




B1scu1T
Members
-
Joined
-
Last visited
Everything posted by B1scu1T
-
I just listened to the Podcast. Started the day with news that was driving me away, I now feel confident enough to buy an additional licence. Thanks guys.
-
I appreciate the communication coming out now, but I think I speak for most of us when I say, I wish this had come before the software release. My only question is surrounding the guarantee Limetech are making towards future of "lifetime" (including existing basic/plus/pro) customers. Is there a genuine commitment towards existing customers retaining a perpetual license for all future Unraid versions, or is there a chance that Limetech have an expectation of a small upgrade fee in the case of major upgrades? I understand that you cannot talk from an absolute 100% basis, as who knows what the future will bring, but I would just like to make sure the foreseeable future has no plans for this, and if there is, that we are at least informed of it.
-
I think this is the main thing we all want to know. Companies change direction, usually financial drivers behind it, I can respect that... and if they make the decision to go down the subscription route to grow the product then ok.... they might lose out on some referrals based on their (up-till-now) fair pricing model, but perhaps they will gain it back with investment into features, improved support level, and documentation. Perhaps they will also get more revenue from business customers.... I totally get and can respect all of that.... but... I'm certainly concerned by the prospect of the thing I bought being indirectly dis-honored in the ways we have seen companies treat similar situations elsewhere. The fact that: Is one of the lines that's been dug up certainly raises my eyebrow. It of course could mean nothing, Limetech could come out and say, "all existing licenses will be fully honored by the spirit they were sold", but there is enough in there, IMO, for us to speculate the worst case.
-
I have had other "lifetime" software that has moved to a subscription model, and the way they manage it without breaking the terms they sold the software on is to just release the software under a new name or version. So for example, you have a lifetime version of Unraid 6 but next year they release Unraid 7. To get this upgrade you either have to pay the subscription, or pay an upgrade fee. I'm not totally opposed to this model if the fees are reasonable, the time between major upgrades is long, and the support level of the software reflects that, but I'm not paying $100s for software that remains largely community supported.
-
Yeah it's a branded startech reverse SAS breakout and I suppose it has been in and out of a lot of builds. I'm going to perhaps try with a HBA and straight SAS cable before I buy anything, mostly because that's what I already own..
-
I ran the extended test anyway just to be safe. It said it finished without error, and doesnt look like anything to be concerned about there. I'll change the cable but just a bit baffled that there would be an error without anything being touched. (correct me if wrong) tower-smart-20240214-1524.zip
-
So although the system wouldn't stop, it did shut down safely. Now booted up and running an extended smart test on that drive but if anyone has any clue what went wrong, or how to find out what went wrong I would really appreciate it.
-
