but was hoping for a quick fix like 'Oh Stupid, click on this first'. If not I can run diagnostics and dump them if needed Thank you again for the wonderful community here and awesome support. Sorry if I missed the easy fix in past posts, but Soooo many posts to look through (I only made it through like 20 or so pages from the past few months on a couple of different threads' EDIT: OH! And also yes, NetBIOS is also enabled
-
For the last week or so I am getting drops in sab. Looking at the logs I see I am erroring out on the api curl check for ip. Anything I can do about this? I am using PIA. Worked for a charm for a long while, not sure when it started but I started noticing it a week or two ago. Stuff will eventually download, mostly. It just takes forever I changed to a CA node thinking maybe a TUN would be better, seems to have fixed it, though I was getting faster speeds on US servers, Ahhhh well. Just FYI for anyone seeing spikes and slows in their servers on PIA BTW Great job guys! Love it
-
Unfortunately, it's the only option for xbox one owners. :( I'd personally rather not use the alpha, but since in my household xbones are becoming more prevalent and 'easier to use' than having the family switch inputs to watch something on kodi, I'm screwed. :( Looks like it's time to roll my own again :( *Walking away grumbling about xbones* BTW Mr. Balls, you rock ;)