The drive logs Now disconnected sdg: Feb 12 13:31:32 Tower emhttpd: read SMART /dev/sdg Feb 12 13:33:33 Tower kernel: sd 6:0:0:0: [sdg] Synchronizing SCSI cache Feb 12 14:01:09 Tower emhttpd: spinning down /dev/sdg Feb 12 14:01:09 Tower emhttpd: sdspin /dev/sdg down: 2 Feb 13 09:54:29 Tower emhttpd: error: hotplug_devices, 1713: No such file or directory (2): tagged device WDC_WUH721816ALE6L4_2BJ90ZUN was (sdg) is now (sdj) sdj in unassigned drives: Feb 9 19:28:49 Tower kernel: ata6: SATA max UDMA/133 abar m2048@0xfc400000 port 0xfc400180 irq 87 Feb 9 19:28:49 Tower kernel: ata6: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Feb 9 19:28:49 Tower kernel: ata6.00: ATA-11: WDC WUH721816ALE6L4, PCGNW232, max UDMA/133 Feb 9 19:28:49 Tower kernel: ata6.00: 31251759104 sectors, multi 16: LBA48 NCQ (depth 32), AA Feb 9 19:28:49 Tower kernel: ata6.00: Features: NCQ-sndrcv NCQ-prio Feb 9 19:28:49 Tower kernel: ata6.00: configured for UDMA/133 Feb 12 13:31:23 Tower kernel: ata6: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Feb 12 13:31:32 Tower kernel: ata6.00: configured for UDMA/133 Feb 12 13:33:13 Tower kernel: ata6: SATA link up 6.0 Gbps (SStatus 133 SControl 300) Feb 12 13:33:18 Tower kernel: ata6.00: qc timeout after 5000 msecs (cmd 0xec) Feb 12 13:33:18 Tower kernel: ata6.00: failed to IDENTIFY (I/O error, err_mask=0x4) Feb 12 13:33:18 Tower kernel: ata6.00: revalidation failed (errno=-5) Feb 12 13:33:23 Tower kernel: ata6: link is slow to respond, please be patient (ready=0) Feb 12 13:33:28 Tower kernel: ata6: found unknown device (class 0) Feb 12 13:33:28 Tower kernel: ata6: SATA link down (SStatus 1 SControl 300) Feb 12 13:33:28 Tower kernel: ata6: limiting SATA link speed to <unknown> Feb 12 13:33:30 Tower kernel: ata6: SATA link down (SStatus 1 SControl 3F0) Feb 12 13:33:30 Tower kernel: ata6.00: disable device Feb 12 13:33:33 Tower kernel: ata6: SATA link down (SStatus 1 SControl 300) Feb 12 13:33:33 Tower kernel: ata6.00: detaching (SCSI 6:0:0:0) Feb 12 13:33:35 Tower kernel: ata6: SATA link down (SStatus 1 SControl 300) Feb 12 13:33:35 Tower kernel: ata6: limiting SATA link speed to 1.5 Gbps Feb 12 13:33:37 Tower kernel: ata6: SATA link down (SStatus 1 SControl 310) Feb 12 13:33:37 Tower kernel: ata6: limiting SATA link speed to 1.5 Gbps Feb 12 13:33:39 Tower kernel: ata6: SATA link down (SStatus 1 SControl 310) Feb 12 13:33:39 Tower kernel: ata6: limiting SATA link speed to 1.5 Gbps Feb 12 13:33:41 Tower kernel: ata6: SATA link down (SStatus 1 SControl 310) Feb 12 13:33:41 Tower kernel: ata6: limiting SATA link speed to 1.5 Gbps Feb 12 13:33:42 Tower kernel: ata6: SATA link up 1.5 Gbps (SStatus 113 SControl 310) Feb 12 13:33:43 Tower kernel: ata6.00: ATA-11: WDC WUH721816ALE6L4, PCGNW232, max UDMA/133 Feb 12 13:33:43 Tower kernel: ata6.00: 31251759104 sectors, multi 16: LBA48 NCQ (depth 32), AA Feb 12 13:33:43 Tower kernel: ata6.00: Features: NCQ-sndrcv NCQ-prio Feb 12 13:33:43 Tower kernel: ata6.00: configured for UDMA/133 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] 31251759104 512-byte logical blocks: (16.0 TB/14.6 TiB) Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] 4096-byte physical blocks Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] Write Protect is off Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] Mode Sense: 00 3a 00 00 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] Preferred minimum I/O size 4096 bytes Feb 12 13:33:43 Tower kernel: sdj: sdj1 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] Attached SCSI disk Feb 12 13:33:43 Tower kernel: ata6.00: exception Emask 0x10 SAct 0x1f0 SErr 0x280100 action 0x6 frozen Feb 12 13:33:43 Tower kernel: ata6.00: irq_stat 0x08000000, interface fatal error Feb 12 13:33:43 Tower kernel: ata6: SError: { UnrecovData 10B8B BadCRC } Feb 12 13:33:43 Tower kernel: ata6.00: failed command: READ FPDMA QUEUED Feb 12 13:33:43 Tower kernel: ata6.00: cmd 60/70:20:00:fe:bf/00:00:46:07:00/40 tag 4 ncq dma 57344 in Feb 12 13:33:43 Tower kernel: ata6.00: status: { DRDY } Feb 12 13:33:43 Tower kernel: ata6.00: failed command: READ FPDMA QUEUED Feb 12 13:33:43 Tower kernel: ata6.00: cmd 60/80:28:78:fe:bf/00:00:46:07:00/40 tag 5 ncq dma 65536 in Feb 12 13:33:43 Tower kernel: ata6.00: status: { DRDY } Feb 12 13:33:43 Tower kernel: ata6.00: failed command: READ FPDMA QUEUED Feb 12 13:33:43 Tower kernel: ata6.00: cmd 60/78:30:08:ff:bf/00:00:46:07:00/40 tag 6 ncq dma 61440 in Feb 12 13:33:43 Tower kernel: ata6.00: status: { DRDY } Feb 12 13:33:43 Tower kernel: ata6.00: failed command: READ FPDMA QUEUED Feb 12 13:33:43 Tower kernel: ata6.00: cmd 60/38:38:88:ff:bf/00:00:46:07:00/40 tag 7 ncq dma 28672 in Feb 12 13:33:43 Tower kernel: ata6.00: status: { DRDY } Feb 12 13:33:43 Tower kernel: ata6.00: failed command: READ FPDMA QUEUED Feb 12 13:33:43 Tower kernel: ata6.00: cmd 60/28:40:c8:ff:bf/00:00:46:07:00/40 tag 8 ncq dma 20480 in Feb 12 13:33:43 Tower kernel: ata6.00: status: { DRDY } Feb 12 13:33:43 Tower kernel: ata6: hard resetting link Feb 12 13:33:43 Tower kernel: ata6: SATA link up 1.5 Gbps (SStatus 113 SControl 310) Feb 12 13:33:43 Tower kernel: ata6.00: configured for UDMA/133 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#4 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#4 Sense Key : 0x5 [current] Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#4 ASC=0x21 ASCQ=0x4 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#4 CDB: opcode=0x88 88 00 00 00 00 07 46 bf fe 00 00 00 00 70 00 00 Feb 12 13:33:43 Tower kernel: I/O error, dev sdj, sector 31251758592 op 0x0:(READ) flags 0x80700 phys_seg 14 prio class 2 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#5 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#5 Sense Key : 0x5 [current] Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#5 ASC=0x21 ASCQ=0x4 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#5 CDB: opcode=0x88 88 00 00 00 00 07 46 bf fe 78 00 00 00 80 00 00 Feb 12 13:33:43 Tower kernel: I/O error, dev sdj, sector 31251758712 op 0x0:(READ) flags 0x80700 phys_seg 15 prio class 2 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#6 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#6 Sense Key : 0x5 [current] Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#6 ASC=0x21 ASCQ=0x4 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#6 CDB: opcode=0x88 88 00 00 00 00 07 46 bf ff 08 00 00 00 78 00 00 Feb 12 13:33:43 Tower kernel: I/O error, dev sdj, sector 31251758856 op 0x0:(READ) flags 0x80700 phys_seg 15 prio class 2 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#7 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#7 Sense Key : 0x5 [current] Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#7 ASC=0x21 ASCQ=0x4 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#7 CDB: opcode=0x88 88 00 00 00 00 07 46 bf ff 88 00 00 00 38 00 00 Feb 12 13:33:43 Tower kernel: I/O error, dev sdj, sector 31251758984 op 0x0:(READ) flags 0x80700 phys_seg 7 prio class 2 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#8 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=0s Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#8 Sense Key : 0x5 [current] Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#8 ASC=0x21 ASCQ=0x4 Feb 12 13:33:43 Tower kernel: sd 6:0:0:0: [sdj] tag#8 CDB: opcode=0x88 88 00 00 00 00 07 46 bf ff c8 00 00 00 28 00 00 Feb 12 13:33:43 Tower kernel: I/O error, dev sdj, sector 31251759048 op 0x0:(READ) flags 0x80700 phys_seg 5 prio class 2 Feb 12 13:33:43 Tower kernel: ata6: EH complete Feb 12 13:33:45 Tower unassigned.devices: Partition '/dev/sdj1' does not have a file system and cannot be mounted. Feb 13 09:54:29 Tower emhttpd: error: hotplug_devices, 1713: No such file or directory (2): tagged device WDC_WUH721816ALE6L4_2BJ90ZUN was (sdg) is now (sdj) Feb 13 09:54:29 Tower emhttpd: read SMART /dev/sdj
-
Hi All, I'm running Unraid 6.12.6 on an ASRock X570D4U with a 4650G Pro and 64GB ECC RAM. Sadly I woke up today to a disabled drive warning: I had a look in my syslog and found these errors: Feb 13 00:00:06 Tower Plugin Auto Update: Community Applications Plugin Auto Update finished Feb 13 04:00:26 Tower kernel: md: disk29 read error, sector=3907594640 Feb 13 04:00:26 Tower emhttpd: read SMART /dev/sdh Feb 13 04:00:26 Tower emhttpd: read SMART /dev/sdf Feb 13 04:00:38 Tower emhttpd: read SMART /dev/sdd Feb 13 04:00:38 Tower emhttpd: read SMART /dev/sde Feb 13 04:00:38 Tower emhttpd: read SMART /dev/sdb Feb 13 04:00:38 Tower emhttpd: read SMART /dev/sdc Feb 13 04:00:38 Tower emhttpd: read SMART /dev/sdi Feb 13 04:00:49 Tower kernel: md: disk29 write error, sector=3907594640 Feb 13 04:01:01 Tower sSMTP[12879]: Creating SSL connection to host Feb 13 04:01:01 Tower sSMTP[12879]: SSL connection using TLS_AES_256_GCM_SHA384 Feb 13 04:01:04 Tower sSMTP[12879]: Sent mail for [censored] (221 2.0.0 closing connection y12-20020a056000108c00b0033b40a3f92asm8358077wrw.25 - gsmtp) uid=0 username=root outbytes=770 Feb 13 04:02:26 Tower root: /etc/libvirt: 125.7 MiB (131817472 bytes) trimmed on /dev/loop3 Feb 13 04:02:26 Tower root: /var/lib/docker: 3.7 GiB (3952398336 bytes) trimmed on /dev/loop2 Feb 13 04:02:26 Tower root: /mnt/cache: 314.3 GiB (337479950336 bytes) trimmed on /dev/mapper/nvme1n1p1 Feb 13 04:30:39 Tower emhttpd: spinning down /dev/sdd Feb 13 04:30:39 Tower emhttpd: spinning down /dev/sde Feb 13 04:30:39 Tower emhttpd: spinning down /dev/sdb Feb 13 04:30:39 Tower emhttpd: spinning down /dev/sdc Feb 13 04:30:39 Tower emhttpd: spinning down /dev/sdi Feb 13 04:30:58 Tower emhttpd: spinning down /dev/sdh Feb 13 04:30:58 Tower emhttpd: spinning down /dev/sdf Feb 13 09:00:11 Tower emhttpd: read SMART /dev/sdh Feb 13 09:00:21 Tower emhttpd: read SMART /dev/sdd Feb 13 09:27:31 Tower emhttpd: read SMART /dev/sdc Feb 13 09:28:00 Tower emhttpd: read SMART /dev/sdi Feb 13 09:28:13 Tower emhttpd: read SMART /dev/sdb Feb 13 09:30:30 Tower emhttpd: spinning down /dev/sdh Feb 13 09:54:28 Tower webGUI: Successful login user root from 192.168.1.175 Feb 13 09:54:29 Tower emhttpd: error: hotplug_devices, 1713: No such file or directory (2): tagged device WDC_WUH721816ALE6L4_2BJ90ZUN was (sdg) is now (sdj) Feb 13 09:54:29 Tower emhttpd: read SMART /dev/sdj Feb 13 09:54:29 Tower kernel: emhttpd[6175]: segfault at 67c ip 000055776d0f197b sp 00007ffc12d22d60 error 4 in emhttpd[55776d0dc000+25000] likely on CPU 11 (core 6, socket 0) Feb 13 09:54:29 Tower kernel: Code: e0 44 01 00 48 89 45 f8 48 8d 05 05 32 01 00 48 89 45 f0 e9 79 01 00 00 8b 45 ec 89 c7 e8 eb 87 ff ff 48 89 45 d8 48 8b 45 d8 <8b> 80 7c 06 00 00 85 c0 0f 94 c0 0f b6 c0 89 45 d4 48 8b 45 e0 48 Nobody else in the house, so aside from the potential of some unwanted rodent guests (I hope not) there is nobody who could have touched the server. For some reason, I now can't stop the array. Diags attached, can anyone help me understand what's happened and/or what I need to do? Really hoping this isnt an actual drive fault as these suckers aint cheap. Thanks, tower-diagnostics-20240213-1002.zip
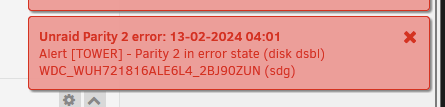
-
I managed to get the board alive again through what seems to be nothing but sheer luck, however I didn't get to the bottom of why there is constant crashes. I just bit the bullet and bought new hardware. Now running Intel and Supermicro and it's been flawless. Despite the lack of Memtest reported failures, I'm inclined to lean towards it being a Memory issue, slight possibility there is something wrong with the 4650G CPU or UEFI settings.
-
So on the one hand, I ran the 4 pass memtest with ECC polling enabled twice and no errors... so dont think it's that. On the other hand, the ASRock Rack support team supplied me with some SOC flash tools, but they don't recognise the BMC image to fix my IPMI.
-
I got it to finally boot the Memtest USB drive but somehow in the process I have bricked my IPMI 😄 It's been like this since my last post pretty much Seriously f**k this motherboard.
-
Man, no matter what I do, this motherboard will not boot from an EFI based USB image. Ended up having to clear my CMOS as I fiddled with so many things I eventually couldn't get it to post at all.
-
I honestly cant remember how I tested it, but good shout. No harm in running it again.
-
The PSU is pretty new, and its a decent unit (Corsair TX850M). I could swap in my older CS450M though, that ran for years without fault so it would at least one of the variables removed. IPMI is also of absolutely no help and isn't reporting any issues other than clock sync, but it also isn't dropping out when the sever drops out which probably suggests there isnt a significant power issue. I have grabbed the debug logs from there. Some errors around the same time as the reboot but they don't, IMO, point to anything useful... bit beyond my expertise at this point The issue with tracing the individual components is that I have fiddled with settings previously, thinking I had figured out the problem (e.g. RAM settings/voltage, CPU settings, GPU settings), and then had the system stable for literally months with no crashes or reboots, so then I presume it is ok until it randomly happens again. At the moment it appears to be totally borked at exactly the wrong moment. I'm at breaking point tbh, I need this server to run at some capacity. I think im going to pick up an v6 E3 Xeon and supporting board from Ebay then I can experiment with this X570 and get to the bottom of its issues as a separate project (yipee). Might even just sell the board on and/or discuss with the retailer if it looks like there is a problem with it. var.zip
-
Definitely. This I am already pretty sure of, but I was hoping there would be an indicator here as to what is. I have run memtest for a few days when installing this so I have no clue where the hardware issues are coming from.
-
Extended parity check on that disk came back ok. I decided that I have more trust in the disks data than the parity, given I saw the disks writing data to the parity when one of the disks was disabled, so I created a new config and tried to build a new parity, but It didn't make it. Sadly I don't think my remote syslog helps us but grateful for any feedback. unraid_155.zip tower-diagnostics-20230314-0942.zip
-
I should probably point out the reason the log is wiped is because the server rebooted itself when i stopped the array. Guess I will have to have a think. About ready to chuck this POS motherboard in the bin, never had as many issues as this with my Supermicro Intel systems.
-
I was concerned that might be a problem. A couple of questions for moving forward: 1. Is there anything other than an external syslog server that can help me trace my reboots? 2. Is there anything I can do to test the validity of the data on my array? 3. How do I see where the "fail" flag is and "acknowledge" it so the array can be started with this disk? Due to the power failure and subsequent failed parity check, I am genuinely not confident in my parity data to rebuild the array from.
-
Hi all, I have been wresting with this server since I built it with "random" reboots and a whole host of other annoying issues. Starting to get worried about my data now tbh. Specs: ASRock Rack X570-D4U AMD Ryzen 5 PRO 4650G 2x 32GB DDR4 ECC Unbuffered RAM NVidia T400 I had a powercut this morning and it of course co-coincided with me having my UPS offline due to a battery replacement... typical. Just to double up on my misfortune, I had also made a mistake in a .conf file whilst setting up an external rsyslog server to help me trace the issue at the root of my general server issues so after all the effort, I didn't even get any off-board log data... typical. I have been suspicious that the problems could be related to the chipset on the motherboard so as a troubleshooting measure I installed an LSI 9211-8i which is connected via SAS cables to a SAS backplate. The power cut of course means I had to run a parity check. While it was running (probably didn't make it to 10%) I got an email from the server saying there was a disk error. When I logged in, I noticed that drive was disabled, and all the other drives had read errors. Out of panic, I just stopped the parity check as I noticed that I had left on "write corrections" and was concerned I would going to be writing garbage to my array. I have no idea where I stand at the moment, so open to suggestions to check my data and/or test my hardware. I have run a short SMART test, and am currently running an extended test of the drive that unraid says has failed. I also ordered a replacement drive which will arrive tomorrow, although I'm not actually think there is anything wrong with it. Diagnostics attached. tower-diagnostics-20230313-1415.zip
-
I'll also check that tomorrow, but I seem to recall doing this in the past already. I have a 1TB cash/appdata drive so figured I could crank it up to never worry about it. Changing the share split level certainly helped with the files from my laptop, just got to check the ones on my workstation from the first errors I posted.
-
There is 700+GB free for app data.... so that doesn't really make sense. I have some warnings on my server that it was getting full last night, but the mover sorted that out (as per it's parameters) in the early morning hours. I had a look at the allocation of data though, and it does seem like data isn't spreading across the disks very evenly. Split level for nextcloud was only 2, which I would have thought would be ok but a bit deeper digging seems like it might not have been. I have changed the split settings for the Nextcloud share up to 3 levels, I'll see if this fixes all my problems and report back.
-
Can anyone point me in the right direction with this? Im not getting more and more things that refuse to sync with nextcloud and im a bit baffled as to what I have done or what I need to do.... this is the new one... what's going on? Fatal webdav Sabre\DAV\Exception: Error while copying file to target location (copied bytes: 0, expected filesize: 97280 ) 2020-04-25T16:35:48+0100 Error no app in context Sabre\DAV\Exception: Error while copying file to target location (copied bytes: 0, expected filesize: 97280 ) 2020-04-25T16:35:48+0100 Error PHP file_put_contents(/data/paul/files/Software/Axon/ISSetupPrerequisites/Microsoft SQL Server 2014 Express RTM/SQLEXPR_x86_ENU/1033_ENU_LP/x86/Setup/sqlsupport_msi/Windows/system32/RWFVLHTQ.LM8.ocTransferId1925991769.part): failed to open stream: No space left on device at /config/www/nextcloud/lib/private/Files/Storage/Local.php#503
-
Hi Guys, I'm having an issue that I would really like to solve myself... but struggling to do so. I'm getting an error when trying to copy large files from my desktop (anything 3GB or larger it seems) and the files simply refuse to sync. In the windows application I see: [file location]: Connection Closed Then then when I log into the nextcloud control panel and look at the logging I see a whole string of fatal errors such as: [webdav] Fatal: Sabre\DAV\Exception: Error while copying file to target location (copied bytes: 0, expected filesize: 100000000 ) at <<closure>> 0. /config/www/nextcloud/apps/dav/lib/Connector/Sabre/Directory.php line 156 OCA\DAV\Connector\Sabre\File->put(null) 1. /config/www/nextcloud/apps/dav/lib/Upload/UploadFolder.php line 47 OCA\DAV\Connector\Sabre\Directory->createFile("00000012", null) 2. /config/www/nextcloud/3rdparty/sabre/dav/lib/DAV/Server.php line 1096 OCA\DAV\Upload\UploadFolder->createFile("00000012", null) 3. /config/www/nextcloud/3rdparty/sabre/dav/lib/DAV/CorePlugin.php line 525 Sabre\DAV\Server->createFile("uploads/paul/2178915309/00000012", null, null) 4. <<closure>> Sabre\DAV\CorePlugin->httpPut(Sabre\HTTP\Reque ... "}, Sabre\HTTP\Response {}) 5. /config/www/nextcloud/3rdparty/sabre/event/lib/EventEmitterTrait.php line 105 call_user_func_array([Sabre\DAV\CorePlugin {},"httpPut"], [Sabre\HTTP\Requ ... }]) 6. /config/www/nextcloud/3rdparty/sabre/dav/lib/DAV/Server.php line 479 Sabre\Event\EventEmitter->emit("method:PUT", [Sabre\HTTP\Requ ... }]) 7. /config/www/nextcloud/3rdparty/sabre/dav/lib/DAV/Server.php line 254 Sabre\DAV\Server->invokeMethod(Sabre\HTTP\Reque ... "}, Sabre\HTTP\Response {}) 8. /config/www/nextcloud/apps/dav/lib/Server.php line 319 Sabre\DAV\Server->exec() 9. /config/www/nextcloud/apps/dav/appinfo/v2/remote.php line 35 OCA\DAV\Server->exec() 10. /config/www/nextcloud/remote.php line 165 require_once("/config/www/nex ... p") PUT /remote.php/dav/uploads/paul/2178915309/00000012 from [removed] by paul at 2020-04-04T17:45:56+00:00 A bit of googling has lead me to believe this is related to a PHP config, but I can't for the life of me figure out where the config file is that I should be changing. Everything in the server is up to date, as far as I am aware. I'm using Nextcloud along with LetsEncrypt and MariaDB. Is it a file in LetsEncrypt that I should be adjusting?
-
Yeah I was actually using the VPN docker but didn't realise I was in the wrong thread.




